 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTA-OOD: Test-time Augmentation for Improving Out-of-Distribution Detection in Gastrointestinal Vision
Jul 19, 2024



Deep learning has significantly advanced the field of gastrointestinal vision, enhancing disease diagnosis capabilities. One major challenge in automating diagnosis within gastrointestinal settings is the detection of abnormal cases in endoscopic images. Due to the sparsity of data, this process of distinguishing normal from abnormal cases has faced significant challenges, particularly with rare and unseen conditions. To address this issue, we frame abnormality detection as an out-of-distribution (OOD) detection problem. In this setup, a model trained on In-Distribution (ID) data, which represents a healthy GI tract, can accurately identify healthy cases, while abnormalities are detected as OOD, regardless of their class. We introduce a test-time augmentation segment into the OOD detection pipeline, which enhances the distinction between ID and OOD examples, thereby improving the effectiveness of existing OOD methods with the same model. This augmentation shifts the pixel space, which translates into a more distinct semantic representation for OOD examples compared to ID examples. We evaluated our method against existing state-of-the-art OOD scores, showing improvements with test-time augmentation over the baseline approach.
TextAug: Test time Text Augmentation for Multimodal Person Re-identification
Dec 04, 2023



Multimodal Person Reidentification is gaining popularity in the research community due to its effectiveness compared to counter-part unimodal frameworks. However, the bottleneck for multimodal deep learning is the need for a large volume of multimodal training examples. Data augmentation techniques such as cropping, flipping, rotation, etc. are often employed in the image domain to improve the generalization of deep learning models. Augmenting in other modalities than images, such as text, is challenging and requires significant computational resources and external data sources. In this study, we investigate the effectiveness of two computer vision data augmentation