 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEMSS: A Variational Bayesian Method for Discovering Multiple Sparse Solutions in Classification and Regression Problems
Feb 09, 2026Selecting interpretable feature sets in underdetermined ($n \ll p$) and highly correlated regimes constitutes a fundamental challenge in data science, particularly when analyzing physical measurements. In such settings, multiple distinct sparse subsets may explain the response equally well. Identifying these alternatives is crucial for generating domain-specific insights into the underlying mechanisms, yet conventional methods typically isolate a single solution, obscuring the full spectrum of plausible explanations. We present GEMSS (Gaussian Ensemble for Multiple Sparse Solutions), a variational Bayesian framework specifically designed to simultaneously discover multiple, diverse sparse feature combinations. The method employs a structured spike-and-slab prior for sparsity, a mixture of Gaussians to approximate the intractable multimodal posterior, and a Jaccard-based penalty to further control solution diversity. Unlike sequential greedy approaches, GEMSS optimizes the entire ensemble of solutions within a single objective function via stochastic gradient descent. The method is validated on a comprehensive benchmark comprising 128 synthetic experiments across classification and regression tasks. Results demonstrate that GEMSS scales effectively to high-dimensional settings ($p=5000$) with sample size as small as $n = 50$, generalizes seamlessly to continuous targets, handles missing data natively, and exhibits remarkable robustness to class imbalance and Gaussian noise. GEMSS is available as a Python package 'gemss' at PyPI. The full GitHub repository at https://github.com/kat-er-ina/gemss/ also includes a free, easy-to-use application suitable for non-coders.
Sparse Probabilistic Graph Circuits
Aug 11, 2025Deep generative models (DGMs) for graphs achieve impressively high expressive power thanks to very efficient and scalable neural networks. However, these networks contain non-linearities that prevent analytical computation of many standard probabilistic inference queries, i.e., these DGMs are considered \emph{intractable}. While recently proposed Probabilistic Graph Circuits (PGCs) address this issue by enabling \emph{tractable} probabilistic inference, they operate on dense graph representations with $\mathcal{O}(n^2)$ complexity for graphs with $n$ nodes and \emph{$m$ edges}. To address this scalability issue, we introduce Sparse PGCs, a new class of tractable generative models that operate directly on sparse graph representation, reducing the complexity to $\mathcal{O}(n + m)$, which is particularly beneficial for $m \ll n^2$. In the context of de novo drug design, we empirically demonstrate that SPGCs retain exact inference capabilities, improve memory efficiency and inference speed, and match the performance of intractable DGMs in key metrics.
Probabilistic Graph Circuits: Deep Generative Models for Tractable Probabilistic Inference over Graphs
Mar 15, 2025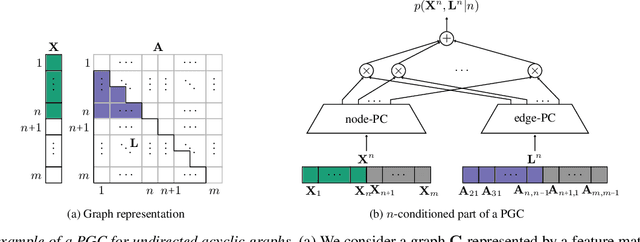
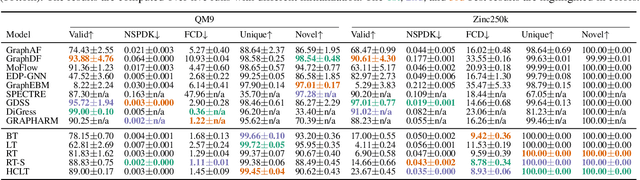
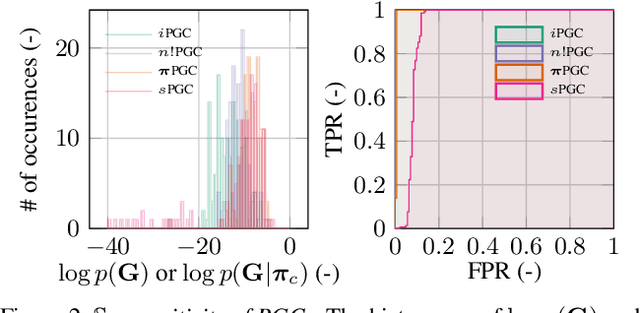
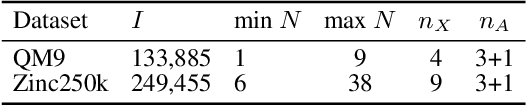
Deep generative models (DGMs) have recently demonstrated remarkable success in capturing complex probability distributions over graphs. Although their excellent performance is attributed to powerful and scalable deep neural networks, it is, at the same time, exactly the presence of these highly non-linear transformations that makes DGMs intractable. Indeed, despite representing probability distributions, intractable DGMs deny probabilistic foundations by their inability to answer even the most basic inference queries without approximations or design choices specific to a very narrow range of queries. To address this limitation, we propose probabilistic graph circuits (PGCs), a framework of tractable DGMs that provide exact and efficient probabilistic inference over (arbitrary parts of) graphs. Nonetheless, achieving both exactness and efficiency is challenging in the permutation-invariant setting of graphs. We design PGCs that are inherently invariant and satisfy these two requirements, yet at the cost of low expressive power. Therefore, we investigate two alternative strategies to achieve the invariance: the first sacrifices the efficiency, and the second sacrifices the exactness. We demonstrate that ignoring the permutation invariance can have severe consequences in anomaly detection, and that the latter approach is competitive with, and sometimes better than, existing intractable DGMs in the context of molecular graph generation.
