 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePick the Largest Margin for Robust Detection of Splicing
Sep 05, 2024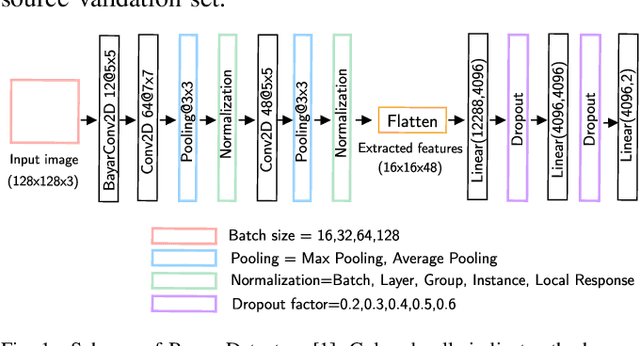
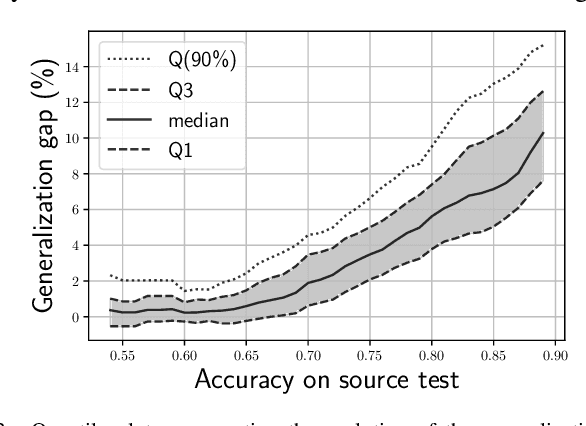
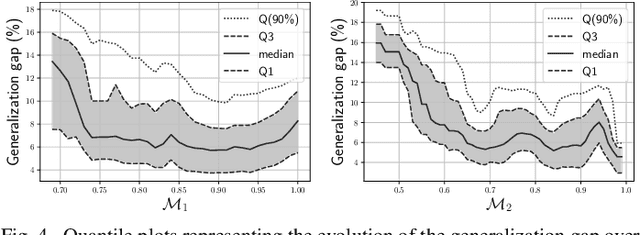
Despite advancements in splicing detection, practitioners still struggle to fully leverage forensic tools from the literature due to a critical issue: deep learning-based detectors are extremely sensitive to their trained instances. Simple post-processing applied to evaluation images can easily decrease their performances, leading to a lack of confidence in splicing detectors for operational contexts. In this study, we show that a deep splicing detector behaves differently against unknown post-processes for different learned weights, even if it achieves similar performances on a test set from the same distribution as its training one. We connect this observation to the fact that different learnings create different latent spaces separating training samples differently. Our experiments reveal a strong correlation between the distributions of latent margins and the ability of the detector to generalize to post-processed images. We thus provide to the practitioner a way to build deep detectors that are more robust than others against post-processing operations, suggesting to train their architecture under different conditions and picking the one maximizing the latent space margin.
Blind Data Adaptation to tackle Covariate Shift in Operational Steganalysis
May 29, 2024



The proliferation of image manipulation for unethical purposes poses significant challenges in social networks. One particularly concerning method is Image Steganography, allowing individuals to hide illegal information in digital images without arousing suspicions. Such a technique pose severe security risks, making it crucial to develop effective steganalysis methods enabling to detect manipulated images for clandestine communications. Although significant advancements have been achieved with machine learning models, a critical issue remains: the disparity between the controlled datasets used to train steganalysis models against real-world datasets of forensic practitioners, undermining severely the practical effectiveness of standardized steganalysis models. In this paper, we address this issue focusing on a realistic scenario where practitioners lack crucial information about the limited target set of images under analysis, including details about their development process and even whereas it contains manipulated images or not. By leveraging geometric alignment and distribution matching of source and target residuals, we develop TADA (Target Alignment through Data Adaptation), a novel methodology enabling to emulate sources aligned with specific targets in steganalysis, which is also relevant for highly unbalanced targets. The emulator is represented by a light convolutional network trained to align distributions of image residuals. Experimental validation demonstrates the potential of our strategy over traditional methods fighting covariate shift in steganalysis.
