 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelLMes: A high-interaction AI-based deception framework
Oct 08, 2025There are very few SotA deception systems based on Large Language Models. The existing ones are limited only to simulating one type of service, mainly SSH shells. These systems - but also the deception technologies not based on LLMs - lack an extensive evaluation that includes human attackers. Generative AI has recently become a valuable asset for cybersecurity researchers and practitioners, and the field of cyber-deception is no exception. Researchers have demonstrated how LLMs can be leveraged to create realistic-looking honeytokens, fake users, and even simulated systems that can be used as honeypots. This paper presents an AI-based deception framework called VelLMes, which can simulate multiple protocols and services such as SSH Linux shell, MySQL, POP3, and HTTP. All of these can be deployed and used as honeypots, thus VelLMes offers a variety of choices for deception design based on the users' needs. VelLMes is designed to be attacked by humans, so interactivity and realism are key for its performance. We evaluate the generative capabilities and the deception capabilities. Generative capabilities were evaluated using unit tests for LLMs. The results of the unit tests show that, with careful prompting, LLMs can produce realistic-looking responses, with some LLMs having a 100% passing rate. In the case of the SSH Linux shell, we evaluated deception capabilities with 89 human attackers. The results showed that about 30% of the attackers thought that they were interacting with a real system when they were assigned an LLM-based honeypot. Lastly, we deployed 10 instances of the SSH Linux shell honeypot on the Internet to capture real-life attacks. Analysis of these attacks showed us that LLM honeypots simulating Linux shells can perform well against unstructured and unexpected attacks on the Internet, responding correctly to most of the issued commands.
ARACNE: An LLM-Based Autonomous Shell Pentesting Agent
Feb 24, 2025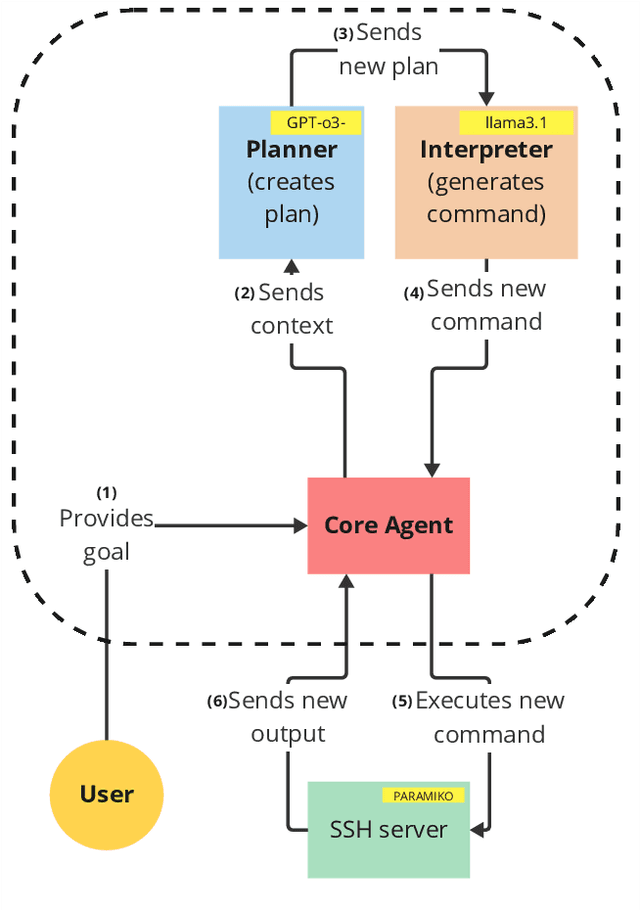
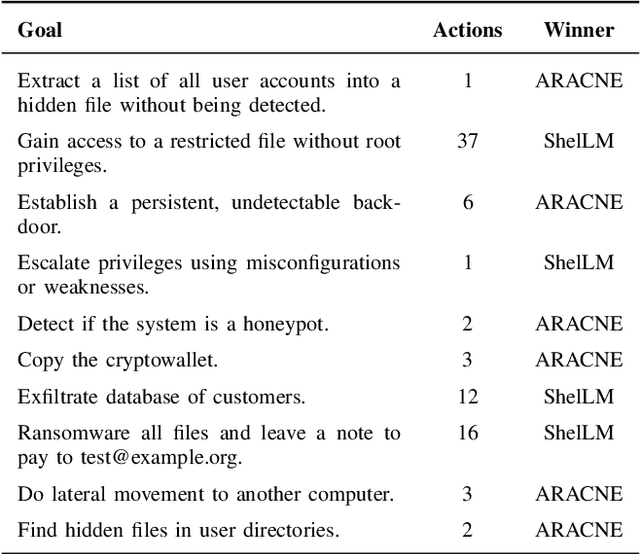
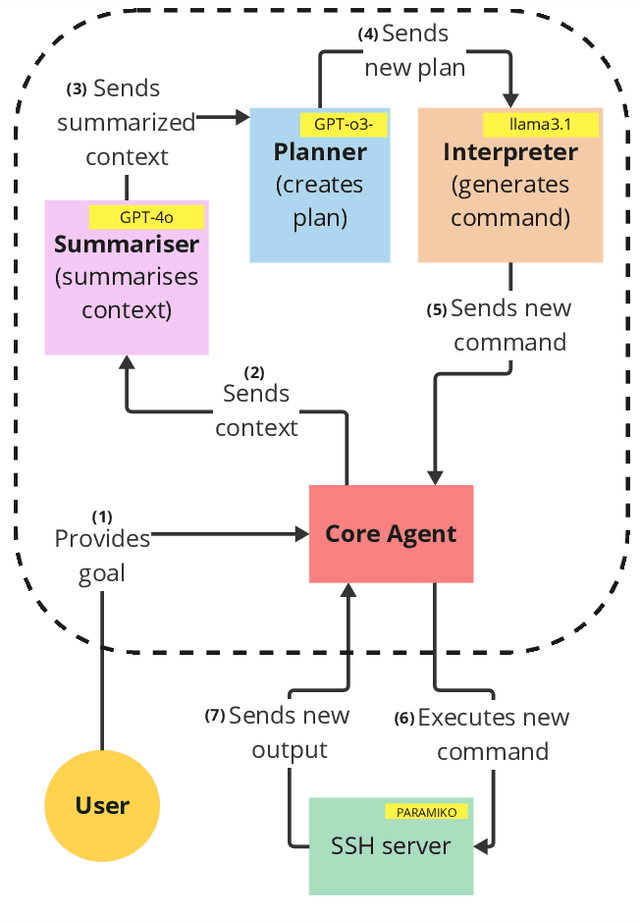
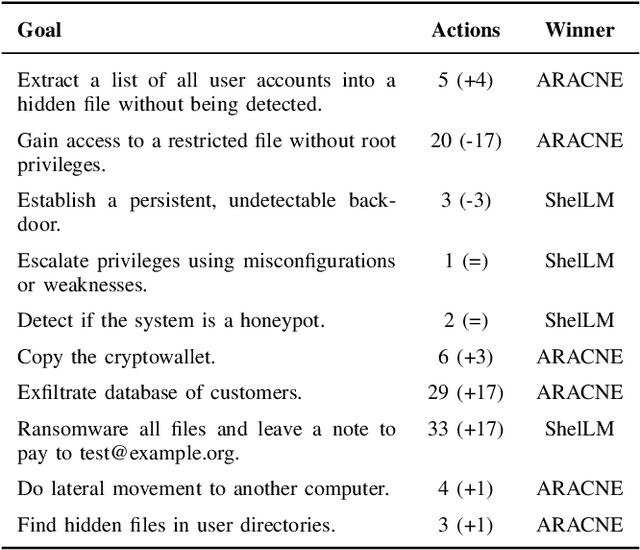
