 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalicious Internet Entity Detection Using Local Graph Inference
Aug 07, 2024Detection of malicious behavior in a large network is a challenging problem for machine learning in computer security, since it requires a model with high expressive power and scalable inference. Existing solutions struggle to achieve this feat -- current cybersec-tailored approaches are still limited in expressivity, and methods successful in other domains do not scale well for large volumes of data, rendering frequent retraining impossible. This work proposes a new perspective for learning from graph data that is modeling network entity interactions as a large heterogeneous graph. High expressivity of the method is achieved with neural network architecture HMILnet that naturally models this type of data and provides theoretical guarantees. The scalability is achieved by pursuing local graph inference, i.e., classifying individual vertices and their neighborhood as independent samples. Our experiments exhibit improvement over the state-of-the-art Probabilistic Threat Propagation (PTP) algorithm, show a further threefold accuracy improvement when additional data is used, which is not possible with the PTP algorithm, and demonstrate the generalization capabilities of the method to new, previously unseen entities.
Generating Likely Counterfactuals Using Sum-Product Networks
Jan 25, 2024



Due to user demand and recent regulation (GDPR, AI Act), decisions made by AI systems need to be explained. These decisions are often explainable only post hoc, where counterfactual explanations are popular. The question of what constitutes the best counterfactual explanation must consider multiple aspects, where "distance from the sample" is the most common. We argue that this requirement frequently leads to explanations that are unlikely and, therefore, of limited value. Here, we present a system that provides high-likelihood explanations. We show that the search for the most likely explanations satisfying many common desiderata for counterfactual explanations can be modeled using mixed-integer optimization (MIO). In the process, we propose an MIO formulation of a Sum-Product Network (SPN) and use the SPN to estimate the likelihood of a counterfactual, which can be of independent interest. A numerical comparison against several methods for generating counterfactual explanations is provided.
Improving the Validity of Decision Trees as Explanations
Jun 13, 2023



