 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained Language Models Augmented with Synthetic Scanpaths for Natural Language Understanding
Oct 23, 2023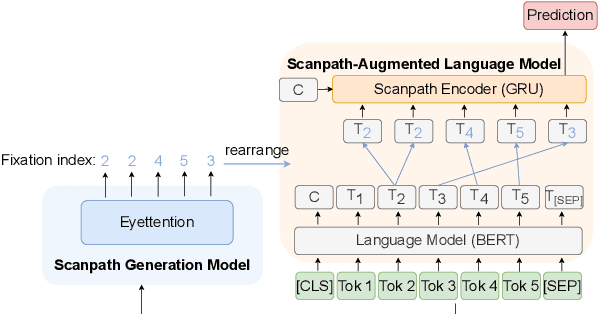
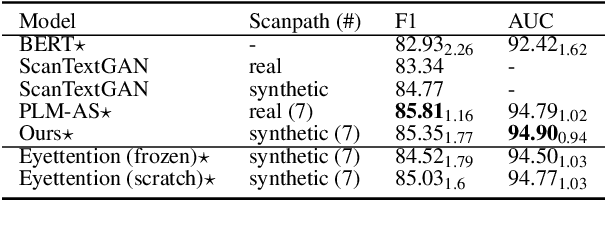
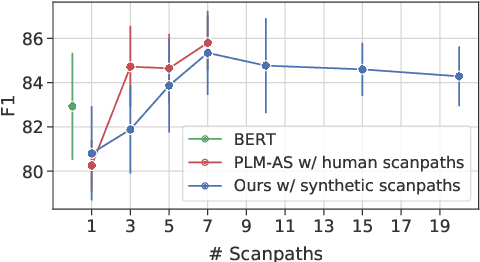
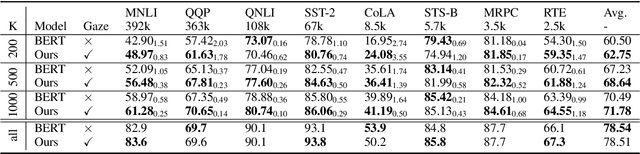
Human gaze data offer cognitive information that reflects natural language comprehension. Indeed, augmenting language models with human scanpaths has proven beneficial for a range of NLP tasks, including language understanding. However, the applicability of this approach is hampered because the abundance of text corpora is contrasted by a scarcity of gaze data. Although models for the generation of human-like scanpaths during reading have been developed, the potential of synthetic gaze data across NLP tasks remains largely unexplored. We develop a model that integrates synthetic scanpath generation with a scanpath-augmented language model, eliminating the need for human gaze data. Since the model's error gradient can be propagated throughout all parts of the model, the scanpath generator can be fine-tuned to downstream tasks. We find that the proposed model not only outperforms the underlying language model, but achieves a performance that is comparable to a language model augmented with real human gaze data. Our code is publicly available.
Eyettention: An Attention-based Dual-Sequence Model for Predicting Human Scanpaths during Reading
Apr 21, 2023Eye movements during reading offer insights into both the reader's cognitive processes and the characteristics of the text that is being read. Hence, the analysis of scanpaths in reading have attracted increasing attention across fields, ranging from cognitive science over linguistics to computer science. In particular, eye-tracking-while-reading data has been argued to bear the potential to make machine-learning-based language models exhibit a more human-like linguistic behavior. However, one of the main challenges in modeling human scanpaths in reading is their dual-sequence nature: the words are ordered following the grammatical rules of the language, whereas the fixations are chronologically ordered. As humans do not strictly read from left-to-right, but rather skip or refixate words and regress to previous words, the alignment of the linguistic and the temporal sequence is non-trivial. In this paper, we develop Eyettention, the first dual-sequence model that simultaneously processes the sequence of words and the chronological sequence of fixations. The alignment of the two sequences is achieved by a cross-sequence attention mechanism. We show that Eyettention outperforms state-of-the-art models in predicting scanpaths. We provide an extensive within- and across-data set evaluation on different languages. An ablation study and qualitative analysis support an in-depth understanding of the model's behavior.
Detection of ADHD based on Eye Movements during Natural Viewing
Jul 14, 2022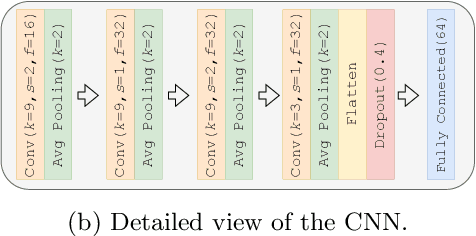

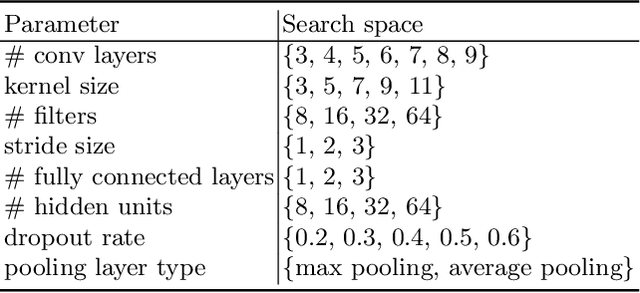
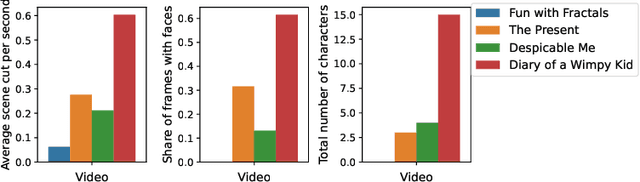
Attention-deficit/hyperactivity disorder (ADHD) is a neurodevelopmental disorder that is highly prevalent and requires clinical specialists to diagnose. It is known that an individual's viewing behavior, reflected in their eye movements, is directly related to attentional mechanisms and higher-order cognitive processes. We therefore explore whether ADHD can be detected based on recorded eye movements together with information about the video stimulus in a free-viewing task. To this end, we develop an end-to-end deep learning-based sequence model which we pre-train on a related task for which more data are available. We find that the method is in fact able to detect ADHD and outperforms relevant baselines. We investigate the relevance of the input features in an ablation study. Interestingly, we find that the model's performance is closely related to the content of the video, which provides insights for future experimental designs.