 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular and Adaptive System for Business Email Compromise Detection
Aug 21, 2023



The growing sophistication of Business Email Compromise (BEC) and spear phishing attacks poses significant challenges to organizations worldwide. The techniques featured in traditional spam and phishing detection are insufficient due to the tailored nature of modern BEC attacks as they often blend in with the regular benign traffic. Recent advances in machine learning, particularly in Natural Language Understanding (NLU), offer a promising avenue for combating such attacks but in a practical system, due to limitations such as data availability, operational costs, verdict explainability requirements or a need to robustly evolve the system, it is essential to combine multiple approaches together. We present CAPE, a comprehensive and efficient system for BEC detection that has been proven in a production environment for a period of over two years. Rather than being a single model, CAPE is a system that combines independent ML models and algorithms detecting BEC-related behaviors across various email modalities such as text, images, metadata and the email's communication context. This decomposition makes CAPE's verdicts naturally explainable. In the paper, we describe the design principles and constraints behind its architecture, as well as the challenges of model design, evaluation and adapting the system continuously through a Bayesian approach that combines limited data with domain knowledge. Furthermore, we elaborate on several specific behavioral detectors, such as those based on Transformer neural architectures.
FairFace Challenge at ECCV 2020: Analyzing Bias in Face Recognition
Sep 16, 2020
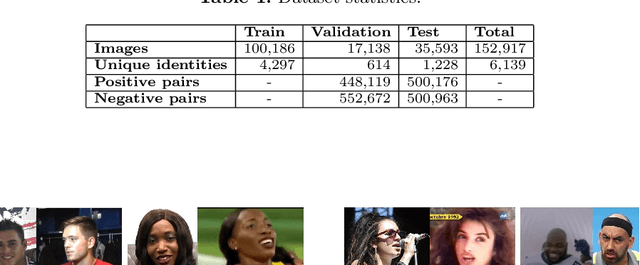
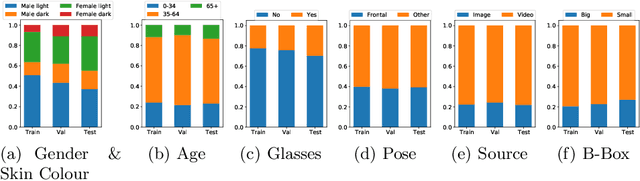
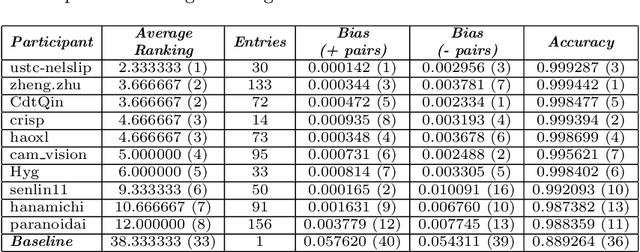
This work summarizes the 2020 ChaLearn Looking at People Fair Face Recognition and Analysis Challenge and provides a description of the top-winning solutions and analysis of the results. The aim of the challenge was to evaluate accuracy and bias in gender and skin colour of submitted algorithms on the task of 1:1 face verification in the presence of other confounding attributes. Participants were evaluated using an in-the-wild dataset based on reannotated IJB-C, further enriched by 12.5K new images and additional labels. The dataset is not balanced, which simulates a real world scenario where AI-based models supposed to present fair outcomes are trained and evaluated on imbalanced data. The challenge attracted 151 participants, who made more than 1.8K submissions in total. The final phase of the challenge attracted 36 active teams out of which 10 exceeded 0.999 AUC-ROC while achieving very low scores in the proposed bias metrics. Common strategies by the participants were face pre-processing, homogenization of data distributions, the use of bias aware loss functions and ensemble models. The analysis of top-10 teams shows higher false positive rates (and lower false negative rates) for females with dark skin tone as well as the potential of eyeglasses and young age to increase the false positive rates too.