 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed-MMFL: A Multimodal Federated Learning Benchmark in Healthcare
Feb 04, 2026Federated learning (FL) enables collaborative model training across decentralized medical institutions while preserving data privacy. However, medical FL benchmarks remain scarce, with existing efforts focusing mainly on unimodal or bimodal modalities and a limited range of medical tasks. This gap underscores the need for standardized evaluation to advance systematic understanding in medical MultiModal FL (MMFL). To this end, we introduce Med-MMFL, the first comprehensive MMFL benchmark for the medical domain, encompassing diverse modalities, tasks, and federation scenarios. Our benchmark evaluates six representative state-of-the-art FL algorithms, covering different aggregation strategies, loss formulations, and regularization techniques. It spans datasets with 2 to 4 modalities, comprising a total of 10 unique medical modalities, including text, pathology images, ECG, X-ray, radiology reports, and multiple MRI sequences. Experiments are conducted across naturally federated, synthetic IID, and synthetic non-IID settings to simulate real-world heterogeneity. We assess segmentation, classification, modality alignment (retrieval), and VQA tasks. To support reproducibility and fair comparison of future multimodal federated learning (MMFL) methods under realistic medical settings, we release the complete benchmark implementation, including data processing and partitioning pipelines, at https://github.com/bhattarailab/Med-MMFL-Benchmark .
Local K-Similarity Constraint for Federated Learning with Label Noise
Nov 09, 2025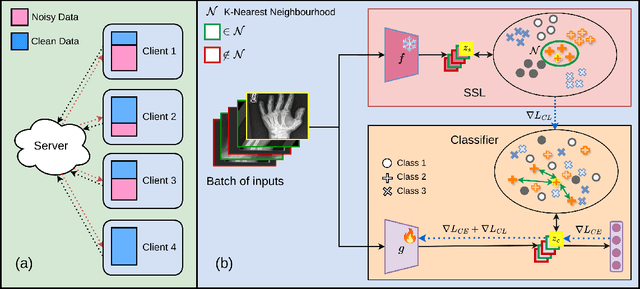

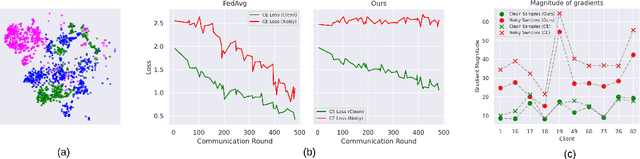
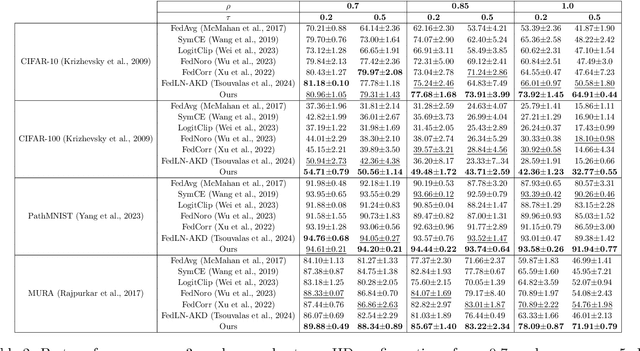
Federated learning on clients with noisy labels is a challenging problem, as such clients can infiltrate the global model, impacting the overall generalizability of the system. Existing methods proposed to handle noisy clients assume that a sufficient number of clients with clean labels are available, which can be leveraged to learn a robust global model while dampening the impact of noisy clients. This assumption fails when a high number of heterogeneous clients contain noisy labels, making the existing approaches ineffective. In such scenarios, it is important to locally regularize the clients before communication with the global model, to ensure the global model isn't corrupted by noisy clients. While pre-trained self-supervised models can be effective for local regularization, existing centralized approaches relying on pretrained initialization are impractical in a federated setting due to the potentially large size of these models, which increases communication costs. In that line, we propose a regularization objective for client models that decouples the pre-trained and classification models by enforcing similarity between close data points within the client. We leverage the representation space of a self-supervised pretrained model to evaluate the closeness among examples. This regularization, when applied with the standard objective function for the downstream task in standard noisy federated settings, significantly improves performance, outperforming existing state-of-the-art federated methods in multiple computer vision and medical image classification benchmarks. Unlike other techniques that rely on self-supervised pretrained initialization, our method does not require the pretrained model and classifier backbone to share the same architecture, making it architecture-agnostic.
