 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Penalty-Barrier Methods for Constrained Machine Learning
May 19, 2026Constrained machine learning enables fairness-aware training, physics-informed neural networks, and integration of symbolic domain knowledge into statistical models. Despite its practical importance, no general method exists for the non-convex, non-smooth, stochastic setting that arises naturally in deep learning. We propose the Stochastic Penalty-Barrier Method (SPBM), which extends classical penalty and barrier methods to this setting via exponential dual averaging, a stabilized penalty schedule, and the Moreau envelope to handle non-smoothness. Experiments across multiple settings show that SPBM matches or outperforms existing constrained optimization baselines while incurring only linear runtime overhead compared to unconstrained Adam for up to 10,000 constraints.
Intersectional Fairness via Mixed-Integer Optimization
Jan 27, 2026The deployment of Artificial Intelligence in high-risk domains, such as finance and healthcare, necessitates models that are both fair and transparent. While regulatory frameworks, including the EU's AI Act, mandate bias mitigation, they are deliberately vague about the definition of bias. In line with existing research, we argue that true fairness requires addressing bias at the intersections of protected groups. We propose a unified framework that leverages Mixed-Integer Optimization (MIO) to train intersectionally fair and intrinsically interpretable classifiers. We prove the equivalence of two measures of intersectional fairness (MSD and SPSF) in detecting the most unfair subgroup and empirically demonstrate that our MIO-based algorithm improves performance in finding bias. We train high-performing, interpretable classifiers that bound intersectional bias below an acceptable threshold, offering a robust solution for regulated industries and beyond.
Tractable Probabilistic Models for Investment Planning
Nov 17, 2025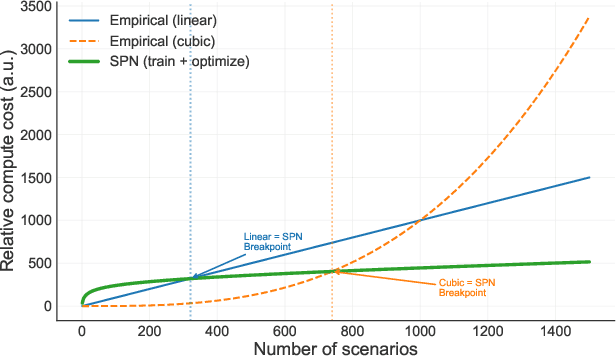
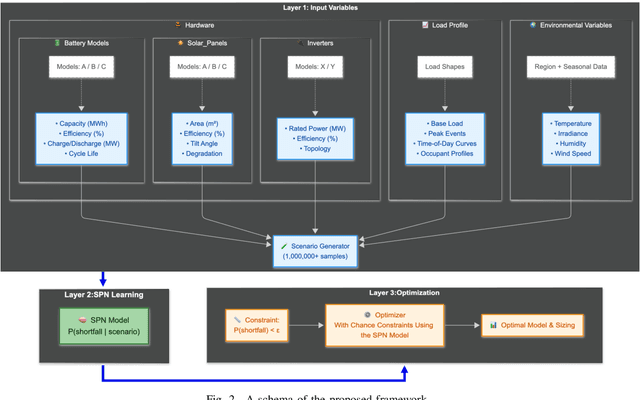
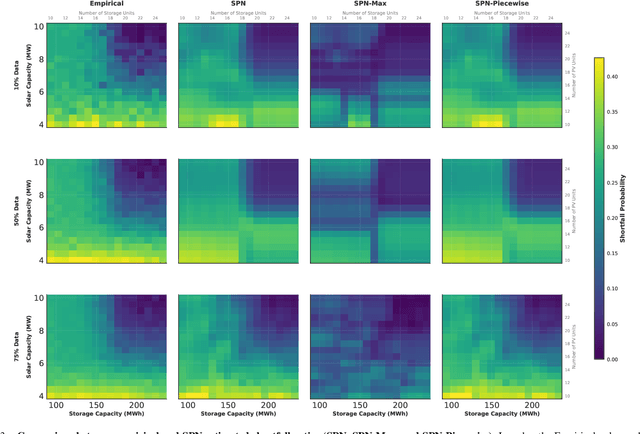
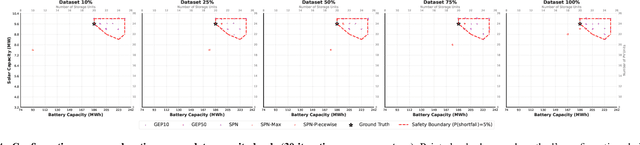
Investment planning in power utilities, such as generation and transmission expansion, requires decade-long forecasts under profound uncertainty. Forecasting of energy mix and energy use decades ahead is nontrivial. Classical approaches focus on generating a finite number of scenarios (modeled as a mixture of Diracs in statistical theory terms), which limits insight into scenario-specific volatility and hinders robust decision-making. We propose an alternative using tractable probabilistic models (TPMs), particularly sum-product networks (SPNs). These models enable exact, scalable inference of key quantities such as scenario likelihoods, marginals, and conditional probabilities, supporting robust scenario expansion and risk assessment. This framework enables direct embedding of chance-constrained optimization into investment planning, enforcing safety or reliability with prescribed confidence levels. TPMs allow both scenario analysis and volatility quantification by compactly representing high-dimensional uncertainties. We demonstrate the approach's effectiveness through a representative power system planning case study, illustrating computational and reliability advantages over traditional scenario-based models.
