 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTopPush: Simple and Scalable Method for Accuracy at the Top
Paper and Code
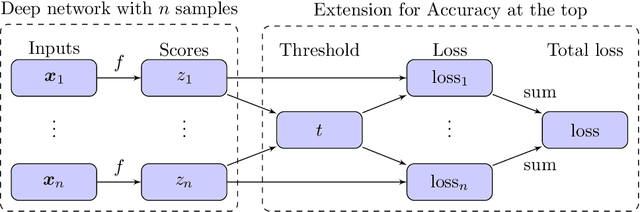
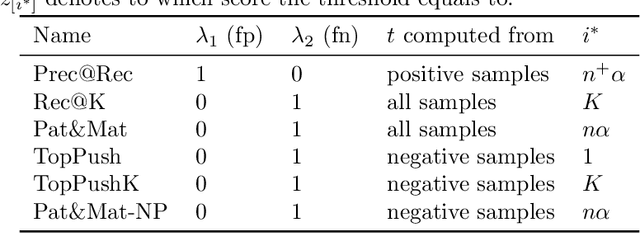
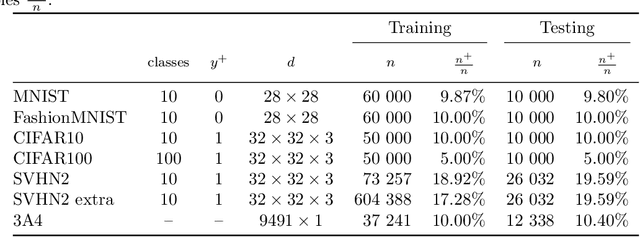
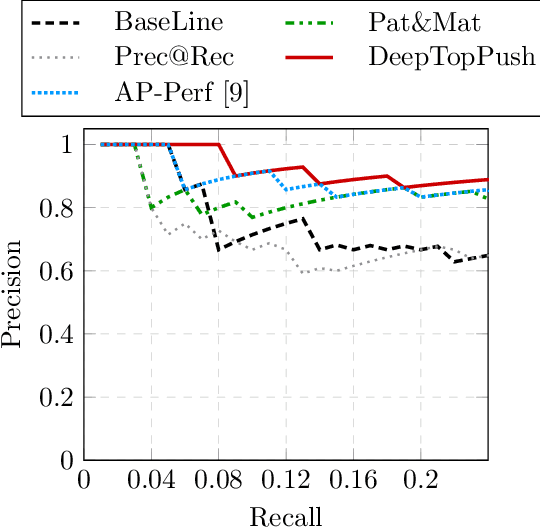
Accuracy at the top is a special class of binary classification problems where the performance is evaluated only on a small number of relevant (top) samples. Applications include information retrieval systems or processes with manual (expensive) postprocessing. This leads to the minimization of irrelevant samples above a threshold. We consider classifiers in the form of an arbitrary (deep) network and propose a new method DeepTopPush for minimizing the top loss function. Since the threshold depends on all samples, the problem is non-decomposable. We modify the stochastic gradient descent to handle the non-decomposability in an end-to-end training manner and propose a way to estimate the threshold only from values on the current minibatch. We demonstrate the good performance of DeepTopPush on visual recognition datasets and on a real-world application of selecting a small number of molecules for further drug testing.