 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyettention II: A Dual-Sequence Architecture for Modeling Fixation Location, Within-Word Landing Position, and Fixation Duration in Reading
Jun 01, 2026The way our eyes move while reading provides valuable insights into both the reader's cognitive processes and the properties of the text. In particular, eye-tracking-while-reading data has shown to be highly beneficial in various technological applications, such as enhancing and interpreting language models and inferring a reader's characteristics. However, these applications often rely on large-scale, data-driven models, which demand extensive eye-tracking datasets that are challenging to obtain due to the resource-intensive nature of data collection. To address the challenge of data scarcity, we develop Eyettention II, an end-to-end trained deep-learning model capable of generating realistic scanpaths consisting of a complete set of fixation attributes in chronological order, including fixation location, within-word landing position, and fixation duration. Our model is lightweight, efficiently trainable on limited GPU resources, and closely aligned with cognitive theories. We demonstrate that Eyettention II surpasses state-of-the-art models in scanpath prediction and mirrors human-like gaze behavior by capturing key psycholinguistic phenomena. With its robust performance, Eyettention II holds the potential to drive advancements in natural language processing, facilitate piloting the materials of psycholinguistic experiments, and uncover new insights beyond what is explicitly encoded in theoretical cognitive models.
Eye-Tracking-while-Reading: A Living Survey of Datasets with Open Library Support
Feb 23, 2026Eye-tracking-while-reading corpora are a valuable resource for many different disciplines and use cases. Use cases range from studying the cognitive processes underlying reading to machine-learning-based applications, such as gaze-based assessments of reading comprehension. The past decades have seen an increase in the number and size of eye-tracking-while-reading datasets as well as increasing diversity with regard to the stimulus languages covered, the linguistic background of the participants, or accompanying psychometric or demographic data. The spread of data across different disciplines and the lack of data sharing standards across the communities lead to many existing datasets that cannot be easily reused due to a lack of interoperability. In this work, we aim at creating more transparency and clarity with regards to existing datasets and their features across different disciplines by i) presenting an extensive overview of existing datasets, ii) simplifying the sharing of newly created datasets by publishing a living overview online, https://dili-lab.github.io/datasets.html, presenting over 45 features for each dataset, and iii) integrating all publicly available datasets into the Python package pymovements which offers an eye-tracking datasets library. By doing so, we aim to strengthen the FAIR principles in eye-tracking-while-reading research and promote good scientific practices, such as reproducing and replicating studies.
ScanDL: A Diffusion Model for Generating Synthetic Scanpaths on Texts
Oct 24, 2023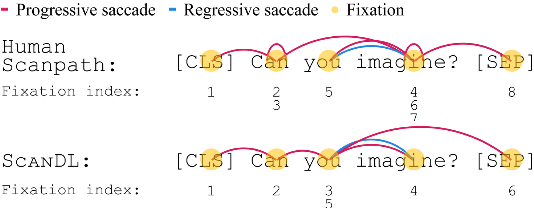
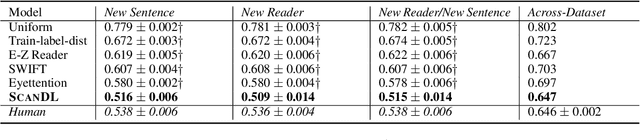


Eye movements in reading play a crucial role in psycholinguistic research studying the cognitive mechanisms underlying human language processing. More recently, the tight coupling between eye movements and cognition has also been leveraged for language-related machine learning tasks such as the interpretability, enhancement, and pre-training of language models, as well as the inference of reader- and text-specific properties. However, scarcity of eye movement data and its unavailability at application time poses a major challenge for this line of research. Initially, this problem was tackled by resorting to cognitive models for synthesizing eye movement data. However, for the sole purpose of generating human-like scanpaths, purely data-driven machine-learning-based methods have proven to be more suitable. Following recent advances in adapting diffusion processes to discrete data, we propose ScanDL, a novel discrete sequence-to-sequence diffusion model that generates synthetic scanpaths on texts. By leveraging pre-trained word representations and jointly embedding both the stimulus text and the fixation sequence, our model captures multi-modal interactions between the two inputs. We evaluate ScanDL within- and across-dataset and demonstrate that it significantly outperforms state-of-the-art scanpath generation methods. Finally, we provide an extensive psycholinguistic analysis that underlines the model's ability to exhibit human-like reading behavior. Our implementation is made available at https://github.com/DiLi-Lab/ScanDL.