Leveraging Data Geometry to Mitigate CSM in Steganalysis
Oct 06, 2023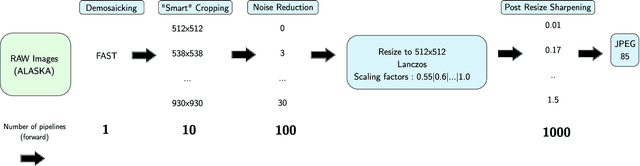
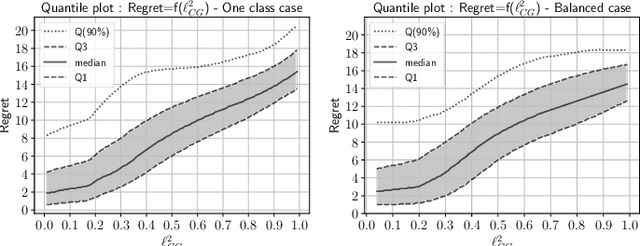
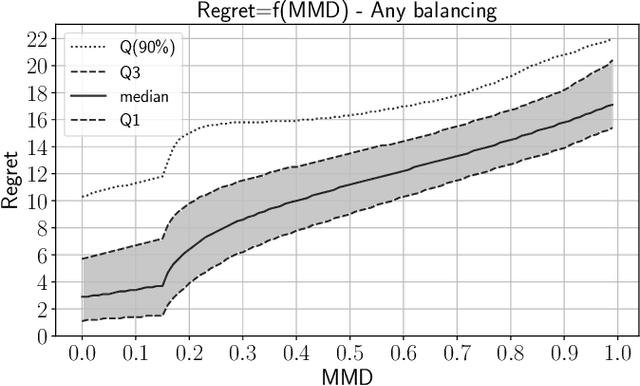
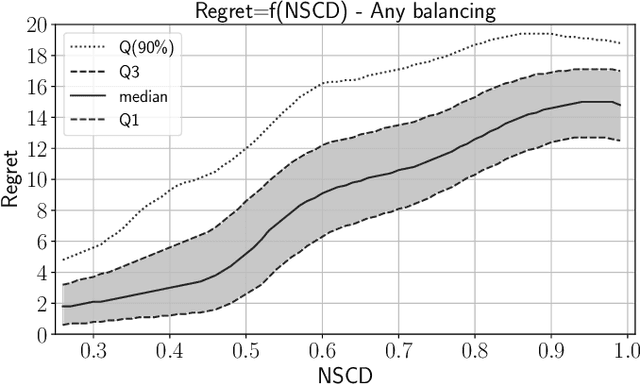
In operational scenarios, steganographers use sets of covers from various sensors and processing pipelines that differ significantly from those used by researchers to train steganalysis models. This leads to an inevitable performance gap when dealing with out-of-distribution covers, commonly referred to as Cover Source Mismatch (CSM). In this study, we consider the scenario where test images are processed using the same pipeline. However, knowledge regarding both the labels and the balance between cover and stego is missing. Our objective is to identify a training dataset that allows for maximum generalization to our target. By exploring a grid of processing pipelines fostering CSM, we discovered a geometrical metric based on the chordal distance between subspaces spanned by DCTr features, that exhibits high correlation with operational regret while being not affected by the cover-stego balance. Our contribution lies in the development of a strategy that enables the selection or derivation of customized training datasets, enhancing the overall generalization performance for a given target. Experimental validation highlights that our geometry-based optimization strategy outperforms traditional atomistic methods given reasonable assumptions. Additional resources are available at github.com/RonyAbecidan/LeveragingGeometrytoMitigateCSM.
