 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounteracting Concept Drift by Learning with Future Malware Predictions
Apr 14, 2024The accuracy of deployed malware-detection classifiers degrades over time due to changes in data distributions and increasing discrepancies between training and testing data. This phenomenon is known as the concept drift. While the concept drift can be caused by various reasons in general, new malicious files are created by malware authors with a clear intention of avoiding detection. The existence of the intention opens a possibility for predicting such future samples. Including predicted samples in training data should consequently increase the accuracy of the classifiers on new testing data. We compare two methods for predicting future samples: (1) adversarial training and (2) generative adversarial networks (GANs). The first method explicitly seeks for adversarial examples against the classifier that are then used as a part of training data. Similarly, GANs also generate synthetic training data. We use GANs to learn changes in data distributions within different time periods of training data and then apply these changes to generate samples that could be in testing data. We compare these prediction methods on two different datasets: (1) Ember public dataset and (2) the internal dataset of files incoming to Avast. We show that while adversarial training yields more robust classifiers, this method is not a good predictor of future malware in general. This is in contrast with previously reported positive results in different domains (including natural language processing and spam detection). On the other hand, we show that GANs can be successfully used as predictors of future malware. We specifically examine malware families that exhibit significant changes in their data distributions over time and the experimental results confirm that GAN-based predictions can significantly improve the accuracy of the classifier on new, previously unseen data.
Avast-CTU Public CAPE Dataset
Sep 06, 2022
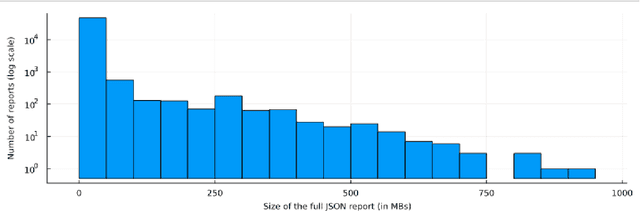

There is a limited amount of publicly available data to support research in malware analysis technology. Particularly, there are virtually no publicly available datasets generated from rich sandboxes such as Cuckoo/CAPE. The benefit of using dynamic sandboxes is the realistic simulation of file execution in the target machine and obtaining a log of such execution. The machine can be infected by malware hence there is a good chance of capturing the malicious behavior in the execution logs, thus allowing researchers to study such behavior in detail. Although the subsequent analysis of log information is extensively covered in industrial cybersecurity backends, to our knowledge there has been only limited effort invested in academia to advance such log analysis capabilities using cutting edge techniques. We make this sample dataset available to support designing new machine learning methods for malware detection, especially for automatic detection of generic malicious behavior. The dataset has been collected in cooperation between Avast Software and Czech Technical University - AI Center (AIC).
Improving Robustness of Malware Classifiers using Adversarial Strings Generated from Perturbed Latent Representations
Oct 22, 2021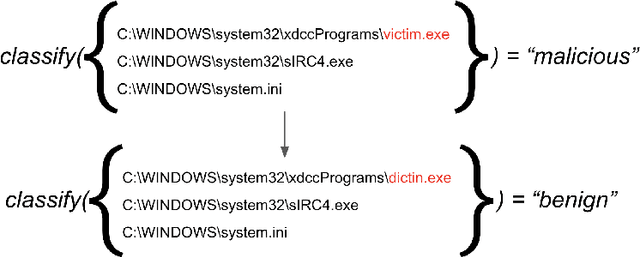

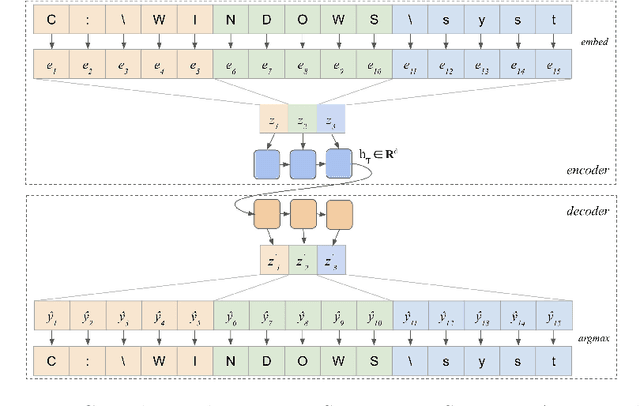

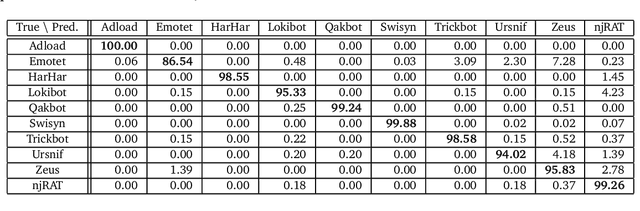
In malware behavioral analysis, the list of accessed and created files very often indicates whether the examined file is malicious or benign. However, malware authors are trying to avoid detection by generating random filenames and/or modifying used filenames with new versions of the malware. These changes represent real-world adversarial examples. The goal of this work is to generate realistic adversarial examples and improve the classifier's robustness against these attacks. Our approach learns latent representations of input strings in an unsupervised fashion and uses gradient-based adversarial attack methods in the latent domain to generate adversarial examples in the input domain. We use these examples to improve the classifier's robustness by training on the generated adversarial set of strings. Compared to classifiers trained only on perturbed latent vectors, our approach produces classifiers that are significantly more robust without a large trade-off in standard accuracy.
Mill.jl and JsonGrinder.jl: automated differentiable feature extraction for learning from raw JSON data
May 19, 2021