techniques: cutout and cutmix, for text augmentation in multi-modal person re-identification. Our approach merges these two augmentation strategies into one strategy called CutMixOut which involves randomly removing words or sub-phrases from a sentence (Cutout) and blending parts of two or more sentences to create diverse examples (CutMix) with a certain probability assigned to each operation. This augmentation was implemented at inference time without any prior training. Our results demonstrate that the proposed technique is simple and effective in improving the performance on multiple multimodal person re-identification benchmarks.
Data Augmentation through Pseudolabels in Automatic Region Based Coronary Artery Segmentation for Disease Diagnosis
Oct 08, 2023Coronary Artery Diseases(CADs) though preventable are one of the leading causes of death and disability. Diagnosis of these diseases is often difficult and resource intensive. Segmentation of arteries in angiographic images has evolved as a tool for assistance, helping clinicians in making accurate diagnosis. However, due to the limited amount of data and the difficulty in curating a dataset, the task of segmentation has proven challenging. In this study, we introduce the idea of using pseudolabels as a data augmentation technique to improve the performance of the baseline Yolo model. This method increases the F1 score of the baseline by 9% in the validation dataset and by 3% in the test dataset.
ConvNeXtv2 Fusion with Mask R-CNN for Automatic Region Based Coronary Artery Stenosis Detection for Disease Diagnosis
Oct 07, 2023



Coronary Artery Diseases although preventable are one of the leading cause of mortality worldwide. Due to the onerous nature of diagnosis, tackling CADs has proved challenging. This study addresses the automation of resource-intensive and time-consuming process of manually detecting stenotic lesions in coronary arteries in X-ray coronary angiography images. To overcome this challenge, we employ a specialized Convnext-V2 backbone based Mask RCNN model pre-trained for instance segmentation tasks. Our empirical findings affirm that the proposed model exhibits commendable performance in identifying stenotic lesions. Notably, our approach achieves a substantial F1 score of 0.5353 in this demanding task, underscoring its effectiveness in streamlining this intensive process.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023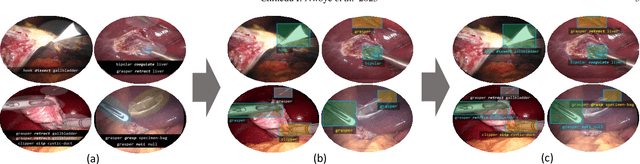
