 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvast-CTU Public CAPE Dataset
Sep 06, 2022
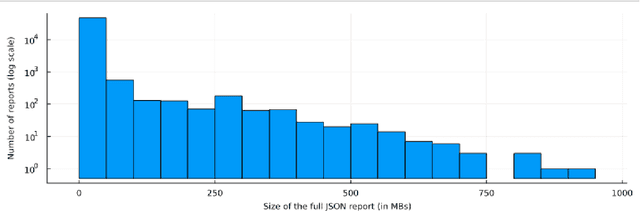

There is a limited amount of publicly available data to support research in malware analysis technology. Particularly, there are virtually no publicly available datasets generated from rich sandboxes such as Cuckoo/CAPE. The benefit of using dynamic sandboxes is the realistic simulation of file execution in the target machine and obtaining a log of such execution. The machine can be infected by malware hence there is a good chance of capturing the malicious behavior in the execution logs, thus allowing researchers to study such behavior in detail. Although the subsequent analysis of log information is extensively covered in industrial cybersecurity backends, to our knowledge there has been only limited effort invested in academia to advance such log analysis capabilities using cutting edge techniques. We make this sample dataset available to support designing new machine learning methods for malware detection, especially for automatic detection of generic malicious behavior. The dataset has been collected in cooperation between Avast Software and Czech Technical University - AI Center (AIC).
Explaining Classifiers Trained on Raw Hierarchical Multiple-Instance Data
Aug 04, 2022
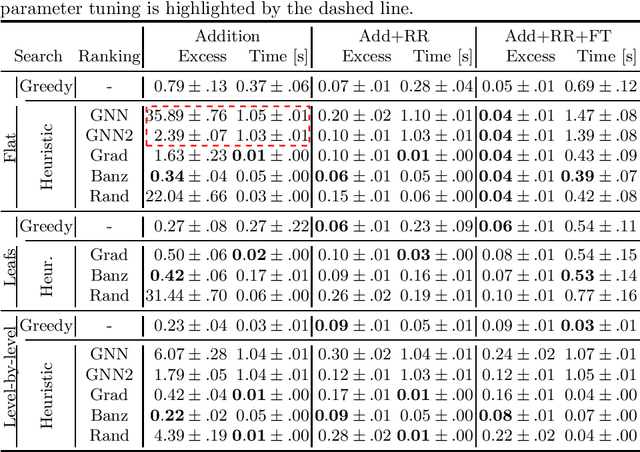

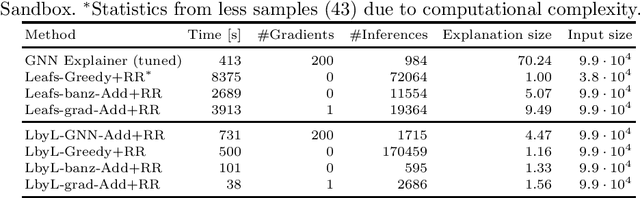
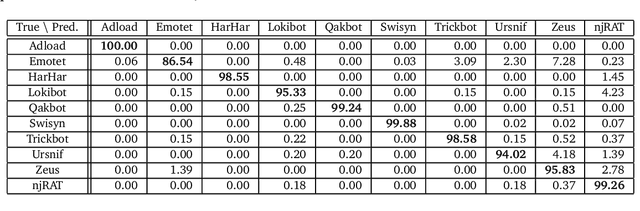
Learning from raw data input, thus limiting the need for feature engineering, is a component of many successful applications of machine learning methods in various domains. While many problems naturally translate into a vector representation directly usable in standard classifiers, a number of data sources have the natural form of structured data interchange formats (e.g., security logs in JSON/XML format). Existing methods, such as in Hierarchical Multiple Instance Learning (HMIL), allow learning from such data in their raw form. However, the explanation of the classifiers trained on raw structured data remains largely unexplored. By treating these models as sub-set selections problems, we demonstrate how interpretable explanations, with favourable properties, can be generated using computationally efficient algorithms. We compare to an explanation technique adopted from graph neural networks showing an order of magnitude speed-up and higher-quality explanations.
Discriminative models for multi-instance problems with tree-structure
Mar 07, 2017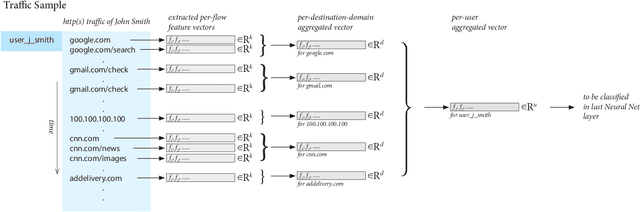