Hallucination-Aware Multimodal Benchmark for Gastrointestinal Image Analysis with Large Vision-Language Models
May 11, 2025Vision-Language Models (VLMs) are becoming increasingly popular in the medical domain, bridging the gap between medical images and clinical language. Existing VLMs demonstrate an impressive ability to comprehend medical images and text queries to generate detailed, descriptive diagnostic medical reports. However, hallucination--the tendency to generate descriptions that are inconsistent with the visual content--remains a significant issue in VLMs, with particularly severe implications in the medical field. To facilitate VLM research on gastrointestinal (GI) image analysis and study hallucination, we curate a multimodal image-text GI dataset: Gut-VLM. This dataset is created using a two-stage pipeline: first, descriptive medical reports of Kvasir-v2 images are generated using ChatGPT, which introduces some hallucinated or incorrect texts. In the second stage, medical experts systematically review these reports, and identify and correct potential inaccuracies to ensure high-quality, clinically reliable annotations. Unlike traditional datasets that contain only descriptive texts, our dataset also features tags identifying hallucinated sentences and their corresponding corrections. A common approach to reducing hallucination in VLM is to finetune the model on a small-scale, problem-specific dataset. However, we take a different strategy using our dataset. Instead of finetuning the VLM solely for generating textual reports, we finetune it to detect and correct hallucinations, an approach we call hallucination-aware finetuning. Our results show that this approach is better than simply finetuning for descriptive report generation. Additionally, we conduct an extensive evaluation of state-of-the-art VLMs across several metrics, establishing a benchmark. GitHub Repo: https://github.com/bhattarailab/Hallucination-Aware-VLM.
Surgical Vision World Model
Mar 03, 2025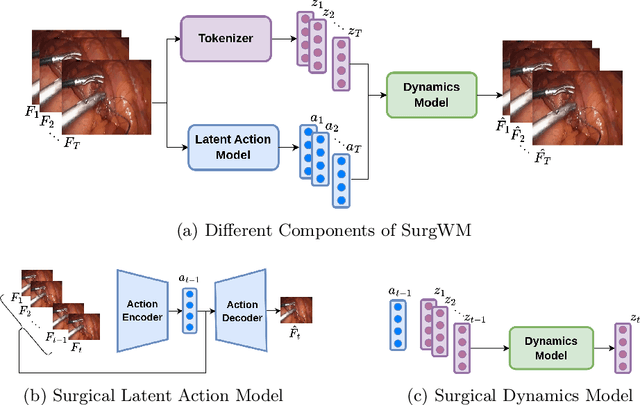
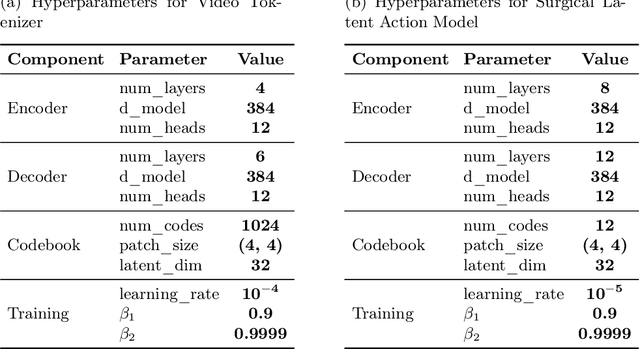
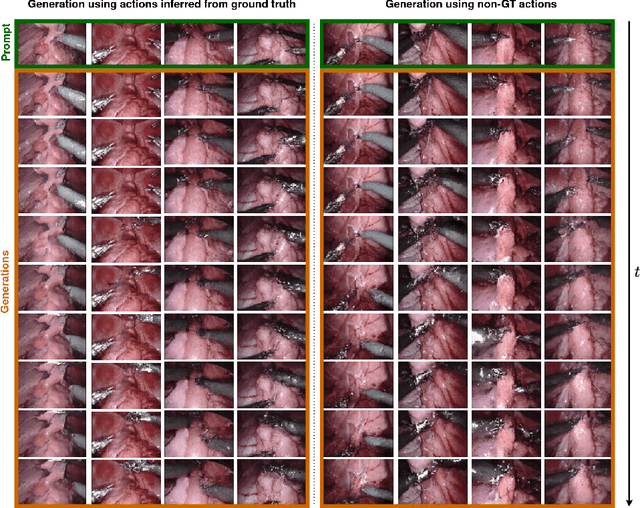
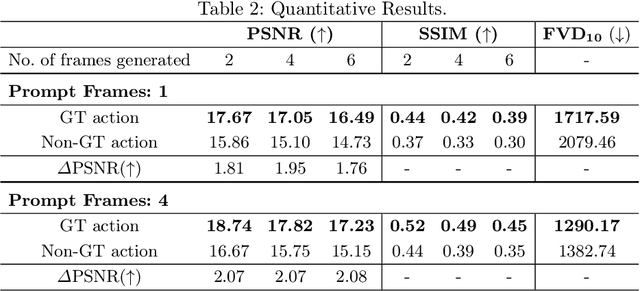
Realistic and interactive surgical simulation has the potential to facilitate crucial applications, such as medical professional training and autonomous surgical agent training. In the natural visual domain, world models have enabled action-controlled data generation, demonstrating the potential to train autonomous agents in interactive simulated environments when large-scale real data acquisition is infeasible. However, such works in the surgical domain have been limited to simplified computer simulations, and lack realism. Furthermore, existing literature in world models has predominantly dealt with action-labeled data, limiting their applicability to real-world surgical data, where obtaining action annotation