 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Split for Assessing Statistical Model Performance
Sep 04, 2022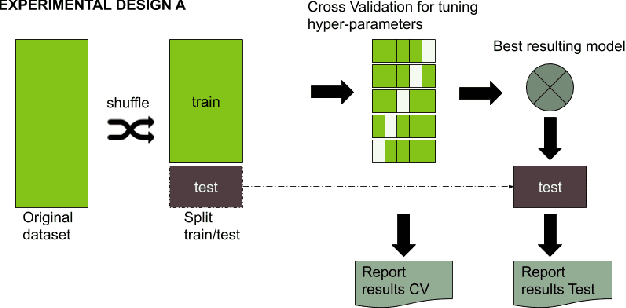
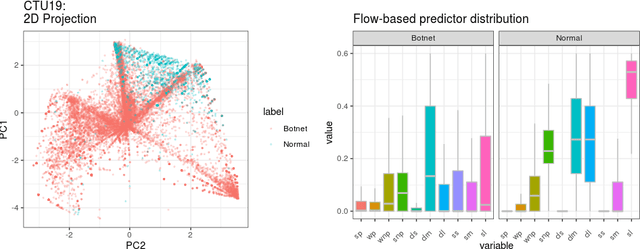
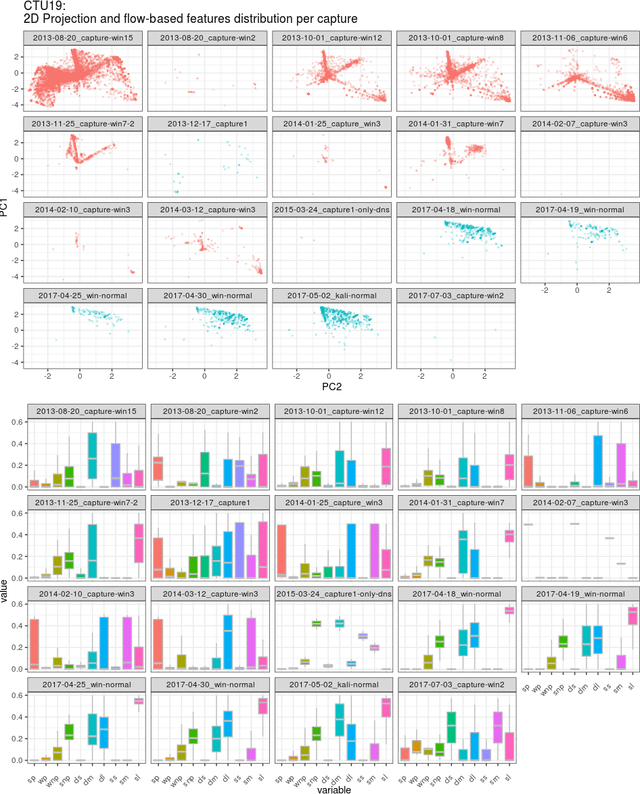
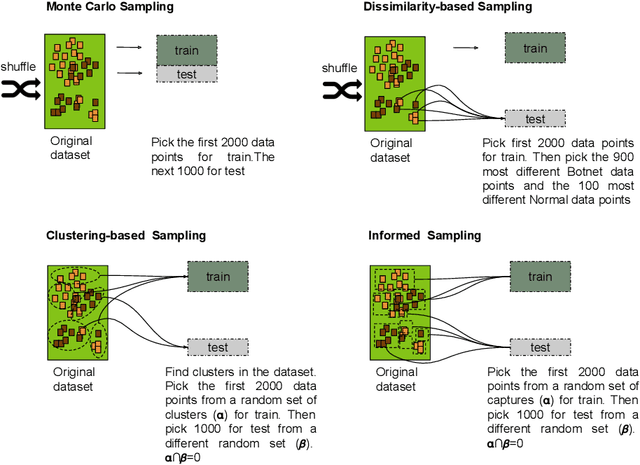
Even though a train/test split of the dataset randomly performed is a common practice, could not always be the best approach for estimating performance generalization under some scenarios. The fact is that the usual machine learning methodology can sometimes overestimate the generalization error when a dataset is not representative or when rare and elusive examples are a fundamental aspect of the detection problem. In the present work, we analyze strategies based on the predictors' variability to split in training and testing sets. Such strategies aim at guaranteeing the inclusion of rare or unusual examples with a minimal loss of the population's representativeness and provide a more accurate estimation about the generalization error when the dataset is not representative. Two baseline classifiers based on decision trees were used for testing the four splitting strategies considered. Both classifiers were applied on CTU19 a low-representative dataset for a network security detection problem. Preliminary results showed the importance of applying the three alternative strategies to the Monte Carlo splitting strategy in order to get a more accurate error estimation on different but feasible scenarios.