Learning from raw data input, thus limiting the need for manual feature engineering, is one of the key components of many successful applications of machine learning methods. While machine learning problems are often formulated on data that naturally translate into a vector representation suitable for classifiers, there are data sources, for example in cybersecurity, that are naturally represented in diverse files with a unifying hierarchical structure, such as XML, JSON, and Protocol Buffers. Converting this data to vector (tensor) representation is generally done by manual feature engineering, which is laborious, lossy, and prone to human bias about the importance of particular features. Mill and JsonGrinder is a tandem of libraries, which fully automates the conversion. Starting with an arbitrary set of JSON samples, they create a differentiable machine learning model capable of infer from further JSON samples in their raw form.
Multi-agent Reinforcement Learning in OpenSpiel: A Reproduction Report
Mar 02, 2021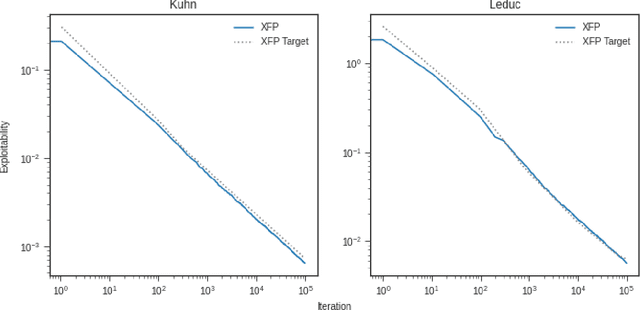
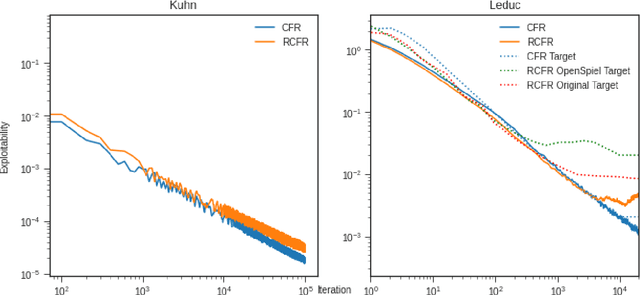

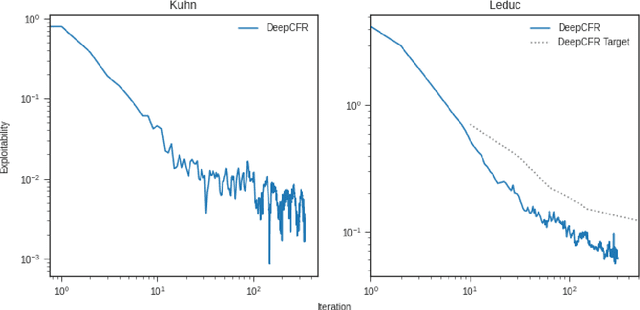
In this report, we present results reproductions for several core algorithms implemented in the OpenSpiel framework for learning in games. The primary contribution of this work is a validation of OpenSpiel's re-implemented search and Reinforcement Learning algorithms against the results reported in their respective originating works. Additionally, we provide complete documentation of hyperparameters and source code required to reproduce these experiments easily and exactly.
Discovering Imperfectly Observable Adversarial Actions using Anomaly Detection
Apr 22, 2020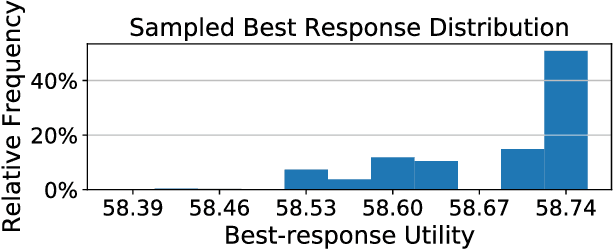

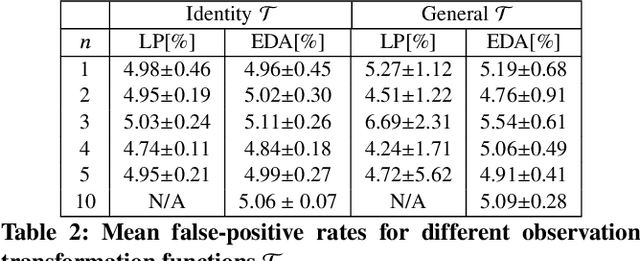

Anomaly detection is a method for discovering unusual and suspicious behavior. In many real-world scenarios, the examined events can be directly linked to the actions of an adversary, such as attacks on computer networks or frauds in financial operations. While the defender wants to discover such malicious behavior, the attacker seeks to accomplish their goal (e.g., exfiltrating data) while avoiding the detection. To this end, anomaly detectors have been used in a game-theoretic framework that captures these goals of a two-player competition. We extend the existing models to more realistic settings by (1) allowing both players to have continuous action spaces and by assuming that (2) the defender cannot perfectly observe the action of the attacker. We propose two algorithms for solving such games -- a direct extension of existing algorithms based on discretizing the feature space and linear programming and the second algorithm based on constrained learning. Experiments show that both algorithms are applicable for cases with low feature space dimensions but the learning-based method produces less exploitable strategies and it is scalable to higher dimensions. Moreover, we use real-world data to compare our approaches with existing classifiers in a data-exfiltration scenario via the DNS channel. The results show that our models are significantly less exploitable by an informed attacker.