 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular and Adaptive System for Business Email Compromise Detection
Aug 21, 2023



The growing sophistication of Business Email Compromise (BEC) and spear phishing attacks poses significant challenges to organizations worldwide. The techniques featured in traditional spam and phishing detection are insufficient due to the tailored nature of modern BEC attacks as they often blend in with the regular benign traffic. Recent advances in machine learning, particularly in Natural Language Understanding (NLU), offer a promising avenue for combating such attacks but in a practical system, due to limitations such as data availability, operational costs, verdict explainability requirements or a need to robustly evolve the system, it is essential to combine multiple approaches together. We present CAPE, a comprehensive and efficient system for BEC detection that has been proven in a production environment for a period of over two years. Rather than being a single model, CAPE is a system that combines independent ML models and algorithms detecting BEC-related behaviors across various email modalities such as text, images, metadata and the email's communication context. This decomposition makes CAPE's verdicts naturally explainable. In the paper, we describe the design principles and constraints behind its architecture, as well as the challenges of model design, evaluation and adapting the system continuously through a Bayesian approach that combines limited data with domain knowledge. Furthermore, we elaborate on several specific behavioral detectors, such as those based on Transformer neural architectures.
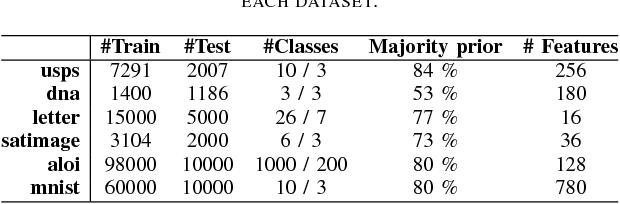
Benchmark of Data Preprocessing Methods for Imbalanced Classification
Mar 06, 2023



Severe class imbalance is one of the main conditions that make machine learning in cybersecurity difficult. A variety of dataset preprocessing methods have been introduced over the years. These methods modify the training dataset by oversampling, undersampling or a combination of both to improve the predictive performance of classifiers trained on this dataset. Although these methods are used in cybersecurity occasionally, a comprehensive, unbiased benchmark comparing their performance over a variety of cybersecurity problems is missing. This paper presents a benchmark of 16 preprocessing methods on six cybersecurity datasets together with 17 public imbalanced datasets from other domains. We test the methods under multiple hyperparameter configurations and use an AutoML system to train classifiers on the preprocessed datasets, which reduces potential bias from specific hyperparameter or classifier choices. Special consideration is also given to evaluating the methods using appropriate performance measures that are good proxies for practical performance in real-world cybersecurity systems. The main findings of our study are: 1) Most of the time, a data preprocessing method that improves classification performance exists. 2) Baseline approach of doing nothing outperformed a large portion of methods in the benchmark. 3) Oversampling methods generally outperform undersampling methods. 4) The most significant performance gains are brought by the standard SMOTE algorithm and more complicated methods provide mainly incremental improvements at the cost of often worse computational performance.
A framework for comprehensible multi-modal detection of cyber threats
Nov 10, 2021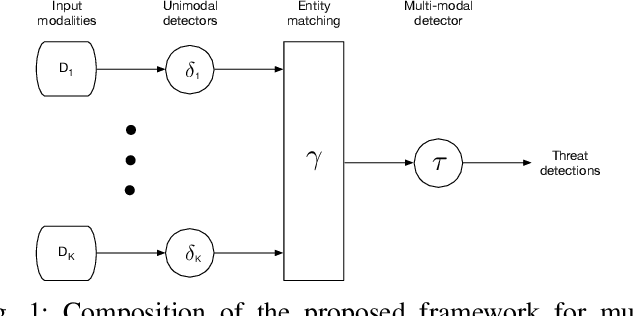
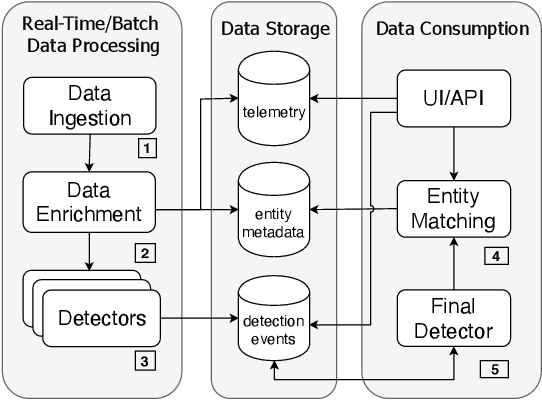
Detection of malicious activities in corporate environments is a very complex task and much effort has been invested into research of its automation. However, vast majority of existing methods operate only in a narrow scope which limits them to capture only fragments of the evidence of malware's presence. Consequently, such approach is not aligned with the way how the cyber threats are studied and described by domain experts. In this work, we discuss these limitations and design a detection framework which combines observed events from different sources of data. Thanks to this, it provides full insight into the attack life cycle and enables detection of threats that require this coupling of observations from different telemetries to identify the full scope of the incident. We demonstrate applicability of the framework on a case study of a real malware infection observed in a corporate network.
Decision-forest voting scheme for classification of rare classes in network intrusion detection
Jul 25, 2021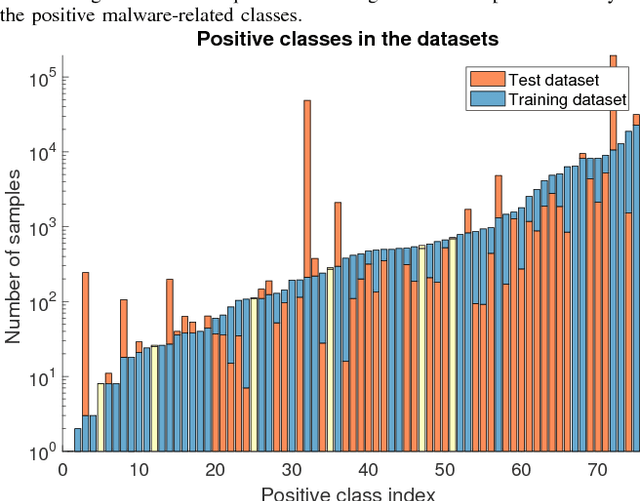


