 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBad practices in evaluation methodology relevant to class-imbalanced problems
Paper and Code
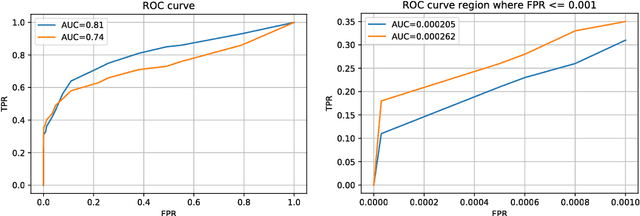
For research to go in the right direction, it is essential to be able to compare and quantify performance of different algorithms focused on the same problem. Choosing a suitable evaluation metric requires deep understanding of the pursued task along with all of its characteristics. We argue that in the case of applied machine learning, proper evaluation metric is the basic building block that should be in the spotlight and put under thorough examination. Here, we address tasks with class imbalance, in which the class of interest is the one with much lower number of samples. We encountered non-insignificant amount of recent papers, in which improper evaluation methods are used, borrowed mainly from the field of balanced problems. Such bad practices may heavily bias the results in favour of inappropriate algorithms and give false expectations of the state of the field.