Sum-Product-Set Networks: Deep Tractable Models for Tree-Structured Graphs
Aug 18, 2024
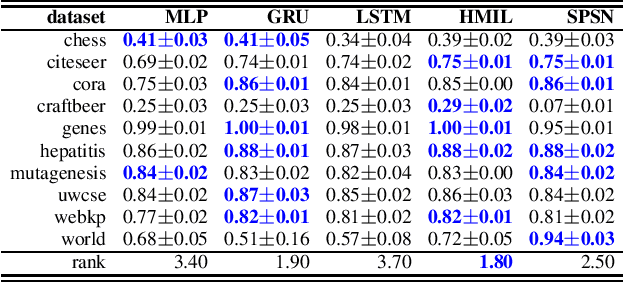

Daily internet communication relies heavily on tree-structured graphs, embodied by popular data formats such as XML and JSON. However, many recent generative (probabilistic) models utilize neural networks to learn a probability distribution over undirected cyclic graphs. This assumption of a generic graph structure brings various computational challenges, and, more importantly, the presence of non-linearities in neural networks does not permit tractable probabilistic inference. We address these problems by proposing sum-product-set networks, an extension of probabilistic circuits from unstructured tensor data to tree-structured graph data. To this end, we use random finite sets to reflect a variable number of nodes and edges in the graph and to allow for exact and efficient inference. We demonstrate that our tractable model performs comparably to various intractable models based on neural networks.
GraphSPNs: Sum-Product Networks Benefit From Canonical Orderings
Aug 18, 2024Deep generative models have recently made a remarkable progress in capturing complex probability distributions over graphs. However, they are intractable and thus unable to answer even the most basic probabilistic inference queries without resorting to approximations. Therefore, we propose graph sum-product networks (GraphSPNs), a tractable deep generative model which provides exact and efficient inference over (arbitrary parts of) graphs. We investigate different principles to make SPNs permutation invariant. We demonstrate that GraphSPNs are able to (conditionally) generate novel and chemically valid molecular graphs, being competitive to, and sometimes even better than, existing intractable models. We find out that (Graph)SPNs benefit from ensuring the permutation invariance via canonical ordering.
Sum-Product-Set Networks
Aug 14, 2024Daily internet communication relies heavily on tree-structured graphs, embodied by popular data formats such as XML and JSON. However, many recent generative (probabilistic) models utilize neural networks to learn a probability distribution over undirected cyclic graphs. This assumption of a generic graph structure brings various computational challenges, and, more importantly, the presence of non-linearities in neural networks does not permit tractable probabilistic inference. We address these problems by proposing sum-product-set networks, an extension of probabilistic circuits from unstructured tensor data to tree-structured graph data. To this end, we use random finite sets to reflect a variable number of nodes and edges in the graph and to allow for exact and efficient inference. We demonstrate that our tractable model performs comparably to various intractable models based on neural networks.
Is AUC the best measure for practical comparison of anomaly detectors?
May 08, 2023The area under receiver operating characteristics (AUC) is the standard measure for comparison of anomaly detectors. Its advantage is in providing a scalar number that allows a natural ordering and is independent on a threshold, which allows to postpone the choice. In this work, we question whether AUC is a good metric for anomaly detection, or if it gives a false sense of comfort, due to relying on assumptions which are unlikely to hold in practice. Our investigation shows that variations of AUC emphasizing accuracy at low false positive rate seem to be better correlated with the needs of practitioners, but also that we can compare anomaly detectors only in the case when we have representative examples of anomalous samples. This last result is disturbing, as it suggests that in many cases, we should do active or few-show learning instead of pure anomaly detection.