is prohibitively expensive. Inspired by the recent success of Genie in leveraging unlabeled video game data to infer latent actions and enable action-controlled data generation, we propose the first surgical vision world model. The proposed model can generate action-controllable surgical data and the architecture design is verified with extensive experiments on the unlabeled SurgToolLoc-2022 dataset. Codes and implementation details are available at https://github.com/bhattarailab/Surgical-Vision-World-Model
NCDD: Nearest Centroid Distance Deficit for Out-Of-Distribution Detection in Gastrointestinal Vision
Dec 02, 2024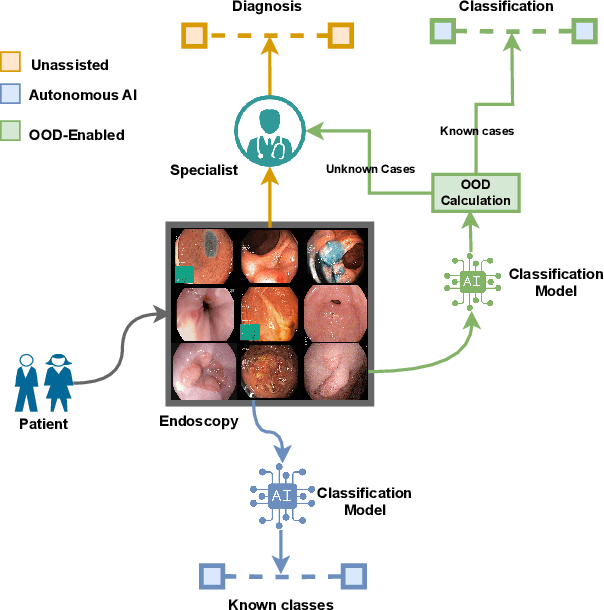

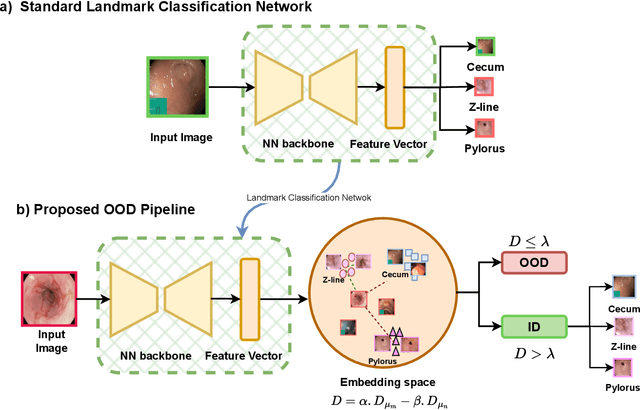
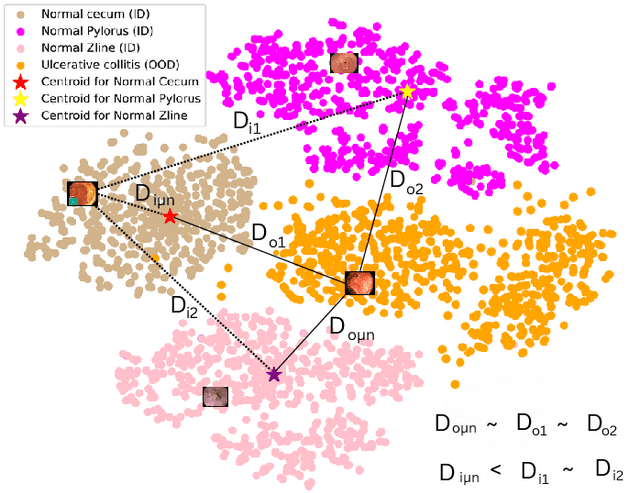
The integration of deep learning tools in gastrointestinal vision holds the potential for significant advancements in diagnosis, treatment, and overall patient care. A major challenge, however, is these tools' tendency to make overconfident predictions, even when encountering unseen or newly emerging disease patterns, undermining their reliability. We address this critical issue of reliability by framing it as an out-of-distribution (OOD) detection problem, where previously unseen and emerging diseases are identified as OOD examples. However, gastrointestinal images pose a unique challenge due to the overlapping feature representations between in- Distribution (ID) and OOD examples. Existing approaches often overlook this characteristic, as they are primarily developed for natural image datasets, where feature distinctions are more apparent. Despite the overlap, we hypothesize that the features of an in-distribution example will cluster closer to the centroids of their ground truth class, resulting in a shorter distance to the nearest centroid. In contrast, OOD examples maintain an equal distance from all class centroids. Based on this observation, we propose a novel nearest-centroid distance deficit (NCCD) score in the feature space for gastrointestinal OOD detection. Evaluations across multiple deep learning architectures and two publicly available benchmarks, Kvasir2 and Gastrovision, demonstrate the effectiveness of our approach compared to several state-of-the-art methods. The code and implementation details are publicly available at: https://github.com/bhattarailab/NCDD
Difficulty Estimation and Simplification of French Text Using LLMs
Jul 25, 2024We leverage generative large language models for language learning applications, focusing on estimating the difficulty of foreign language texts and simplifying them to lower difficulty levels. We frame both tasks as prediction problems and develop a difficulty classification model using labeled examples, transfer learning, and large language models, demonstrating superior accuracy compared to previous approaches. For simplification, we evaluate the trade-off between simplification quality and meaning preservation, comparing zero-shot and fine-tuned performances of large language models. We show that meaningful text simplifications can be obtained with limited fine-tuning. Our experiments are conducted on French texts, but our methods are language-agnostic and directly applicable to other foreign languages.