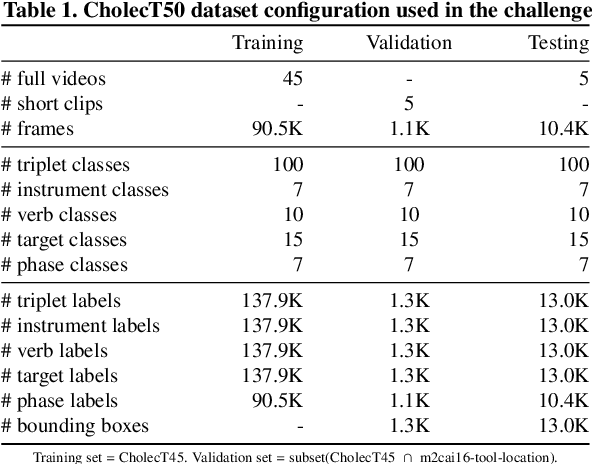
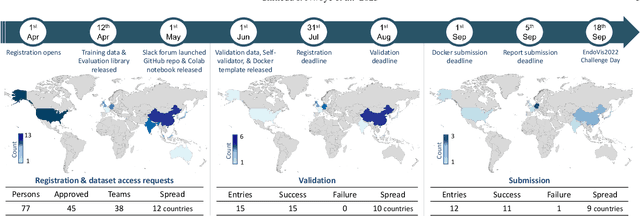
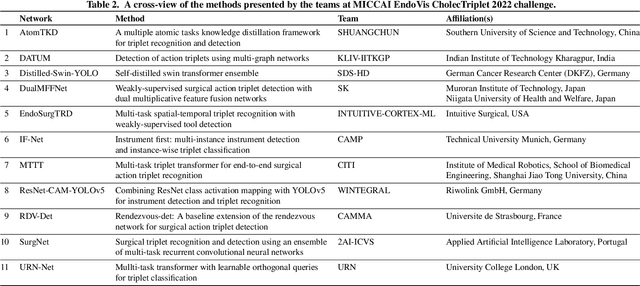
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022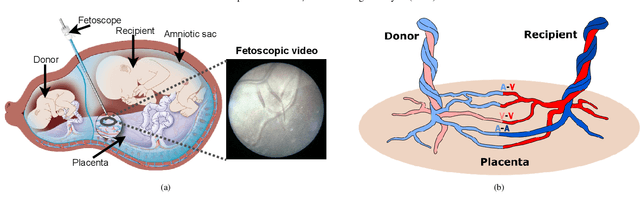
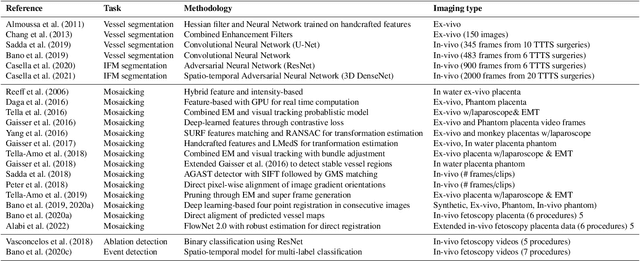
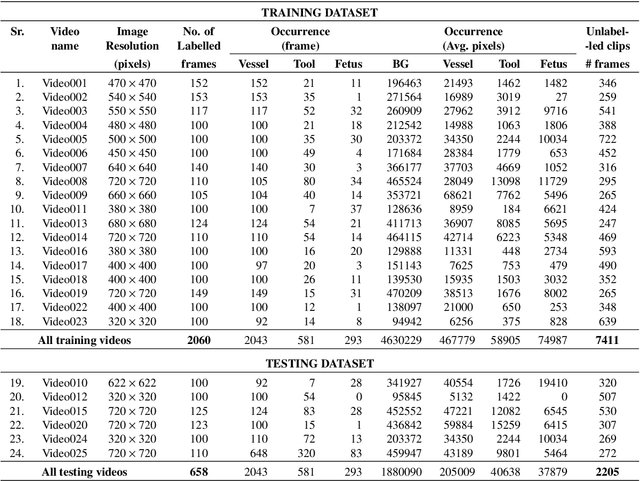
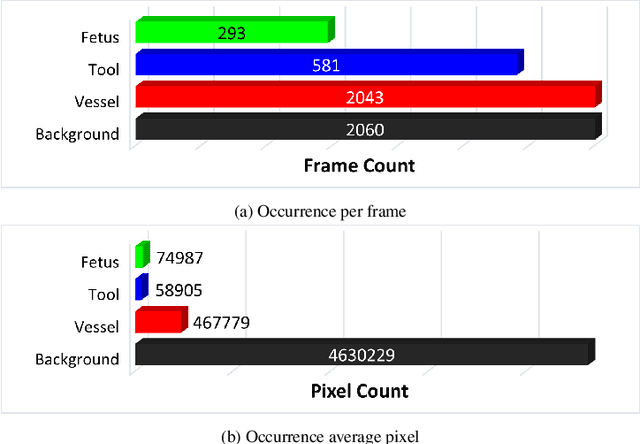
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
Histogram of Oriented Gradients Meet Deep Learning: A Novel Multi-task Deep Network for Medical Image Semantic Segmentation
Apr 02, 2022
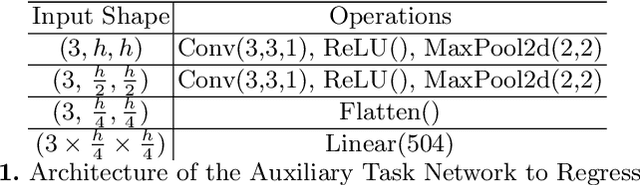
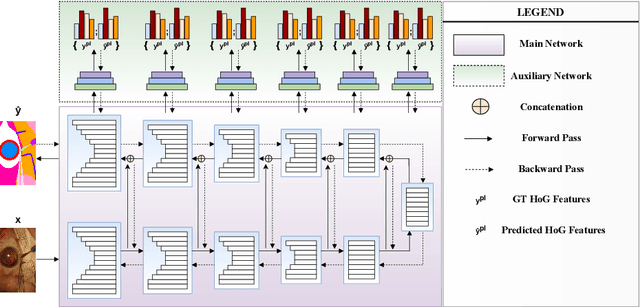
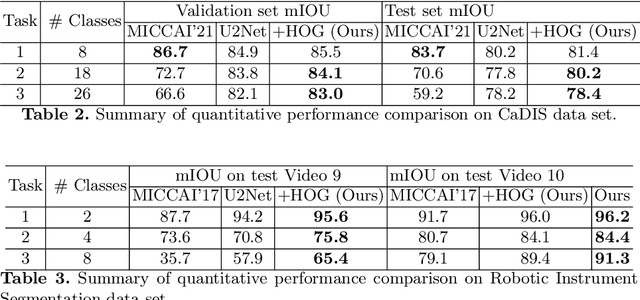
We present our novel deep multi-task learning method for medical image segmentation. Existing multi-task methods demand ground truth annotations for both the primary and auxiliary tasks. Contrary to it, we propose to generate the pseudo-labels of an auxiliary task in an unsupervised manner. To generate the pseudo-labels, we leverage Histogram of Oriented Gradients (HOGs), one of the most widely used and powerful hand-crafted features for detection. Together with the ground truth semantic segmentation masks for the primary task and pseudo-labels for the auxiliary task, we learn the parameters of the deep network to minimise the loss of both the primary task and the auxiliary task jointly. We employed our method on two powerful and widely used semantic segmentation networks: UNet and U2Net to train in a multi-task setup. To validate our hypothesis, we performed experiments on two different medical image segmentation data sets. From the extensive quantitative and qualitative results, we observe that our method consistently improves the performance compared to the counter-part method. Moreover, our method is the winner of FetReg Endovis Sub-challenge on Semantic Segmentation organised in conjunction with MICCAI 2021.