Using Set Covering to Generate Databases for Holistic Steganalysis
Nov 07, 2022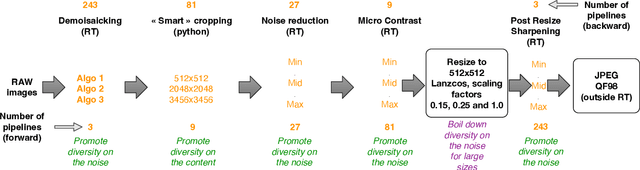
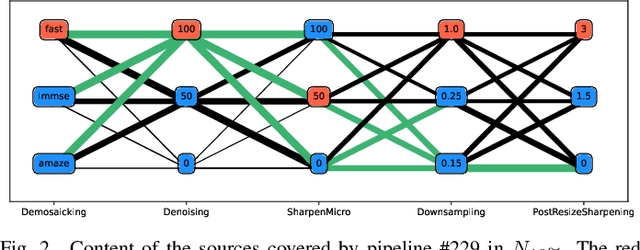
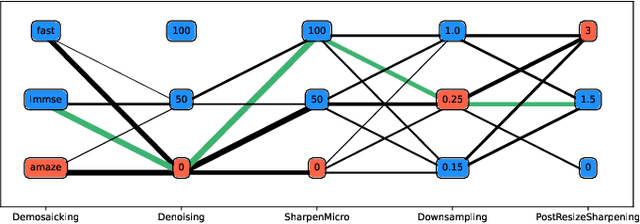
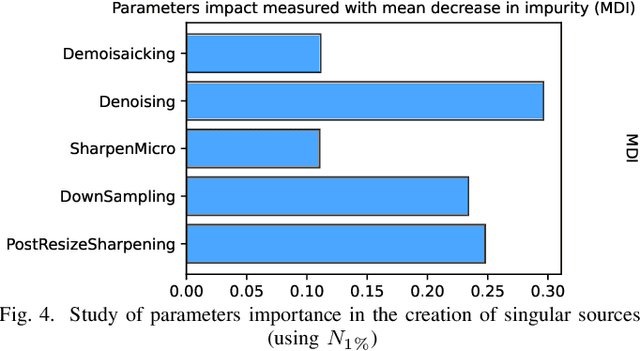
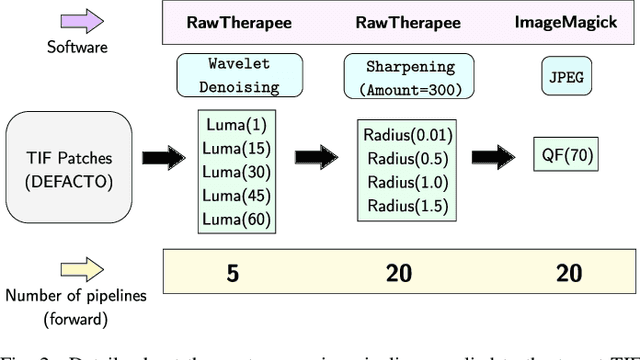
Within an operational framework, covers used by a steganographer are likely to come from different sensors and different processing pipelines than the ones used by researchers for training their steganalysis models. Thus, a performance gap is unavoidable when it comes to out-of-distributions covers, an extremely frequent scenario called Cover Source Mismatch (CSM). Here, we explore a grid of processing pipelines to study the origins of CSM, to better understand it, and to better tackle it. A set-covering greedy algorithm is used to select representative pipelines minimizing the maximum regret between the representative and the pipelines within the set. Our main contribution is a methodology for generating relevant bases able to tackle operational CSM. Experimental validation highlights that, for a given number of training samples, our set covering selection is a better strategy than selecting random pipelines or using all the available pipelines. Our analysis also shows that parameters as denoising, sharpening, and downsampling are very important to foster diversity. Finally, different benchmarks for classical and wild databases show the good generalization property of the extracted databases. Additional resources are available at github.com/RonyAbecidan/HolisticSteganalysisWithSetCovering.