 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Classifiers Trained on Raw Hierarchical Multiple-Instance Data
Aug 04, 2022
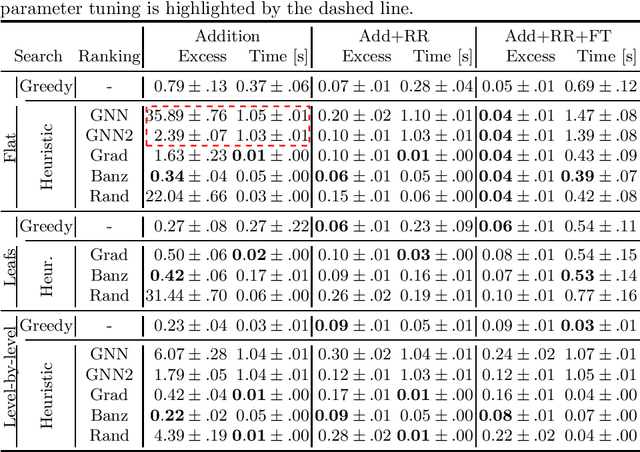

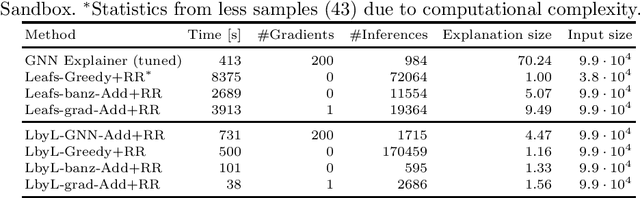
Learning from raw data input, thus limiting the need for feature engineering, is a component of many successful applications of machine learning methods in various domains. While many problems naturally translate into a vector representation directly usable in standard classifiers, a number of data sources have the natural form of structured data interchange formats (e.g., security logs in JSON/XML format). Existing methods, such as in Hierarchical Multiple Instance Learning (HMIL), allow learning from such data in their raw form. However, the explanation of the classifiers trained on raw structured data remains largely unexplored. By treating these models as sub-set selections problems, we demonstrate how interpretable explanations, with favourable properties, can be generated using computationally efficient algorithms. We compare to an explanation technique adopted from graph neural networks showing an order of magnitude speed-up and higher-quality explanations.
Multi-agent RRT*: Sampling-based Cooperative Pathfinding (Extended Abstract)
Feb 12, 2013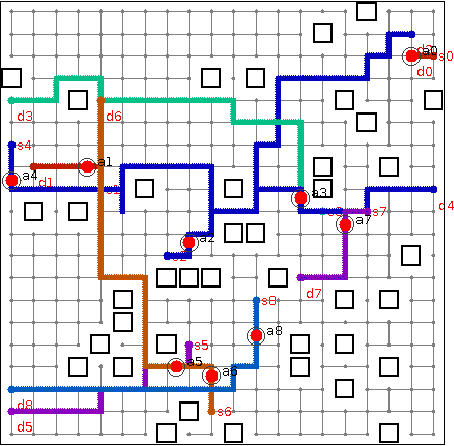
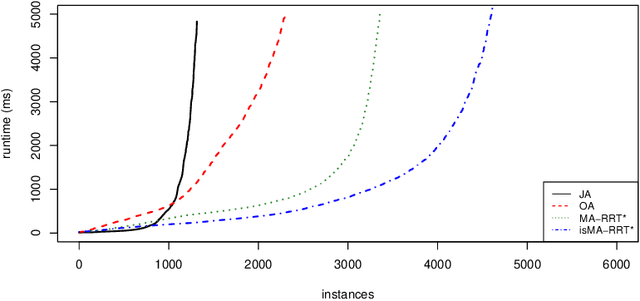
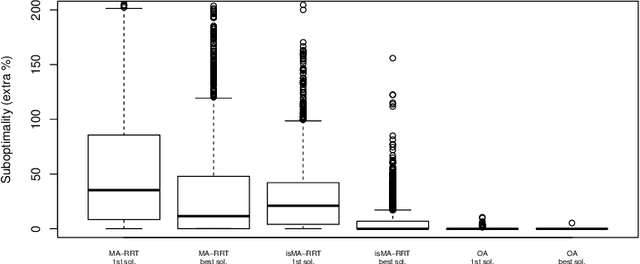

