 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePick the Largest Margin for Robust Detection of Splicing
Paper and Code
Sep 05, 2024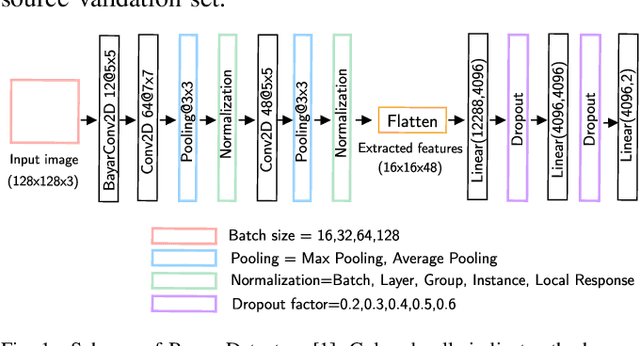
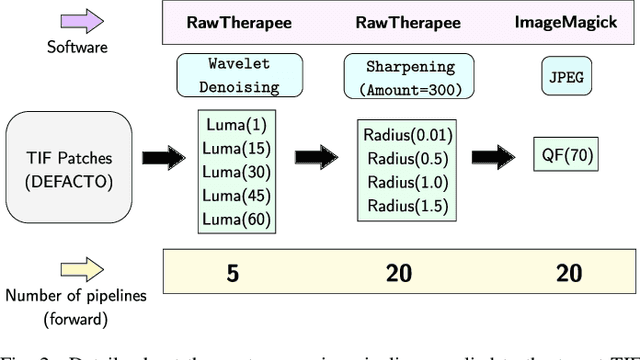
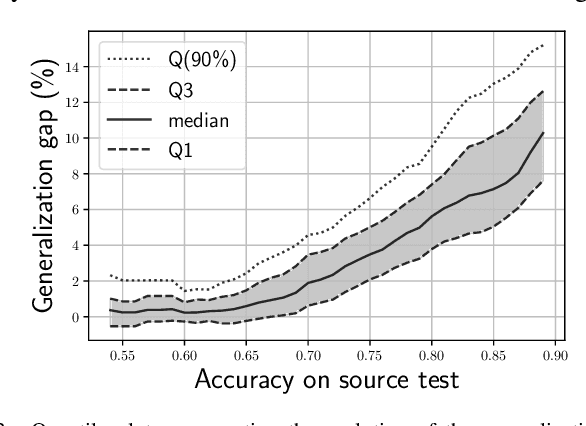
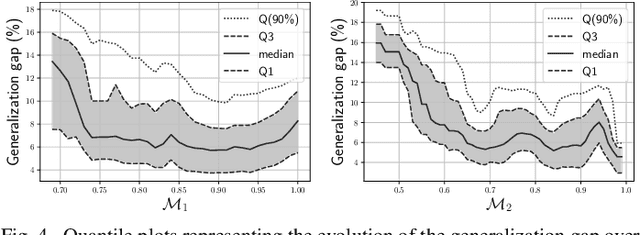
Despite advancements in splicing detection, practitioners still struggle to fully leverage forensic tools from the literature due to a critical issue: deep learning-based detectors are extremely sensitive to their trained instances. Simple post-processing applied to evaluation images can easily decrease their performances, leading to a lack of confidence in splicing detectors for operational contexts. In this study, we show that a deep splicing detector behaves differently against unknown post-processes for different learned weights, even if it achieves similar performances on a test set from the same distribution as its training one. We connect this observation to the fact that different learnings create different latent spaces separating training samples differently. Our experiments reveal a strong correlation between the distributions of latent margins and the ability of the detector to generalize to post-processed images. We thus provide to the practitioner a way to build deep detectors that are more robust than others against post-processing operations, suggesting to train their architecture under different conditions and picking the one maximizing the latent space margin.