Modeling network traffic is gaining importance in order to counter modern threats of ever increasing sophistication. It is though surprisingly difficult and costly to construct reliable classifiers on top of telemetry data due to the variety and complexity of signals that no human can manage to interpret in full. Obtaining training data with sufficiently large and variable body of labels can thus be seen as prohibitive problem. The goal of this work is to detect infected computers by observing their HTTP(S) traffic collected from network sensors, which are typically proxy servers or network firewalls, while relying on only minimal human input in model training phase. We propose a discriminative model that makes decisions based on all computer's traffic observed during predefined time window (5 minutes in our case). The model is trained on collected traffic samples over equally sized time window per large number of computers, where the only labels needed are human verdicts about the computer as a whole (presumed infected vs. presumed clean). As part of training the model itself recognizes discriminative patterns in traffic targeted to individual servers and constructs the final high-level classifier on top of them. We show the classifier to perform with very high precision, while the learned traffic patterns can be interpreted as Indicators of Compromise. In the following we implement the discriminative model as a neural network with special structure reflecting two stacked multi-instance problems. The main advantages of the proposed configuration include not only improved accuracy and ability to learn from gross labels, but also automatic learning of server types (together with their detectors) which are typically visited by infected computers.
Using Neural Network Formalism to Solve Multiple-Instance Problems
Mar 07, 2017
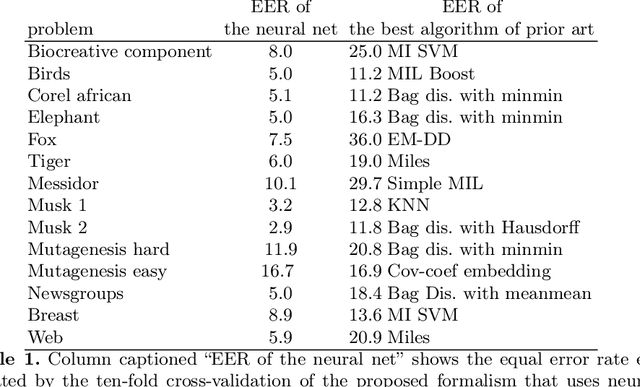
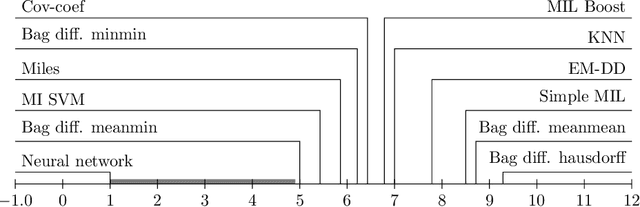

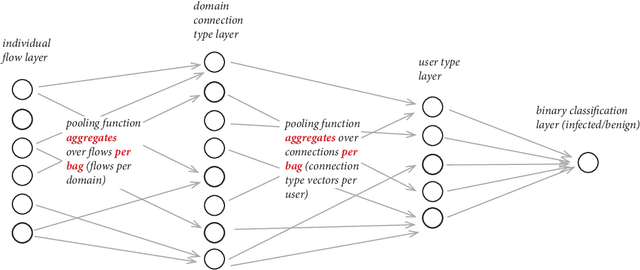
Many objects in the real world are difficult to describe by a single numerical vector of a fixed length, whereas describing them by a set of vectors is more natural. Therefore, Multiple instance learning (MIL) techniques have been constantly gaining on importance throughout last years. MIL formalism represents each object (sample) by a set (bag) of feature vectors (instances) of fixed length where knowledge about objects (e.g., class label) is available on bag level but not necessarily on instance level. Many standard tools including supervised classifiers have been already adapted to MIL setting since the problem got formalized in late nineties. In this work we propose a neural network (NN) based formalism that intuitively bridges the gap between MIL problem definition and the vast existing knowledge-base of standard models and classifiers. We show that the proposed NN formalism is effectively optimizable by a modified back-propagation algorithm and can reveal unknown patterns inside bags. Comparison to eight types of classifiers from the prior art on a set of 14 publicly available benchmark datasets confirms the advantages and accuracy of the proposed solution.