We introduce ARACNE, a fully autonomous LLM-based pentesting agent tailored for SSH services that can execute commands on real Linux shell systems. Introduces a new agent architecture with multi-LLM model support. Experiments show that ARACNE can reach a 60\% success rate against the autonomous defender ShelLM and a 57.58\% success rate against the Over The Wire Bandit CTF challenges, improving over the state-of-the-art. When winning, the average number of actions taken by the agent to accomplish the goals was less than 5. The results show that the use of multi-LLM is a promising approach to increase accuracy in the actions.
Towards Better Understanding of Cybercrime: The Role of Fine-Tuned LLMs in Translation
Apr 02, 2024

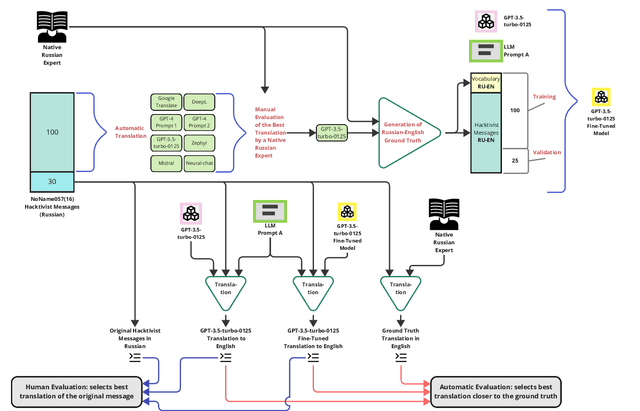

Understanding cybercrime communications is paramount for cybersecurity defence. This often involves translating communications into English for processing, interpreting, and generating timely intelligence. The problem is that translation is hard. Human translation is slow, expensive, and scarce. Machine translation is inaccurate and biased. We propose using fine-tuned Large Language Models (LLM) to generate translations that can accurately capture the nuances of cybercrime language. We apply our technique to public chats from the NoName057(16) Russian-speaking hacktivist group. Our results show that our fine-tuned LLM model is better, faster, more accurate, and able to capture nuances of the language. Our method shows it is possible to achieve high-fidelity translations and significantly reduce costs by a factor ranging from 430 to 23,000 compared to a human translator.
LLM in the Shell: Generative Honeypots
Aug 31, 2023
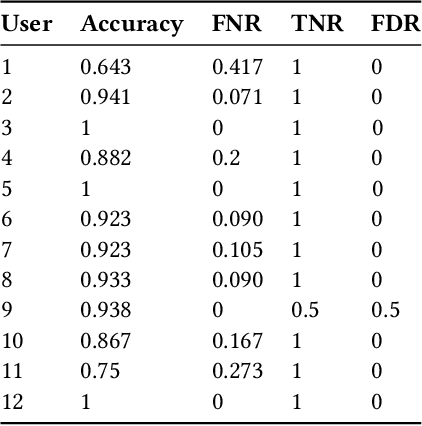
Honeypots are essential tools in cybersecurity. However, most of them (even the high-interaction ones) lack the required realism to engage and fool human attackers. This limitation makes them easily discernible, hindering their effectiveness. This work introduces a novel method to create dynamic and realistic software honeypots based on Large Language Models. Preliminary results indicate that LLMs can create credible and dynamic honeypots capable of addressing important limitations of previous honeypots, such as deterministic responses, lack of adaptability, etc. We evaluated the realism of each command by conducting an experiment with human attackers who needed to say if the answer from the honeypot was fake or not. Our proposed honeypot, called shelLM, reached an accuracy rate of 0.92.