Pre-Trained Language Models Augmented with Synthetic Scanpaths for Natural Language Understanding
Oct 23, 2023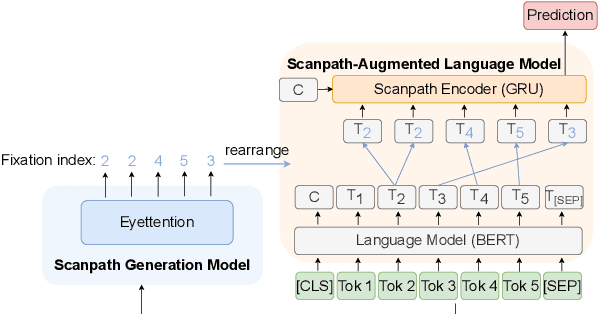
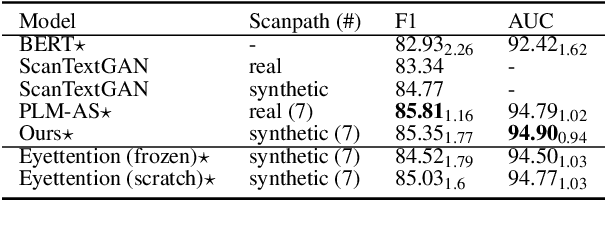
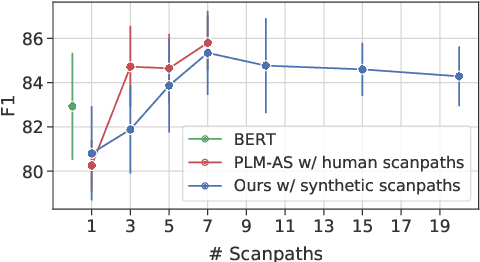
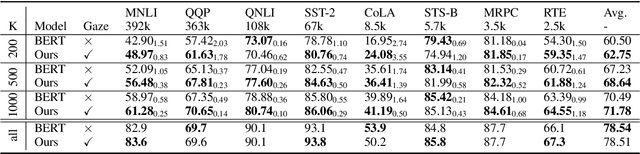
Human gaze data offer cognitive information that reflects natural language comprehension. Indeed, augmenting language models with human scanpaths has proven beneficial for a range of NLP tasks, including language understanding. However, the applicability of this approach is hampered because the abundance of text corpora is contrasted by a scarcity of gaze data. Although models for the generation of human-like scanpaths during reading have been developed, the potential of synthetic gaze data across NLP tasks remains largely unexplored. We develop a model that integrates synthetic scanpath generation with a scanpath-augmented language model, eliminating the need for human gaze data. Since the model's error gradient can be propagated throughout all parts of the model, the scanpath generator can be fine-tuned to downstream tasks. We find that the proposed model not only outperforms the underlying language model, but achieves a performance that is comparable to a language model augmented with real human gaze data. Our code is publicly available.
Eyettention: An Attention-based Dual-Sequence Model for Predicting Human Scanpaths during Reading
Apr 21, 2023Eye movements during reading offer insights into both the reader's cognitive processes and the characteristics of the text that is being read. Hence, the analysis of scanpaths in reading have attracted increasing attention across fields, ranging from cognitive science over linguistics to computer science. In particular, eye-tracking-while-reading data has been argued to bear the potential to make machine-learning-based language models exhibit a more human-like linguistic behavior. However, one of the main challenges in modeling human scanpaths in reading is their dual-sequence nature: the words are ordered following the grammatical rules of the language, whereas the fixations are chronologically ordered. As humans do not strictly read from left-to-right, but rather skip or refixate words and regress to previous words, the alignment of the linguistic and the temporal sequence is non-trivial. In this paper, we develop Eyettention, the first dual-sequence model that simultaneously processes the sequence of words and the chronological sequence of fixations. The alignment of the two sequences is achieved by a cross-sequence attention mechanism. We show that Eyettention outperforms state-of-the-art models in predicting scanpaths. We provide an extensive within- and across-data set evaluation on different languages. An ablation study and qualitative analysis support an in-depth understanding of the model's behavior.
