 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounteracting Concept Drift by Learning with Future Malware Predictions
Apr 14, 2024The accuracy of deployed malware-detection classifiers degrades over time due to changes in data distributions and increasing discrepancies between training and testing data. This phenomenon is known as the concept drift. While the concept drift can be caused by various reasons in general, new malicious files are created by malware authors with a clear intention of avoiding detection. The existence of the intention opens a possibility for predicting such future samples. Including predicted samples in training data should consequently increase the accuracy of the classifiers on new testing data. We compare two methods for predicting future samples: (1) adversarial training and (2) generative adversarial networks (GANs). The first method explicitly seeks for adversarial examples against the classifier that are then used as a part of training data. Similarly, GANs also generate synthetic training data. We use GANs to learn changes in data distributions within different time periods of training data and then apply these changes to generate samples that could be in testing data. We compare these prediction methods on two different datasets: (1) Ember public dataset and (2) the internal dataset of files incoming to Avast. We show that while adversarial training yields more robust classifiers, this method is not a good predictor of future malware in general. This is in contrast with previously reported positive results in different domains (including natural language processing and spam detection). On the other hand, we show that GANs can be successfully used as predictors of future malware. We specifically examine malware families that exhibit significant changes in their data distributions over time and the experimental results confirm that GAN-based predictions can significantly improve the accuracy of the classifier on new, previously unseen data.
The Power of MEME: Adversarial Malware Creation with Model-Based Reinforcement Learning
Aug 31, 2023Due to the proliferation of malware, defenders are increasingly turning to automation and machine learning as part of the malware detection tool-chain. However, machine learning models are susceptible to adversarial attacks, requiring the testing of model and product robustness. Meanwhile, attackers also seek to automate malware generation and evasion of antivirus systems, and defenders try to gain insight into their methods. This work proposes a new algorithm that combines Malware Evasion and Model Extraction (MEME) attacks. MEME uses model-based reinforcement learning to adversarially modify Windows executable binary samples while simultaneously training a surrogate model with a high agreement with the target model to evade. To evaluate this method, we compare it with two state-of-the-art attacks in adversarial malware creation, using three well-known published models and one antivirus product as targets. Results show that MEME outperforms the state-of-the-art methods in terms of evasion capabilities in almost all cases, producing evasive malware with an evasion rate in the range of 32-73%. It also produces surrogate models with a prediction label agreement with the respective target models between 97-99%. The surrogate could be used to fine-tune and improve the evasion rate in the future.
Out of the Cage: How Stochastic Parrots Win in Cyber Security Environments
Aug 28, 2023Large Language Models (LLMs) have gained widespread popularity across diverse domains involving text generation, summarization, and various natural language processing tasks. Despite their inherent limitations, LLM-based designs have shown promising capabilities in planning and navigating open-world scenarios. This paper introduces a novel application of pre-trained LLMs as agents within cybersecurity network environments, focusing on their utility for sequential decision-making processes. We present an approach wherein pre-trained LLMs are leveraged as attacking agents in two reinforcement learning environments. Our proposed agents demonstrate similar or better performance against state-of-the-art agents trained for thousands of episodes in most scenarios and configurations. In addition, the best LLM agents perform similarly to human testers of the environment without any additional training process. This design highlights the potential of LLMs to efficiently address complex decision-making tasks within cybersecurity. Furthermore, we introduce a new network security environment named NetSecGame. The environment is designed to eventually support complex multi-agent scenarios within the network security domain. The proposed environment mimics real network attacks and is designed to be highly modular and adaptable for various scenarios.