In classification and forecasting with tabular data, one often utilizes tree-based models. This can be competitive with deep neural networks on tabular data [cf. Grinsztajn et al., NeurIPS 2022, arXiv:2207.08815] and, under some conditions, explainable. The explainability depends on the depth of the tree and the accuracy in each leaf of the tree. Here, we train a low-depth tree with the objective of minimising the maximum misclassification error across each leaf node, and then ``suspend'' further tree-based models (e.g., trees of unlimited depth) from each leaf of the low-depth tree. The low-depth tree is easily explainable, while the overall statistical performance of the combined low-depth and suspended tree-based models improves upon decision trees of unlimited depth trained using classical methods (e.g., CART) and is comparable to state-of-the-art methods (e.g., well-tuned XGBoost).
A Differentiable Loss Function for Learning Heuristics in A*
Sep 12, 2022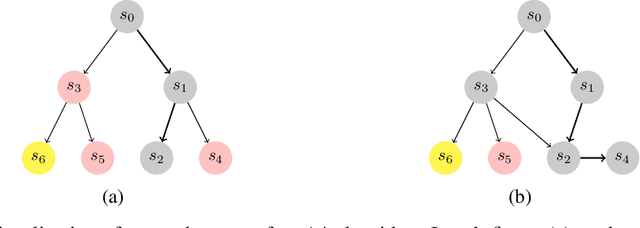
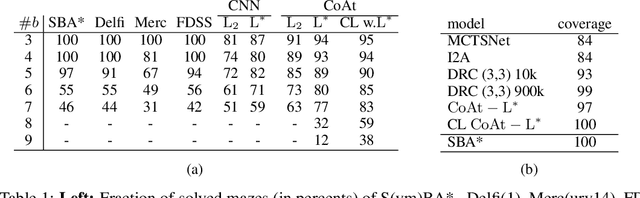
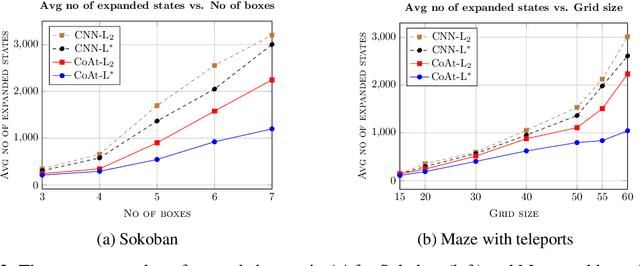
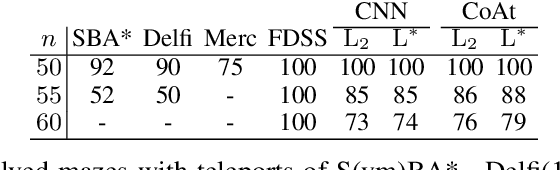
Optimization of heuristic functions for the A* algorithm, realized by deep neural networks, is usually done by minimizing square root loss of estimate of the cost to goal values. This paper argues that this does not necessarily lead to a faster search of A* algorithm since its execution relies on relative values instead of absolute ones. As a mitigation, we propose a L* loss, which upper-bounds the number of excessively expanded states inside the A* search. The L* loss, when used in the optimization of state-of-the-art deep neural networks for automated planning in maze domains like Sokoban and maze with teleports, significantly improves the fraction of solved problems, the quality of founded plans, and reduces the number of expanded states to approximately 50%
Heuristic Search Planning with Deep Neural Networks using Imitation, Attention and Curriculum Learning
Dec 03, 2021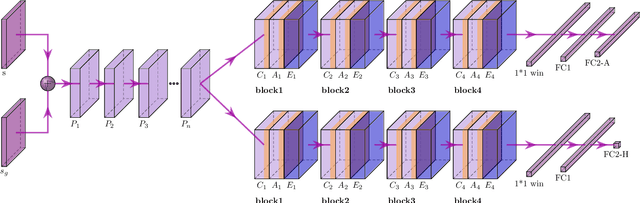
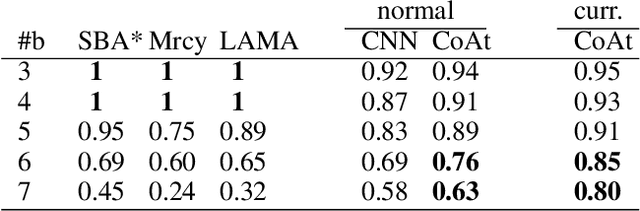
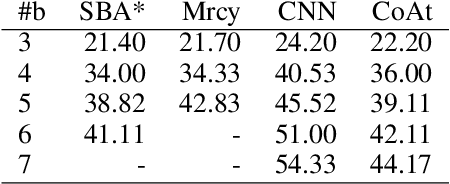
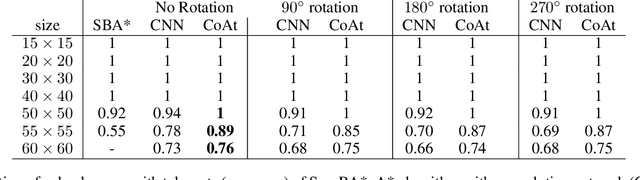
Learning a well-informed heuristic function for hard task planning domains is an elusive problem. Although there are known neural network architectures to represent such heuristic knowledge, it is not obvious what concrete information is learned and whether techniques aimed at understanding the structure help in improving the quality of the heuristics. This paper presents a network model to learn a heuristic capable of relating distant parts of the state space via optimal plan imitation using the attention mechanism, which drastically improves the learning of a good heuristic function. To counter the limitation of the method in the creation of problems of increasing difficulty, we demonstrate the use of curriculum learning, where newly solved problem instances are added to the training set, which, in turn, helps to solve problems of higher complexities and far exceeds the performances of all existing baselines including classical planning heuristics. We demonstrate its effectiveness for grid-type PDDL domains.