FairFace Challenge at ECCV 2020: Analyzing Bias in Face Recognition
Sep 16, 2020
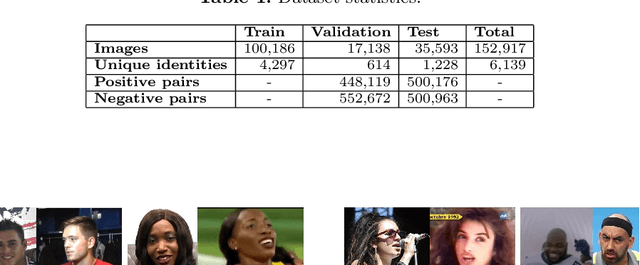
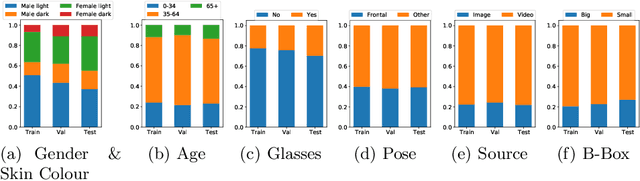
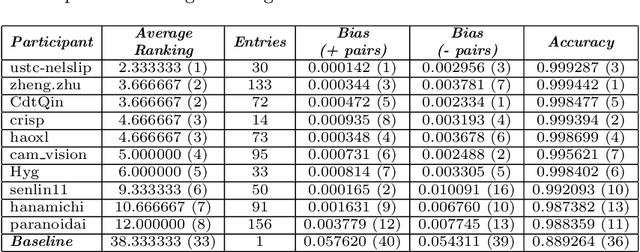
This work summarizes the 2020 ChaLearn Looking at People Fair Face Recognition and Analysis Challenge and provides a description of the top-winning solutions and analysis of the results. The aim of the challenge was to evaluate accuracy and bias in gender and skin colour of submitted algorithms on the task of 1:1 face verification in the presence of other confounding attributes. Participants were evaluated using an in-the-wild dataset based on reannotated IJB-C, further enriched by 12.5K new images and additional labels. The dataset is not balanced, which simulates a real world scenario where AI-based models supposed to present fair outcomes are trained and evaluated on imbalanced data. The challenge attracted 151 participants, who made more than 1.8K submissions in total. The final phase of the challenge attracted 36 active teams out of which 10 exceeded 0.999 AUC-ROC while achieving very low scores in the proposed bias metrics. Common strategies by the participants were face pre-processing, homogenization of data distributions, the use of bias aware loss functions and ensemble models. The analysis of top-10 teams shows higher false positive rates (and lower false negative rates) for females with dark skin tone as well as the potential of eyeglasses and young age to increase the false positive rates too.
Filtering Point Targets via Online Learning of Motion Models
Feb 20, 2019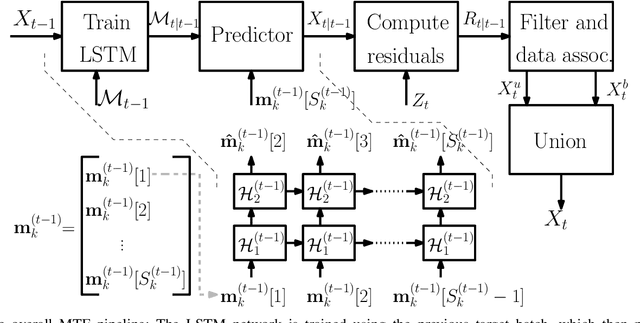
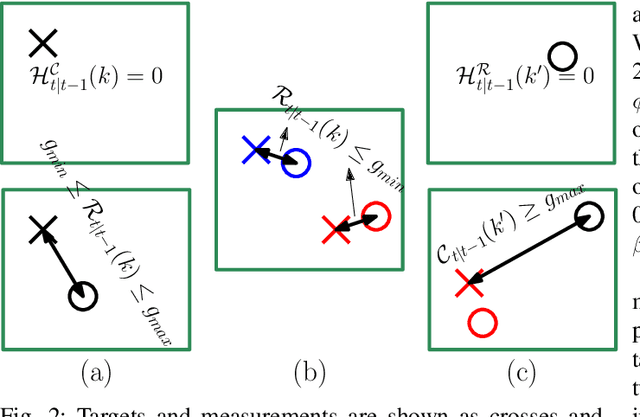
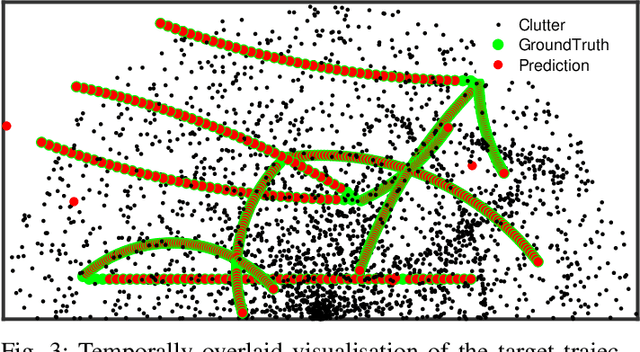
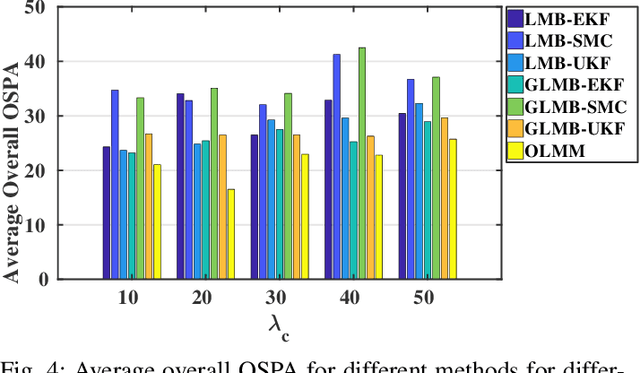
