 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelLMes: A high-interaction AI-based deception framework
Oct 08, 2025There are very few SotA deception systems based on Large Language Models. The existing ones are limited only to simulating one type of service, mainly SSH shells. These systems - but also the deception technologies not based on LLMs - lack an extensive evaluation that includes human attackers. Generative AI has recently become a valuable asset for cybersecurity researchers and practitioners, and the field of cyber-deception is no exception. Researchers have demonstrated how LLMs can be leveraged to create realistic-looking honeytokens, fake users, and even simulated systems that can be used as honeypots. This paper presents an AI-based deception framework called VelLMes, which can simulate multiple protocols and services such as SSH Linux shell, MySQL, POP3, and HTTP. All of these can be deployed and used as honeypots, thus VelLMes offers a variety of choices for deception design based on the users' needs. VelLMes is designed to be attacked by humans, so interactivity and realism are key for its performance. We evaluate the generative capabilities and the deception capabilities. Generative capabilities were evaluated using unit tests for LLMs. The results of the unit tests show that, with careful prompting, LLMs can produce realistic-looking responses, with some LLMs having a 100% passing rate. In the case of the SSH Linux shell, we evaluated deception capabilities with 89 human attackers. The results showed that about 30% of the attackers thought that they were interacting with a real system when they were assigned an LLM-based honeypot. Lastly, we deployed 10 instances of the SSH Linux shell honeypot on the Internet to capture real-life attacks. Analysis of these attacks showed us that LLM honeypots simulating Linux shells can perform well against unstructured and unexpected attacks on the Internet, responding correctly to most of the issued commands.
Towards Better Understanding of Cybercrime: The Role of Fine-Tuned LLMs in Translation
Apr 02, 2024