Fitting large mixture models using stochastic component selection
Oct 10, 2021
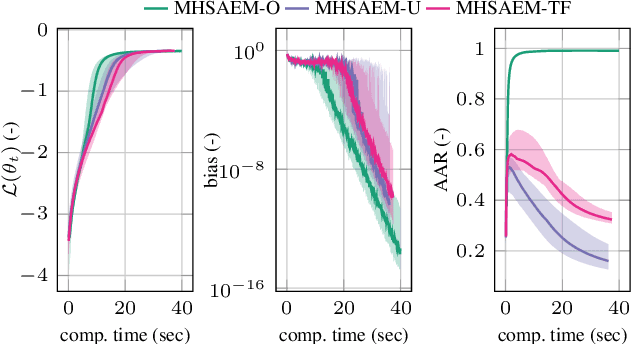
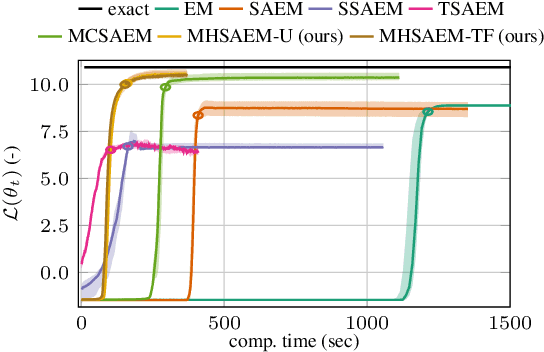
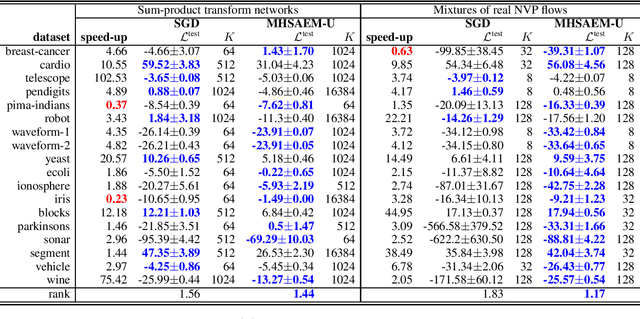
Traditional methods for unsupervised learning of finite mixture models require to evaluate the likelihood of all components of the mixture. This becomes computationally prohibitive when the number of components is large, as it is, for example, in the sum-product (transform) networks. Therefore, we propose to apply a combination of the expectation maximization and the Metropolis-Hastings algorithm to evaluate only a small number of, stochastically sampled, components, thus substantially reducing the computational cost. The Markov chain of component assignments is sequentially generated across the algorithm's iterations, having a non-stationary target distribution whose parameters vary via a gradient-descent scheme. We put emphasis on generality of our method, equipping it with the ability to train both shallow and deep mixture models which involve complex, and possibly nonlinear, transformations. The performance of our method is illustrated in a variety of synthetic and real-data contexts, considering deep models, such as mixtures of normalizing flows and sum-product (transform) networks.
Comparison of Anomaly Detectors: Context Matters
Dec 18, 2020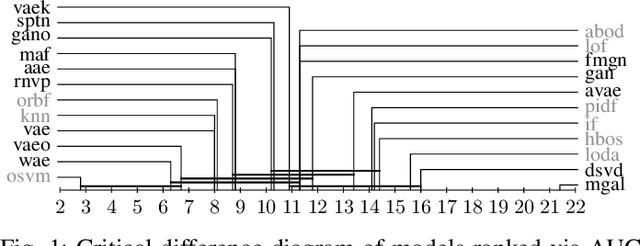
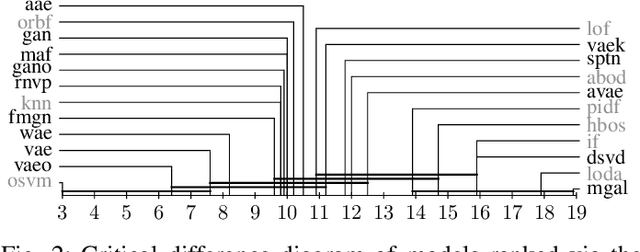
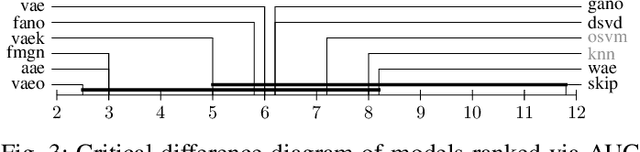
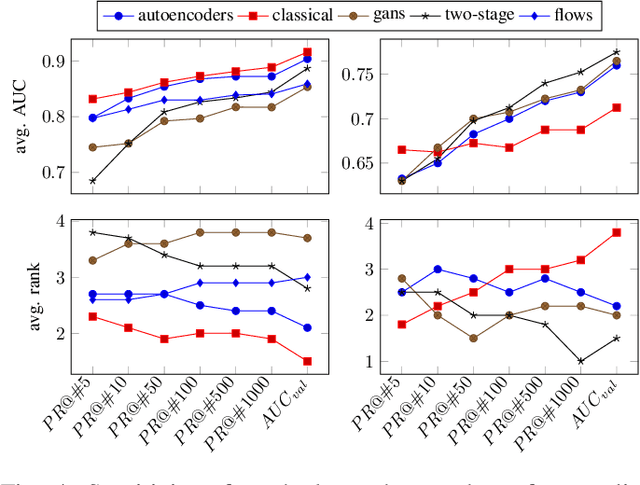
Deep generative models are challenging the classical methods in the field of anomaly detection nowadays. Every new method provides evidence of outperforming its predecessors, often with contradictory results. The objective of this comparison is twofold: comparison of anomaly detection methods of various paradigms, and