When Should You Defend Your Classifier -- A Game-theoretical Analysis of Countermeasures against Adversarial Examples
Aug 17, 2021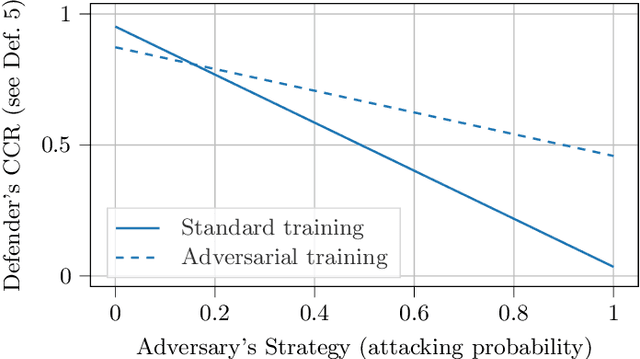
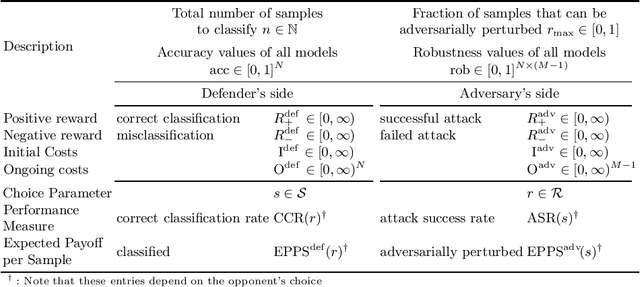

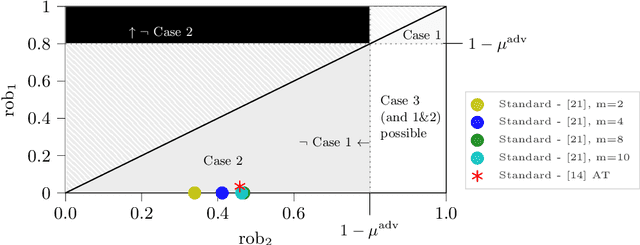
Adversarial machine learning, i.e., increasing the robustness of machine learning algorithms against so-called adversarial examples, is now an established field. Yet, newly proposed methods are evaluated and compared under unrealistic scenarios where costs for adversary and defender are not considered and either all samples are attacked or no sample is attacked. We scrutinize these assumptions and propose the advanced adversarial classification game, which incorporates all relevant parameters of an adversary and a defender in adversarial classification. Especially, we take into account economic factors on both sides and the fact that all so far proposed countermeasures against adversarial examples reduce accuracy on benign samples. Analyzing the scenario in detail, where both players have two pure strategies, we identify all best responses and conclude that in practical settings, the most influential factor might be the maximum amount of adversarial examples.
Mill.jl and JsonGrinder.jl: automated differentiable feature extraction for learning from raw JSON data
May 19, 2021

Learning from raw data input, thus limiting the need for manual feature engineering, is one of the key components of many successful applications of machine learning methods. While machine learning problems are often formulated on data that naturally translate into a vector representation suitable for classifiers, there are data sources, for example in cybersecurity, that are naturally represented in diverse files with a unifying hierarchical structure, such as XML, JSON, and Protocol Buffers. Converting this data to vector (tensor) representation is generally done by manual feature engineering, which is laborious, lossy, and prone to human bias about the importance of particular features. Mill and JsonGrinder is a tandem of libraries, which fully automates the conversion. Starting with an arbitrary set of JSON samples, they create a differentiable machine learning model capable of infer from further JSON samples in their raw form.
