 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounteracting Concept Drift by Learning with Future Malware Predictions
Apr 14, 2024The accuracy of deployed malware-detection classifiers degrades over time due to changes in data distributions and increasing discrepancies between training and testing data. This phenomenon is known as the concept drift. While the concept drift can be caused by various reasons in general, new malicious files are created by malware authors with a clear intention of avoiding detection. The existence of the intention opens a possibility for predicting such future samples. Including predicted samples in training data should consequently increase the accuracy of the classifiers on new testing data. We compare two methods for predicting future samples: (1) adversarial training and (2) generative adversarial networks (GANs). The first method explicitly seeks for adversarial examples against the classifier that are then used as a part of training data. Similarly, GANs also generate synthetic training data. We use GANs to learn changes in data distributions within different time periods of training data and then apply these changes to generate samples that could be in testing data. We compare these prediction methods on two different datasets: (1) Ember public dataset and (2) the internal dataset of files incoming to Avast. We show that while adversarial training yields more robust classifiers, this method is not a good predictor of future malware in general. This is in contrast with previously reported positive results in different domains (including natural language processing and spam detection). On the other hand, we show that GANs can be successfully used as predictors of future malware. We specifically examine malware families that exhibit significant changes in their data distributions over time and the experimental results confirm that GAN-based predictions can significantly improve the accuracy of the classifier on new, previously unseen data.
Discovering Imperfectly Observable Adversarial Actions using Anomaly Detection
Apr 22, 2020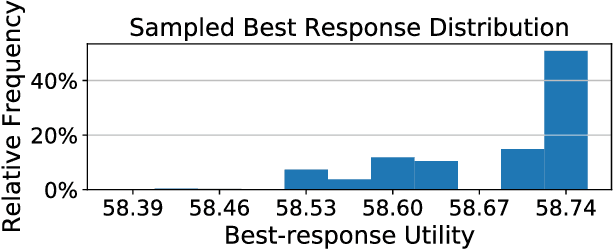

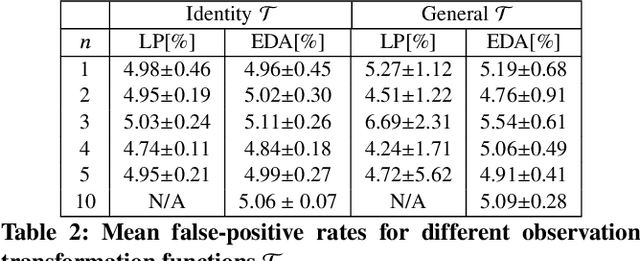

Anomaly detection is a method for discovering unusual and suspicious behavior. In many real-world scenarios, the examined events can be directly linked to the actions of an adversary, such as attacks on computer networks or frauds in financial operations. While the defender wants to discover such malicious behavior, the attacker seeks to accomplish their goal (e.g., exfiltrating data) while avoiding the detection. To this end, anomaly detectors have been used in a game-theoretic framework that captures these goals of a two-player competition. We extend the existing models to more realistic settings by (1) allowing both players to have continuous action spaces and by assuming that (2) the defender cannot perfectly observe the action of the attacker. We propose two algorithms for solving such games -- a direct extension of existing algorithms based on discretizing the feature space and linear programming and the second algorithm based on constrained learning. Experiments show that both algorithms are applicable for cases with low feature space dimensions but the learning-based method produces less exploitable strategies and it is scalable to higher dimensions. Moreover, we use real-world data to compare our approaches with existing classifiers in a data-exfiltration scenario via the DNS channel. The results show that our models are significantly less exploitable by an informed attacker.