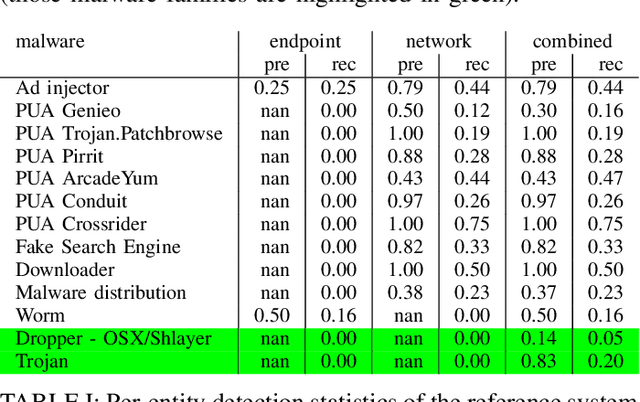
In this paper, Bayesian based aggregation of decision trees in an ensemble (decision forest) is investigated. The focus is laid on multi-class classification with number of samples significantly skewed toward one of the classes. The algorithm leverages out-of-bag datasets to estimate prediction errors of individual trees, which are then used in accordance with the Bayes rule to refine the decision of the ensemble. The algorithm takes prevalence of individual classes into account and does not require setting of any additional parameters related to class weights or decision-score thresholds. Evaluation is based on publicly available datasets as well as on an proprietary dataset comprising network traffic telemetry from hundreds of enterprise networks with over a million of users overall. The aim is to increase the detection capabilities of an operating malware detection system. While we were able to keep precision of the system higher than 94\%, that is only 6 out of 100 detections shown to the network administrator are false alarms, we were able to achieve increase of approximately 7\% in the number of detections. The algorithm effectively handles large amounts of data, and can be used in conjunction with most of the state-of-the-art algorithms used to train decision forests.
* \copyright 2018 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Learning Explainable Representations of Malware Behavior
Jun 23, 2021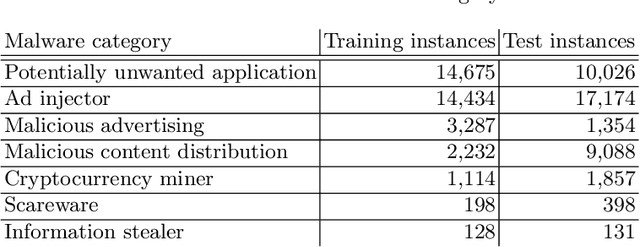
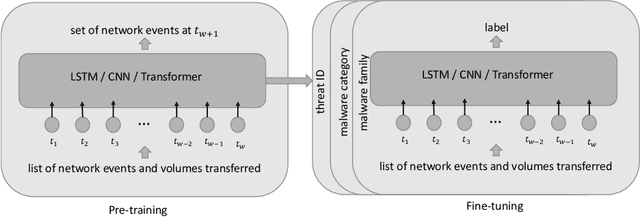