Filtering point targets in highly cluttered and noisy data frames can be very challenging, especially for complex target motions. Fixed motion models can fail to provide accurate predictions, while learning based algorithm can be difficult to design (due to the variable number of targets), slow to train and dependent on separate train/test steps. To address these issues, this paper proposes a multi-target filtering algorithm which learns the motion models, on the fly, using a recurrent neural network with a long short-term memory architecture, as a regression block. The target state predictions are then corrected using a novel data association algorithm, with a low computational complexity. The proposed algorithm is evaluated over synthetic and real point target filtering scenarios, demonstrating a remarkable performance over highly cluttered data sequences.
Real-time tracker with fast recovery from target loss
Feb 12, 2019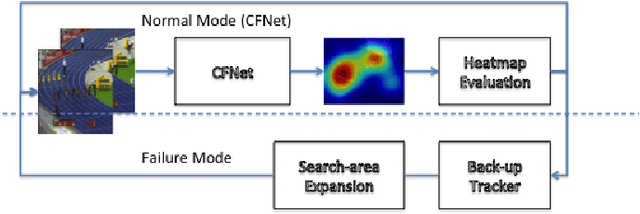
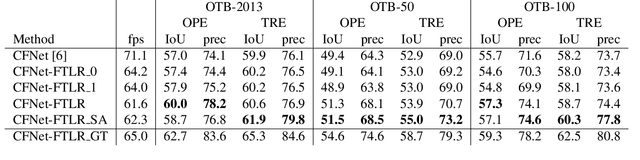
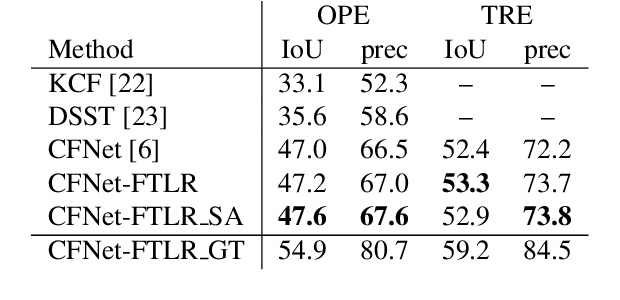
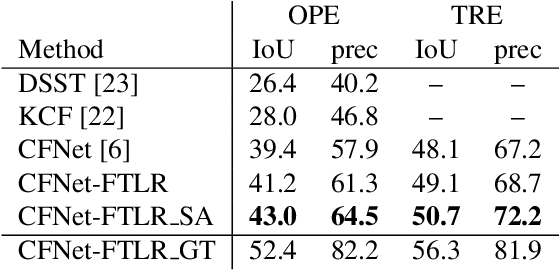
In this paper, we introduce a variation of a state-of-the-art real-time tracker (CFNet), which adds to the original algorithm robustness to target loss without a significant computational overhead. The new method is based on the assumption that the feature map can be used to estimate the tracking confidence more accurately. When the confidence is low, we avoid updating the object's position through the feature map; instead, the tracker passes to a single-frame failure mode, during which the patch's low-level visual content is used to swiftly update the object's position, before recovering from the target loss in the next frame. The experimental evidence provided by evaluating the method on several tracking datasets validates both the theoretical assumption that the feature map is associated to tracking confidence, and that the proposed implementation can achieve target recovery in multiple scenarios, without compromising the real-time performance.