Cooperative pathfinding is a problem of finding a set of non-conflicting trajectories for a number of mobile agents. Its applications include planning for teams of mobile robots, such as autonomous aircrafts, cars, or underwater vehicles. The state-of-the-art algorithms for cooperative pathfinding typically rely on some heuristic forward-search pathfinding technique, where A* is often the algorithm of choice. Here, we propose MA-RRT*, a novel algorithm for multi-agent path planning that builds upon a recently proposed asymptotically-optimal sampling-based algorithm for finding single-agent shortest path called RRT*. We experimentally evaluate the performance of the algorithm and show that the sampling-based approach offers better scalability than the classical forward-search approach in relatively large, but sparse environments, which are typical in real-world applications such as multi-aircraft collision avoidance.
Asynchronous Decentralized Algorithm for Space-Time Cooperative Pathfinding
Oct 25, 2012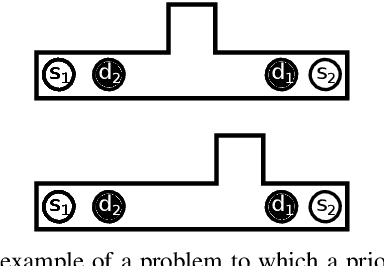

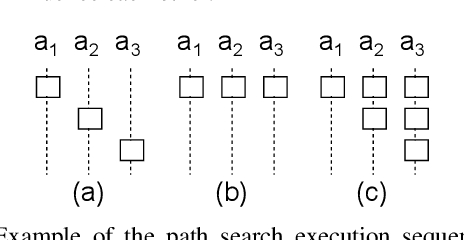
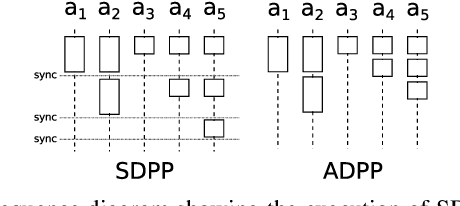
Cooperative pathfinding is a multi-agent path planning problem where a group of vehicles searches for a corresponding set of non-conflicting space-time trajectories. Many of the practical methods for centralized solving of cooperative pathfinding problems are based on the prioritized planning strategy. However, in some domains (e.g., multi-robot teams of unmanned aerial vehicles, autonomous underwater vehicles, or unmanned ground vehicles) a decentralized approach may be more desirable than a centralized one due to communication limitations imposed by the domain and/or privacy concerns. In this paper we present an asynchronous decentralized variant of prioritized planning ADPP and its interruptible version IADPP. The algorithm exploits the inherent parallelism of distributed systems and allows for a speed up of the computation process. Unlike the synchronized planning approaches, the algorithm allows an agent to react to updates about other agents' paths immediately and invoke its local spatio-temporal path planner to find the best trajectory, as response to the other agents' choices. We provide a proof of correctness of the algorithms and experimentally evaluate them on synthetic domains.
Decentralized Multi-agent Plan Repair in Dynamic Environments
Feb 13, 2012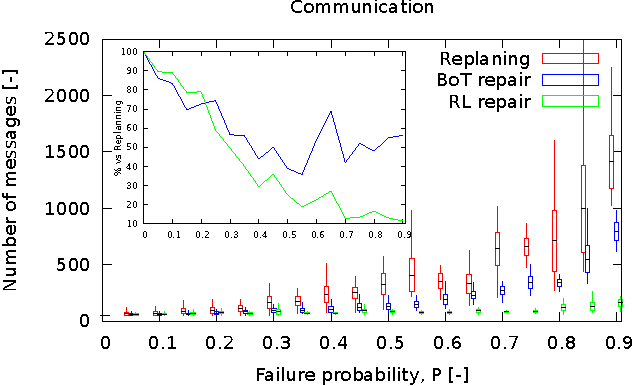
Achieving joint objectives by teams of cooperative planning agents requires significant coordination and communication efforts. For a single-agent system facing a plan failure in a dynamic environment, arguably, attempts to repair the failed plan in general do not straightforwardly bring any benefit in terms of time complexity. However, in multi-agent settings the communication complexity might be of a much higher importance, possibly a high communication overhead might be even prohibitive in certain domains. We hypothesize that in decentralized systems, where coordination is enforced to achieve joint objectives, attempts to repair failed multi-agent plans should lead to lower communication overhead than replanning from scratch. The contribution of the presented paper is threefold. Firstly, we formally introduce the multi-agent plan repair problem and formally present the core hypothesis underlying our work. Secondly, we propose three algorithms for multi-agent plan repair reducing the problem to specialized instances of the multi-agent planning problem. Finally, we present results of experimental validation confirming the core hypothesis of the paper.