 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Set Covering to Generate Databases for Holistic Steganalysis
Paper and Code
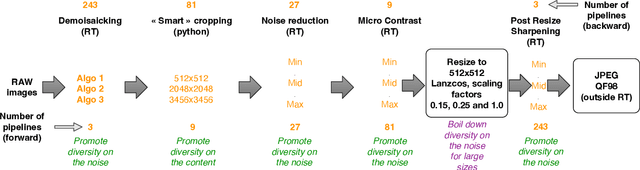
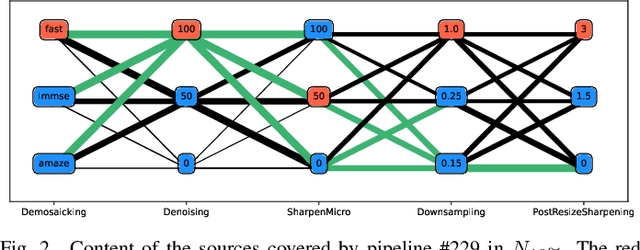
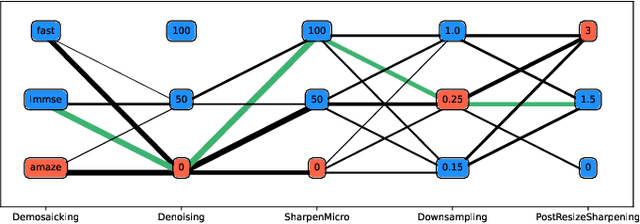
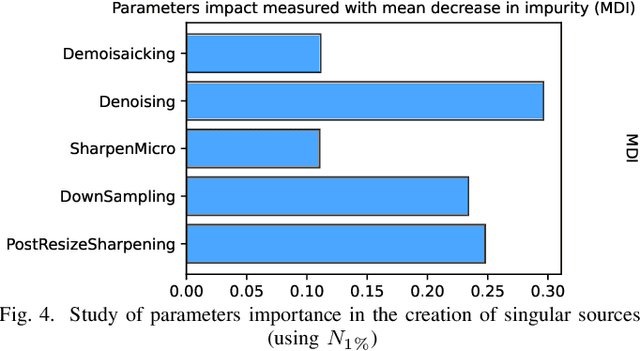
Within an operational framework, covers used by a steganographer are likely to come from different sensors and different processing pipelines than the ones used by researchers for training their steganalysis models. Thus, a performance gap is unavoidable when it comes to out-of-distributions covers, an extremely frequent scenario called Cover Source Mismatch (CSM). Here, we explore a grid of processing pipelines to study the origins of CSM, to better understand it, and to better tackle it. A set-covering greedy algorithm is used to select representative pipelines minimizing the maximum regret between the representative and the pipelines within the set. Our main contribution is a methodology for generating relevant bases able to tackle operational CSM. Experimental validation highlights that, for a given number of training samples, our set covering selection is a better strategy than selecting random pipelines or using all the available pipelines. Our analysis also shows that parameters as denoising, sharpening, and downsampling are very important to foster diversity. Finally, different benchmarks for classical and wild databases show the good generalization property of the extracted databases. Additional resources are available at github.com/RonyAbecidan/HolisticSteganalysisWithSetCovering.