Plausible Counterfactual Explanations of Recommendations
Jul 10, 2025Explanations play a variety of roles in various recommender systems, from a legally mandated afterthought, through an integral element of user experience, to a key to persuasiveness. A natural and useful form of an explanation is the Counterfactual Explanation (CE). We present a method for generating highly plausible CEs in recommender systems and evaluate it both numerically and with a user study.
ExMAG: Learning of Maximally Ancestral Graphs
Mar 11, 2025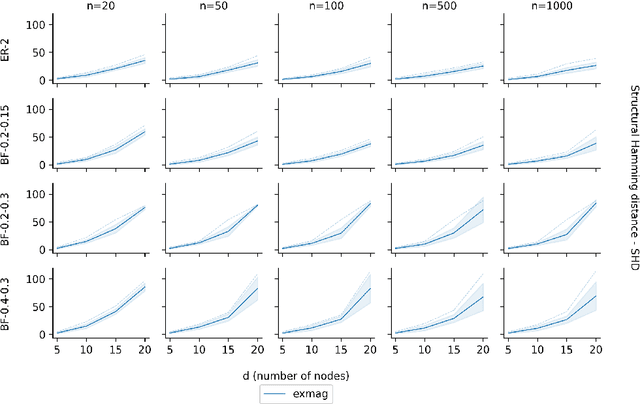
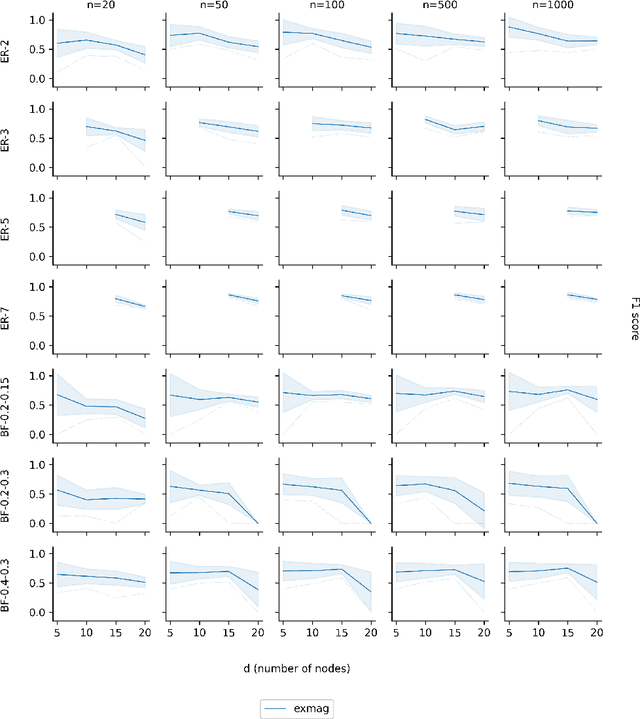
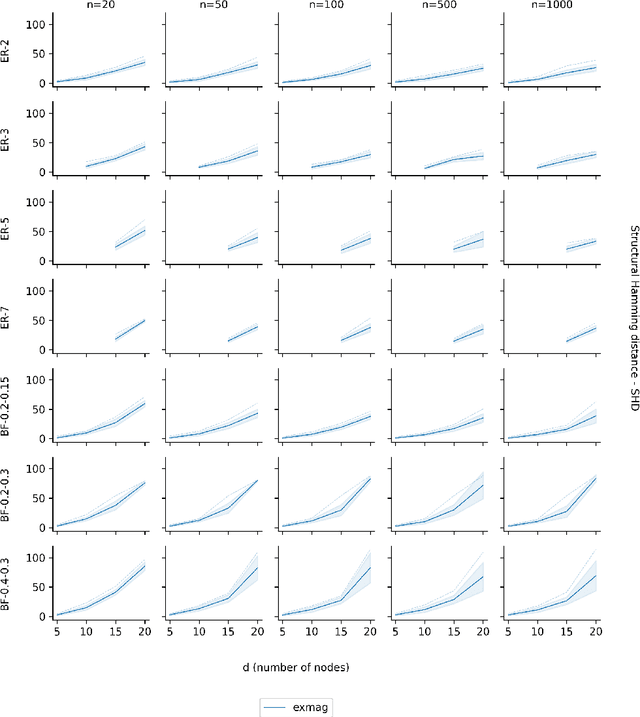
As one transitions from statistical to causal learning, one is seeking the most appropriate causal model. Dynamic Bayesian networks are a popular model, where a weighted directed acyclic graph represents the causal relationships. Stochastic processes are represented by its vertices, and weighted oriented edges suggest the strength of the causal relationships. When there are confounders, one would like to utilize both oriented edges (when the direction of causality is clear) and edges that are not oriented (when there is a confounder), yielding mixed graphs. A little-studied extension of acyclicity to this mixed-graph setting is known as maximally ancestral graphs. We propose a score-based learning algorithm for learning maximally ancestral graphs. A mixed-integer quadratic program is formulated, and an algorithmic approach is proposed, in which the pre-generation of exponentially many constraints is avoided by generating only violated constraints in the so-called branch-and-cut (``lazy constraint'') method. Comparing the novel approach to the state-of-the-art, we show that the proposed approach turns out to produce more accurate results when applied to small and medium-sized synthetic instances containing up to 25 variables.
Bias Detection via Maximum Subgroup Discrepancy
Feb 04, 2025



Bias evaluation is fundamental to trustworthy AI, both in terms of checking data quality and in terms of checking the outputs of AI systems. In testing data quality, for example, one may study a distance of a given dataset, viewed as a distribution, to a given ground-truth reference dataset. However, classical metrics, such as the Total Variation and the Wasserstein distances, are known to have high sample complexities and, therefore, may fail to provide meaningful distinction in many practical scenarios. In this paper, we propose a new notion of distance, the Maximum Subgroup Discrepancy (MSD). In this metric, two distributions are close if, roughly, discrepancies are low for all feature subgroups. While the number of subgroups may be exponential, we show that the sample complexity is linear in the number of features, thus making it feasible for practical applications. Moreover, we provide a practical algorithm for the evaluation of the distance, based on Mixed-integer optimization (MIO). We also note that the proposed distance is easily interpretable, thus providing clearer paths to fixing the biases once they have been identified. It also provides guarantees for all subgroups. Finally, we empirically evaluate, compare with other metrics, and demonstrate the above properties of MSD on real-world datasets.