Stealing Malware Classifiers and AVs at Low False Positive Conditions
Apr 13, 2022
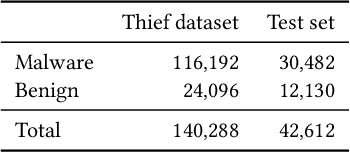
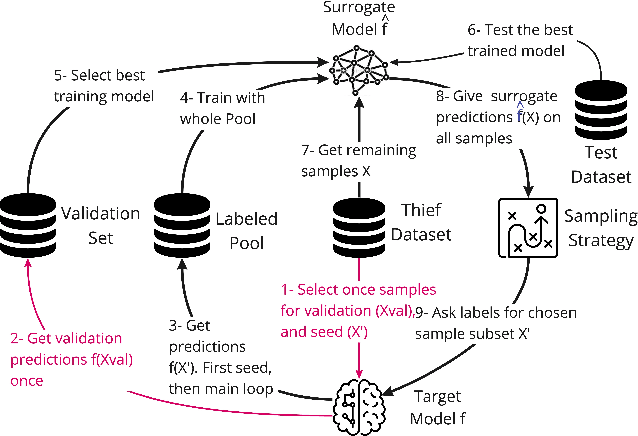
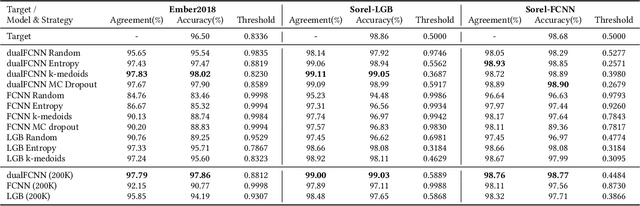
Model stealing attacks have been successfully used in many machine learning domains, but there is little understanding of how these attacks work in the malware detection domain. Malware detection and, in general, security domains have very strong requirements of low false positive rates (FPR). However, these requirements are not the primary focus of the existing model stealing literature. Stealing attacks create surrogate models that perform similarly to a target model using a limited amount of queries to the target. The first stage of this study is the evaluation of active learning model stealing attacks against publicly available stand-alone machine learning malware classifiers and antivirus products (AVs). We propose a new neural network architecture for surrogate models that outperforms the existing state of the art on low FPR conditions. The surrogates were evaluated on their agreement with the targeted models. Good surrogates of the stand-alone classifiers were created with up to 99% agreement with the target models, using less than 4% of the original training dataset size. Good AV surrogates were also possible to train, but with a lower agreement. The second stage used the best surrogates as well as the target models to generate adversarial malware using the MAB framework to test stand-alone models and AVs (offline and online). Results showed that surrogate models could generate adversarial samples that evade the targets but are less successful than the targets themselves. Using surrogates, however, is a necessity for attackers, given that attacks against AVs are extremely time-consuming and easily detected when the AVs are connected to the internet.
A Survey of Privacy Attacks in Machine Learning
Jul 15, 2020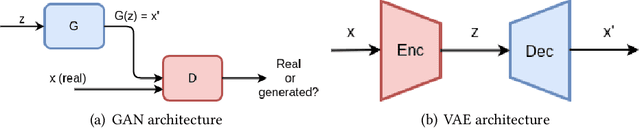



As machine learning becomes more widely used, the need to study its implications in security and privacy becomes more urgent. Research on the security aspects of machine learning, such as adversarial attacks, has received a lot of focus and publicity, but privacy related attacks have received less attention from the research community. Although there is a growing body of work in the area, there is yet no extensive analysis of privacy related attacks. To contribute into this research line we analyzed more than 40 papers related to privacy attacks against machine learning that have been published during the past seven years. Based on this analysis, an attack taxonomy is proposed together with a threat model that allows the categorization of the different attacks based on the adversarial knowledge and the assets under attack. In addition, a detailed analysis of the different attacks is presented, including the models under attack and the datasets used, as well as the common elements and main differences between the approaches under the defined threat model. Finally, we explore the potential reasons for privacy leaks and present an overview of the most common proposed defenses.
DNS Tunneling: A Deep Learning based Lexicographical Detection Approach
Jun 14, 2020
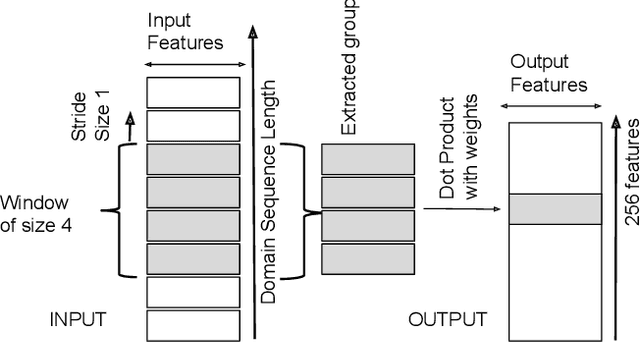


Domain Name Service is a trusted protocol made for name resolution, but during past years some approaches have been developed to use it for data transfer. DNS Tunneling is a method where data is encoded inside DNS queries, allowing information exchange through the DNS. This characteristic is attractive to hackers who exploit DNS Tunneling method to establish bidirectional communication with machines infected with malware with the objective of exfiltrating data or sending instructions in an obfuscated way. To detect these threats fast and accurately, the present work proposes a detection approach based on a Convolutional Neural Network (CNN) with a minimal architecture complexity. Due to the lack of quality datasets for evaluating DNS Tunneling connections, we also present a detailed construction and description of a novel dataset that contains DNS Tunneling domains generated with five well-known DNS tools. Despite its simple architecture, the resulting CNN model correctly detected more than 92% of total Tunneling domains with a false positive rate close to 0.8%.