Sum-Product-Transform Networks: Exploiting Symmetries using Invertible Transformations
May 04, 2020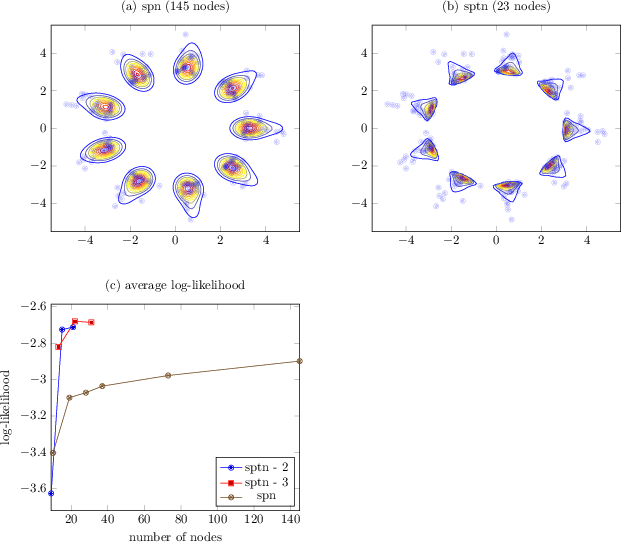
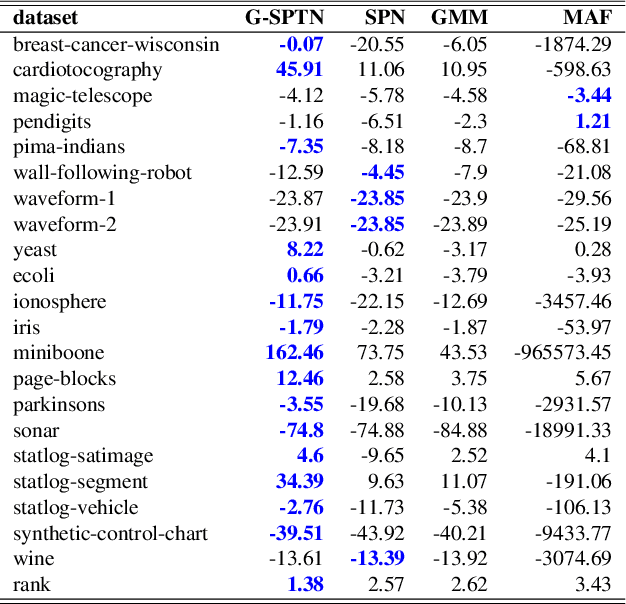
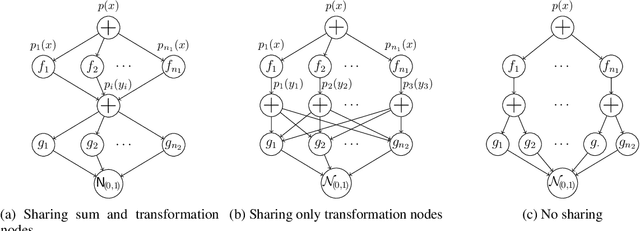

In this work, we propose Sum-Product-Transform Networks (SPTN), an extension of sum-product networks that uses invertible transformations as additional internal nodes. The type and placement of transformations determine properties of the resulting SPTN with many interesting special cases. Importantly, SPTN with Gaussian leaves and affine transformations pose the same inference task tractable that can be computed efficiently in SPNs. We propose to store affine transformations in their SVD decompositions using an efficient parametrization of unitary matrices by a set of Givens rotations. Last but not least, we demonstrate that G-SPTNs achieve state-of-the-art results on the density estimation task and are competitive with state-of-the-art methods for anomaly detection.
Joint Detection of Malicious Domains and Infected Clients
Jun 21, 2019


Detection of malware-infected computers and detection of malicious web domains based on their encrypted HTTPS traffic are challenging problems, because only addresses, timestamps, and data volumes are observable. The detection problems are coupled, because infected clients tend to interact with malicious domains. Traffic data can be collected at a large scale, and antivirus tools can be used to identify infected clients in retrospect. Domains, by contrast, have to be labeled individually after forensic analysis. We explore transfer learning based on sluice networks; this allows the detection models to bootstrap each other. In a large-scale experimental study, we find that the model outperforms known reference models and detects previously unknown malware, previously unknown malware families, and previously unknown malicious domains.
Approximation capability of neural networks on spaces of probability measures and tree-structured domains
Jun 03, 2019
This paper extends the proof of density of neural networks in the space of continuous (or even measurable) functions on Euclidean spaces to functions on compact sets of probability measures. By doing so the work parallels a more then a decade old results on mean-map embedding of probability measures in reproducing kernel Hilbert spaces. The work has wide practical consequences for multi-instance learning, where it theoretically justifies some recently proposed constructions. The result is then extended to Cartesian products, yielding universal approximation theorem for tree-structured domains, which naturally occur in data-exchange formats like JSON, XML, YAML, AVRO, and ProtoBuffer. This has important practical implications, as it enables to automatically create an architecture of neural networks for processing structured data (AutoML paradigms), as demonstrated by an accompanied library for JSON format.