Bridging the Gap: Gaze Events as Interpretable Concepts to Explain Deep Neural Sequence Models
Apr 12, 2023



Recent work in XAI for eye tracking data has evaluated the suitability of feature attribution methods to explain the output of deep neural sequence models for the task of oculomotric biometric identification. These methods provide saliency maps to highlight important input features of a specific eye gaze sequence. However, to date, its localization analysis has been lacking a quantitative approach across entire datasets. In this work, we employ established gaze event detection algorithms for fixations and saccades and quantitatively evaluate the impact of these events by determining their concept influence. Input features that belong to saccades are shown to be substantially more important than features that belong to fixations. By dissecting saccade events into sub-events, we are able to show that gaze samples that are close to the saccadic peak velocity are most influential. We further investigate the effect of event properties like saccadic amplitude or fixational dispersion on the resulting concept influence.
Detection of ADHD based on Eye Movements during Natural Viewing
Jul 14, 2022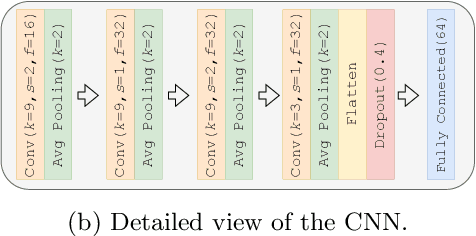

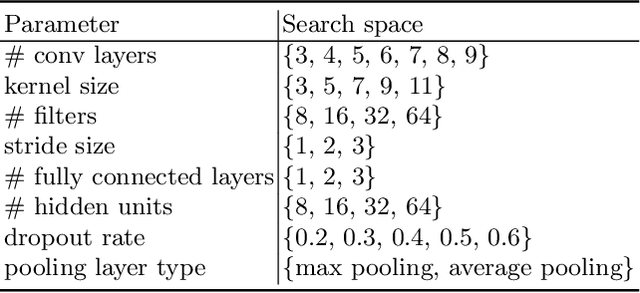
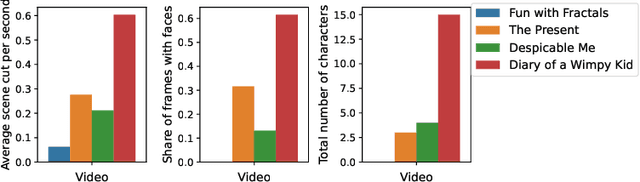
Attention-deficit/hyperactivity disorder (ADHD) is a neurodevelopmental disorder that is highly prevalent and requires clinical specialists to diagnose. It is known that an individual's viewing behavior, reflected in their eye movements, is directly related to attentional mechanisms and higher-order cognitive processes. We therefore explore whether ADHD can be detected based on recorded eye movements together with information about the video stimulus in a free-viewing task. To this end, we develop an end-to-end deep learning-based sequence model which we pre-train on a related task for which more data are available. We find that the method is in fact able to detect ADHD and outperforms relevant baselines. We investigate the relevance of the input features in an ablation study. Interestingly, we find that the model's performance is closely related to the content of the video, which provides insights for future experimental designs.