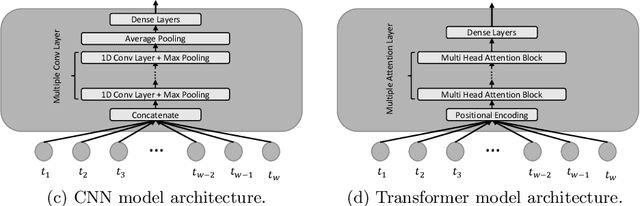
We address the problems of identifying malware in network telemetry logs and providing \emph{indicators of compromise} -- comprehensible explanations of behavioral patterns that identify the threat. In our system, an array of specialized detectors abstracts network-flow data into comprehensible \emph{network events} in a first step. We develop a neural network that processes this sequence of events and identifies specific threats, malware families and broad categories of malware. We then use the \emph{integrated-gradients} method to highlight events that jointly constitute the characteristic behavioral pattern of the threat. We compare network architectures based on CNNs, LSTMs, and transformers, and explore the efficacy of unsupervised pre-training experimentally on large-scale telemetry data. We demonstrate how this system detects njRAT and other malware based on behavioral patterns.
On Model Evaluation under Non-constant Class Imbalance
Jan 15, 2020

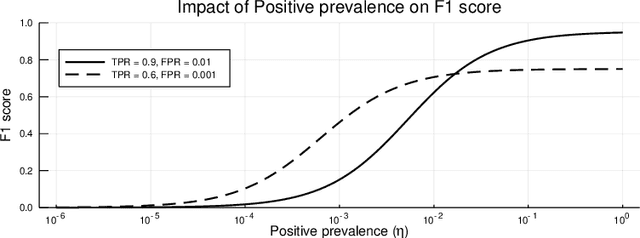
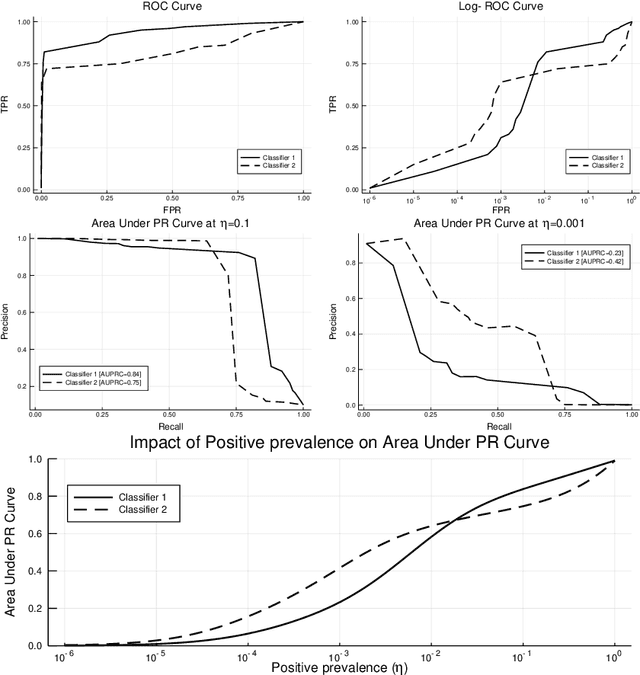
Many real-world classification problems are significantly class-imbalanced to detriment of the class of interest. The standard set of proper evaluation metrics is well-known but the usual assumption is that the test dataset imbalance equals the real-world imbalance. In practice, this assumption is often broken for various reasons. The reported results are then often too optimistic and may lead to wrong conclusions about industrial impact and suitability of proposed techniques. We introduce methods focusing on evaluation under non-constant class imbalance. We show that not only the absolute values of commonly used metrics, but even the order of classifiers in relation to the evaluation metric used is affected by the change of the imbalance rate. Finally, we demonstrate that using subsampling in order to get a test dataset with class imbalance equal to the one observed in the wild is not necessary, and eventually can lead to significant errors in classifier's performance estimate.
Bad practices in evaluation methodology relevant to class-imbalanced problems
Dec 04, 2018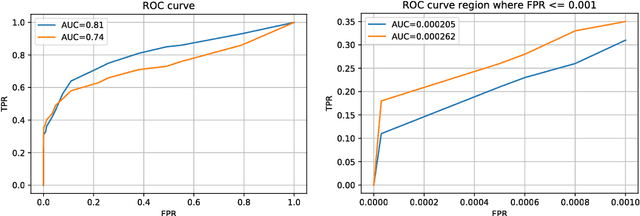
For research to go in the right direction, it is essential to be able to compare and quantify performance of different algorithms focused on the same problem. Choosing a suitable evaluation metric requires deep understanding of the pursued task along with all of its characteristics. We argue that in the case of applied machine learning, proper evaluation metric is the basic building block that should be in the spotlight and put under thorough examination. Here, we address tasks with class imbalance, in which the class of interest is the one with much lower number of samples. We encountered non-insignificant amount of recent papers, in which improper evaluation methods are used, borrowed mainly from the field of balanced problems. Such bad practices may heavily bias the results in favour of inappropriate algorithms and give false expectations of the state of the field.