Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear classifiers for ranking problems based on kernelized SVM
Paper and Code

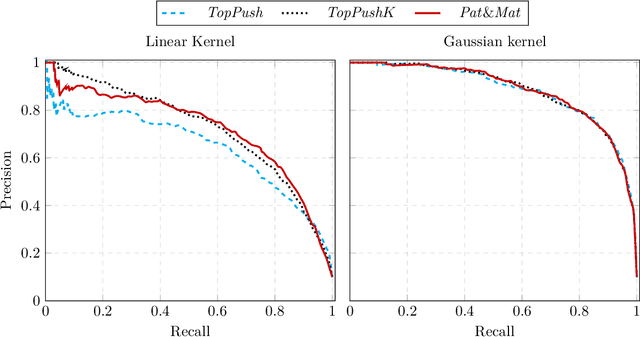
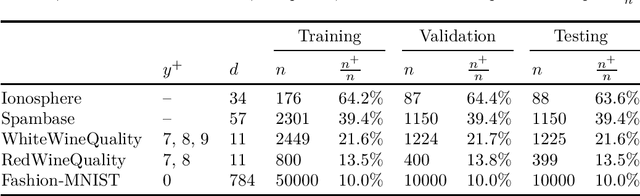
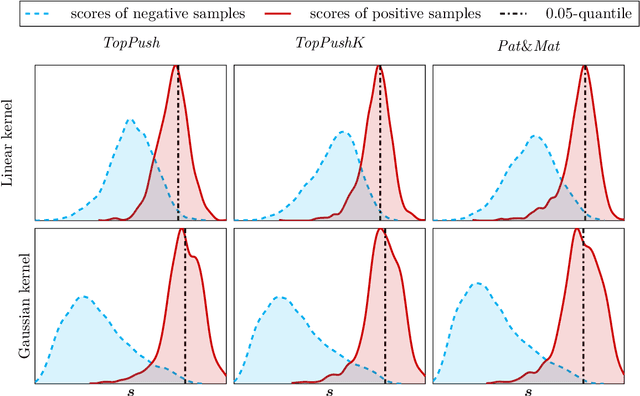
Many classification problems focus on maximizing the performance only on the samples with the highest relevance instead of all samples. As an example, we can mention ranking problems, accuracy at the top or search engines where only the top few queries matter. In our previous work, we derived a general framework including several classes of these linear classification problems. In this paper, we extend the framework to nonlinear classifiers. Utilizing a similarity to SVM, we dualize the problems, add kernels and propose a componentwise dual ascent method. This allows us to perform one iteration in less than 20 milliseconds on relatively large datasets such as FashionMNIST.
View paper on