Learning Explainable Representations of Malware Behavior
Jun 23, 2021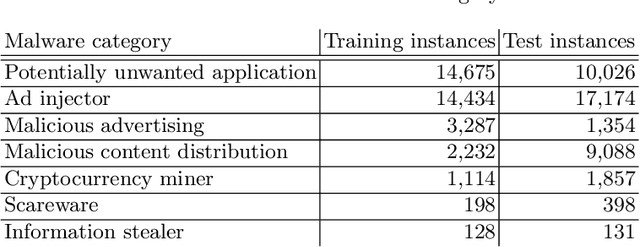
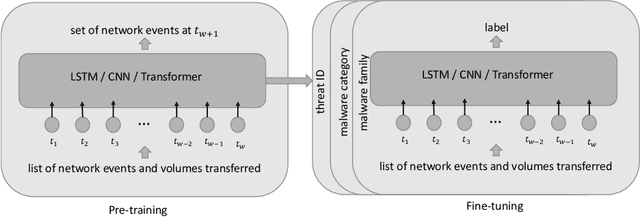

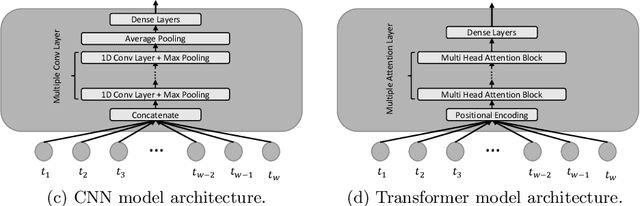
We address the problems of identifying malware in network telemetry logs and providing \emph{indicators of compromise} -- comprehensible explanations of behavioral patterns that identify the threat. In our system, an array of specialized detectors abstracts network-flow data into comprehensible \emph{network events} in a first step. We develop a neural network that processes this sequence of events and identifies specific threats, malware families and broad categories of malware. We then use the \emph{integrated-gradients} method to highlight events that jointly constitute the characteristic behavioral pattern of the threat. We compare network architectures based on CNNs, LSTMs, and transformers, and explore the efficacy of unsupervised pre-training experimentally on large-scale telemetry data. We demonstrate how this system detects njRAT and other malware based on behavioral patterns.
Deep Eyedentification: Biometric Identification using Micro-Movements of the Eye
Jul 04, 2019

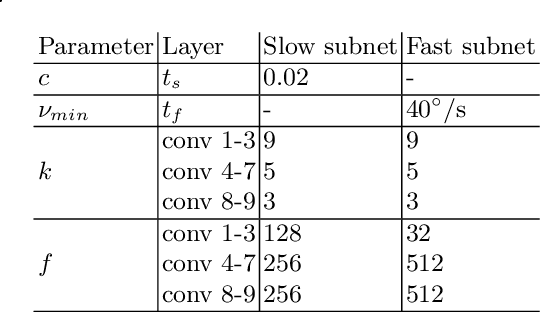
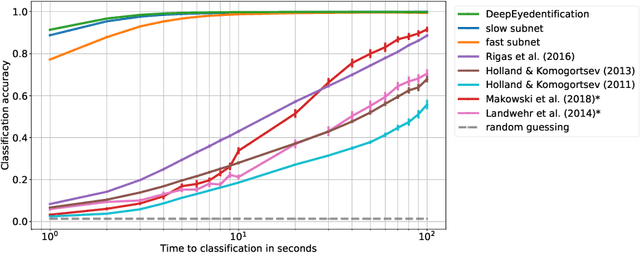
We study involuntary micro-movements of the eye for biometric identification. While prior studies extract lower-frequency macro-movements from the output of video-based eye-tracking systems and engineer explicit features of these macro-movements, we develop a deep convolutional architecture that processes the raw eye-tracking signal. Compared to prior work, the network attains a lower error rate by one order of magnitude and is faster by two orders of magnitude: it identifies users accurately within seconds.
Joint Detection of Malicious Domains and Infected Clients
Jun 21, 2019


Detection of malware-infected computers and detection of malicious web domains based on their encrypted HTTPS traffic are challenging problems, because only addresses, timestamps, and data volumes are observable. The detection problems are coupled, because infected clients tend to interact with malicious domains. Traffic data can be collected at a large scale, and antivirus tools can be used to identify infected clients in retrospect. Domains, by contrast, have to be labeled individually after forensic analysis. We explore transfer learning based on sluice networks; this allows the detection models to bootstrap each other. In a large-scale experimental study, we find that the model outperforms known reference models and detects previously unknown malware, previously unknown malware families, and previously unknown malicious domains.