identification of sources of variability that can yield different results. The methods were compared on popular tabular and image datasets. While the one class support-vector machine (OC-SVM) had no rival on the tabular datasets, the best results on the image data were obtained either by a feature-matching GAN or a combination of variational autoencoder (VAE) and OC-SVM, depending on the experimental conditions. The main sources of variability that can influence the performance of the methods were identified to be: the range of searched hyper-parameters, the methodology of model selection, and the choice of the anomalous samples. All our code and results are available for download.
DeepTopPush: Simple and Scalable Method for Accuracy at the Top
Jun 22, 2020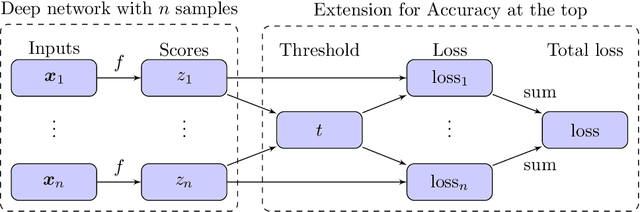
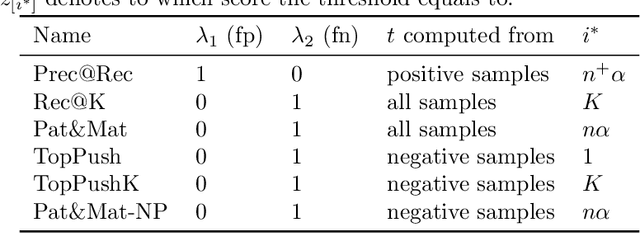
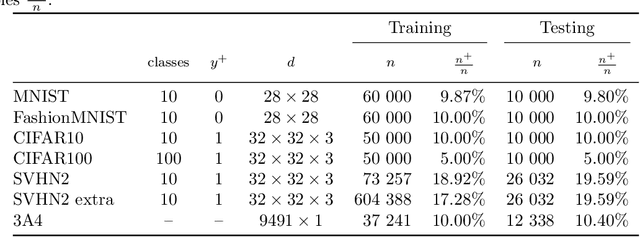
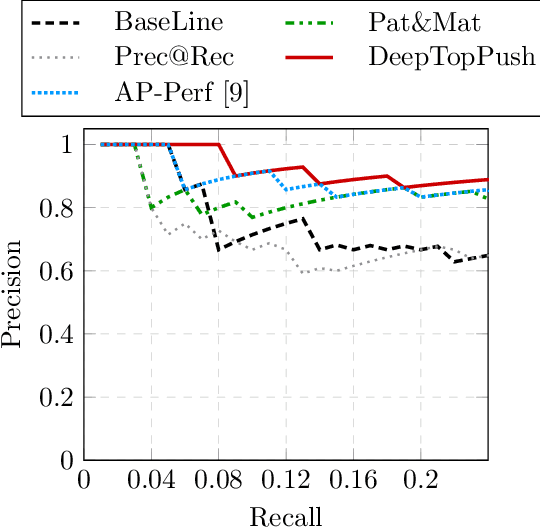
Accuracy at the top is a special class of binary classification problems where the performance is evaluated only on a small number of relevant (top) samples. Applications include information retrieval systems or processes with manual (expensive) postprocessing. This leads to the minimization of irrelevant samples above a threshold. We consider classifiers in the form of an arbitrary (deep) network and propose a new method DeepTopPush for minimizing the top loss function. Since the threshold depends on all samples, the problem is non-decomposable. We modify the stochastic gradient descent to handle the non-decomposability in an end-to-end training manner and propose a way to estimate the threshold only from values on the current minibatch. We demonstrate the good performance of DeepTopPush on visual recognition datasets and on a real-world application of selecting a small number of molecules for further drug testing.