ExDBN: Exact learning of Dynamic Bayesian Networks
Oct 21, 2024



Causal learning from data has received much attention in recent years. One way of capturing causal relationships is by utilizing Bayesian networks. There, one recovers a weighted directed acyclic graph, in which random variables are represented by vertices, and the weights associated with each edge represent the strengths of the causal relationships between them. This concept is extended to capture dynamic effects by introducing a dependency on past data, which may be captured by the structural equation model, which is utilized in the present contribution to formulate a score-based learning approach. A mixed-integer quadratic program is formulated and an algorithmic solution proposed, in which the pre-generation of exponentially many acyclicity constraints is avoided by utilizing the so-called branch-and-cut ("lazy constraint") method. Comparing the novel approach to the state of the art, we show that the proposed approach turns out to produce excellent results when applied to small and medium-sized synthetic instances of up to 25 time-series. Lastly, two interesting applications in bio-science and finance, to which the method is directly applied, further stress the opportunities in developing highly accurate, globally convergent solvers that can handle modest instances.
ExDAG: Exact learning of DAGs
Jun 21, 2024There has been a growing interest in causal learning in recent years. Commonly used representations of causal structures, including Bayesian networks and structural equation models (SEM), take the form of directed acyclic graphs (DAGs). We provide a novel mixed-integer quadratic programming formulation and associated algorithm that identifies DAGs on up to 50 vertices, where these are identifiable. We call this method ExDAG, which stands for Exact learning of DAGs. Although there is a superexponential number of constraints that prevent the formation of cycles, the algorithm adds constraints violated by solutions found, rather than imposing all constraints in each continuous-valued relaxation. Our empirical results show that ExDAG outperforms local state-of-the-art solvers in terms of precision and outperforms state-of-the-art global solvers with respect to scaling, when considering Gaussian noise. We also provide validation with respect to other noise distributions.
Causal Learning in Biomedical Applications
Jun 21, 2024



We present a benchmark for methods in causal learning. Specifically, we consider training a rich class of causal models from time-series data, and we suggest the use of the Krebs cycle and models of metabolism more broadly.