 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs AUC the best measure for practical comparison of anomaly detectors?
May 08, 2023The area under receiver operating characteristics (AUC) is the standard measure for comparison of anomaly detectors. Its advantage is in providing a scalar number that allows a natural ordering and is independent on a threshold, which allows to postpone the choice. In this work, we question whether AUC is a good metric for anomaly detection, or if it gives a false sense of comfort, due to relying on assumptions which are unlikely to hold in practice. Our investigation shows that variations of AUC emphasizing accuracy at low false positive rate seem to be better correlated with the needs of practitioners, but also that we can compare anomaly detectors only in the case when we have representative examples of anomalous samples. This last result is disturbing, as it suggests that in many cases, we should do active or few-show learning instead of pure anomaly detection.
Comparison of Anomaly Detectors: Context Matters
Dec 18, 2020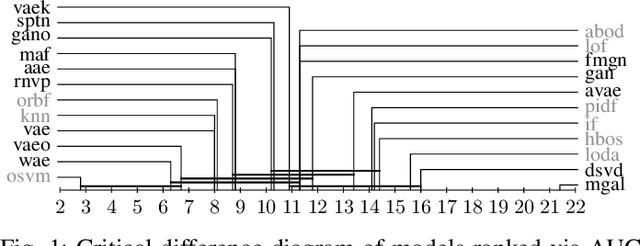
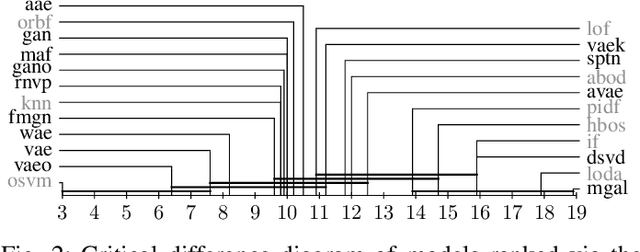
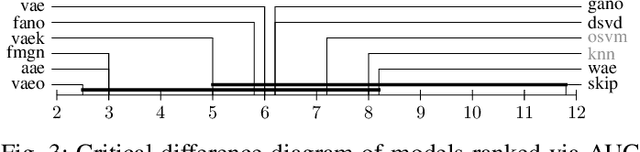
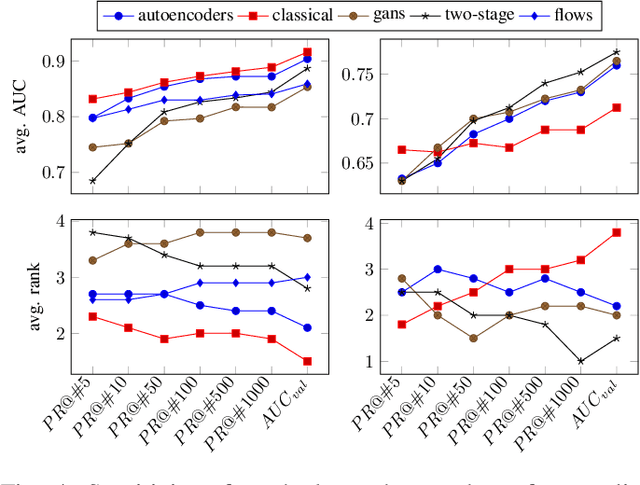
Deep generative models are challenging the classical methods in the field of anomaly detection nowadays. Every new method provides evidence of outperforming its predecessors, often with contradictory results. The objective of this comparison is twofold: comparison of anomaly detection methods of various paradigms, and identification of sources of variability that can yield different results. The methods were compared on popular tabular and image datasets. While the one class support-vector machine (OC-SVM) had no rival on the tabular datasets, the best results on the image data were obtained either by a feature-matching GAN or a combination of variational autoencoder (VAE) and OC-SVM, depending on the experimental conditions. The main sources of variability that can influence the performance of the methods were identified to be: the range of searched hyper-parameters, the methodology of model selection, and the choice of the anomalous samples. All our code and results are available for download.
Are generative deep models for novelty detection truly better?
Jul 13, 2018


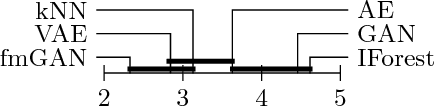
Many deep models have been recently proposed for anomaly detection. This paper presents comparison of selected generative deep models and classical anomaly detection methods on an extensive number of non--image benchmark datasets. We provide statistical comparison of the selected models, in many configurations, architectures and hyperparamaters. We arrive to conclusion that performance of the generative models is determined by the process of selection of their hyperparameters. Specifically, performance of the deep generative models deteriorates with decreasing amount of anomalous samples used in hyperparameter selection. In practical scenarios of anomaly detection, none of the deep generative models systematically outperforms the kNN.