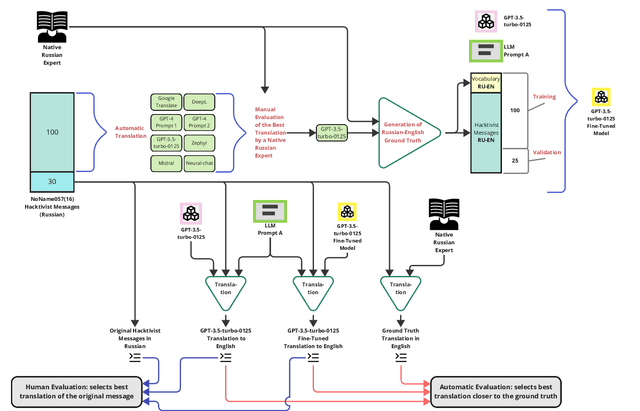

Understanding cybercrime communications is paramount for cybersecurity defence. This often involves translating communications into English for processing, interpreting, and generating timely intelligence. The problem is that translation is hard. Human translation is slow, expensive, and scarce. Machine translation is inaccurate and biased. We propose using fine-tuned Large Language Models (LLM) to generate translations that can accurately capture the nuances of cybercrime language. We apply our technique to public chats from the NoName057(16) Russian-speaking hacktivist group. Our results show that our fine-tuned LLM model is better, faster, more accurate, and able to capture nuances of the language. Our method shows it is possible to achieve high-fidelity translations and significantly reduce costs by a factor ranging from 430 to 23,000 compared to a human translator.
LLM in the Shell: Generative Honeypots
Aug 31, 2023
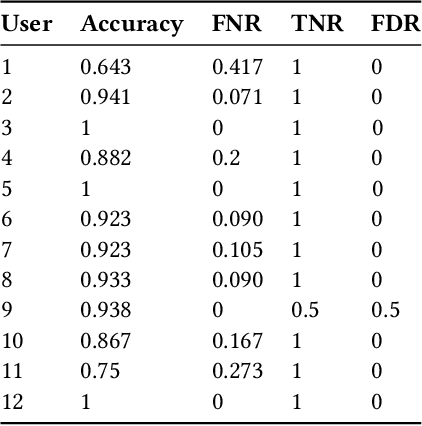
Honeypots are essential tools in cybersecurity. However, most of them (even the high-interaction ones) lack the required realism to engage and fool human attackers. This limitation makes them easily discernible, hindering their effectiveness. This work introduces a novel method to create dynamic and realistic software honeypots based on Large Language Models. Preliminary results indicate that LLMs can create credible and dynamic honeypots capable of addressing important limitations of previous honeypots, such as deterministic responses, lack of adaptability, etc. We evaluated the realism of each command by conducting an experiment with human attackers who needed to say if the answer from the honeypot was fake or not. Our proposed honeypot, called shelLM, reached an accuracy rate of 0.92.
Beyond Random Split for Assessing Statistical Model Performance
Sep 04, 2022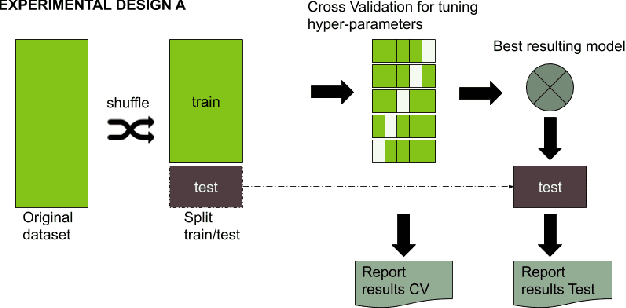
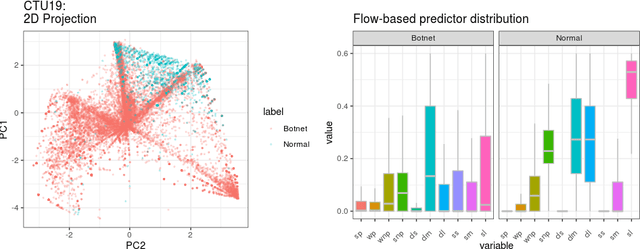
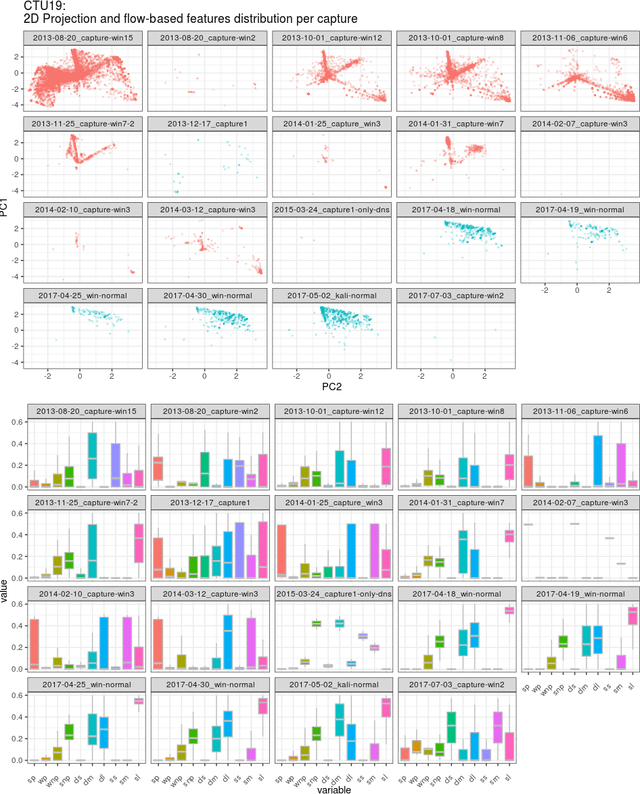
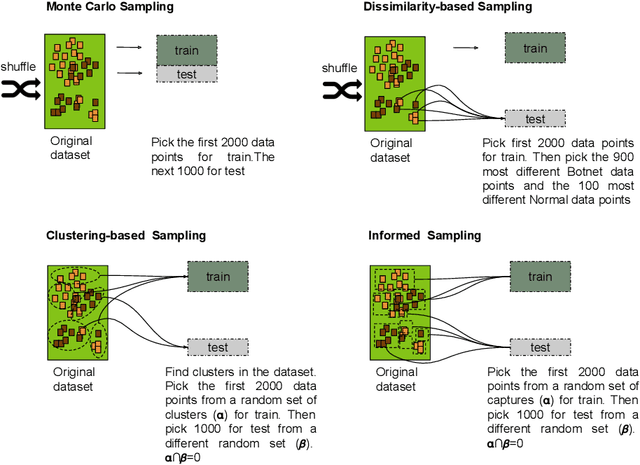
Even though a train/test split of the dataset randomly performed is a common practice, could not always be the best approach for estimating performance generalization under some scenarios. The fact is that the usual machine learning methodology can sometimes overestimate the generalization error when a dataset is not representative or when rare and elusive examples are a fundamental aspect of the detection problem. In the present work, we analyze strategies based on the predictors' variability to split in training and testing sets. Such strategies aim at guaranteeing the inclusion of rare or unusual examples with a minimal loss of the population's representativeness and provide a more accurate estimation about the generalization error when the dataset is not representative. Two baseline classifiers based on decision trees were used for testing the four splitting strategies considered. Both classifiers were applied on CTU19 a low-representative dataset for a network security detection problem. Preliminary results showed the importance of applying the three alternative strategies to the Monte Carlo splitting strategy in order to get a more accurate error estimation on different but feasible scenarios.
DNS Tunneling: A Deep Learning based Lexicographical Detection Approach
Jun 14, 2020
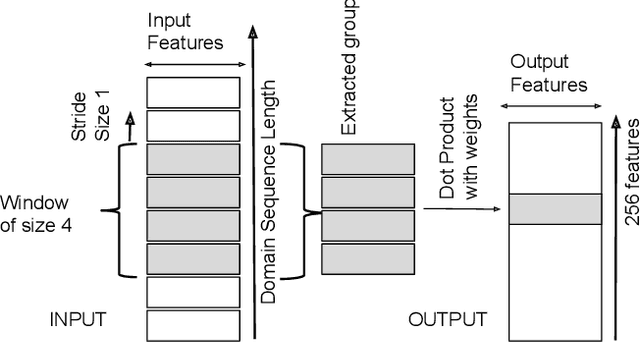


Domain Name Service is a trusted protocol made for name resolution, but during past years some approaches have been developed to use it for data transfer. DNS Tunneling is a method where data is encoded inside DNS queries, allowing information exchange through the DNS. This characteristic is attractive to hackers who exploit DNS Tunneling method to establish bidirectional communication with machines infected with malware with the objective of exfiltrating data or sending instructions in an obfuscated way. To detect these threats fast and accurately, the present work proposes a detection approach based on a Convolutional Neural Network (CNN) with a minimal architecture complexity. Due to the lack of quality datasets for evaluating DNS Tunneling connections, we also present a detailed construction and description of a novel dataset that contains DNS Tunneling domains generated with five well-known DNS tools. Despite its simple architecture, the resulting CNN model correctly detected more than 92% of total Tunneling domains with a false positive rate close to 0.8%.