CAR-MFL: Cross-Modal Augmentation by Retrieval for Multimodal Federated Learning with Missing Modalities
Jul 11, 2024Multimodal AI has demonstrated superior performance over unimodal approaches by leveraging diverse data sources for more comprehensive analysis. However, applying this effectiveness in healthcare is challenging due to the limited availability of public datasets. Federated learning presents an exciting solution, allowing the use of extensive databases from hospitals and health centers without centralizing sensitive data, thus maintaining privacy and security. Yet, research in multimodal federated learning, particularly in scenarios with missing modalities a common issue in healthcare datasets remains scarce, highlighting a critical area for future exploration. Toward this, we propose a novel method for multimodal federated learning with missing modalities. Our contribution lies in a novel cross-modal data augmentation by retrieval, leveraging the small publicly available dataset to fill the missing modalities in the clients. Our method learns the parameters in a federated manner, ensuring privacy protection and improving performance in multiple challenging multimodal benchmarks in the medical domain, surpassing several competitive baselines. Code Available: https://github.com/bhattarailab/CAR-MFL
Data Augmentation through Pseudolabels in Automatic Region Based Coronary Artery Segmentation for Disease Diagnosis
Oct 08, 2023Coronary Artery Diseases(CADs) though preventable are one of the leading causes of death and disability. Diagnosis of these diseases is often difficult and resource intensive. Segmentation of arteries in angiographic images has evolved as a tool for assistance, helping clinicians in making accurate diagnosis. However, due to the limited amount of data and the difficulty in curating a dataset, the task of segmentation has proven challenging. In this study, we introduce the idea of using pseudolabels as a data augmentation technique to improve the performance of the baseline Yolo model. This method increases the F1 score of the baseline by 9% in the validation dataset and by 3% in the test dataset.
ConvNeXtv2 Fusion with Mask R-CNN for Automatic Region Based Coronary Artery Stenosis Detection for Disease Diagnosis
Oct 07, 2023



Coronary Artery Diseases although preventable are one of the leading cause of mortality worldwide. Due to the onerous nature of diagnosis, tackling CADs has proved challenging. This study addresses the automation of resource-intensive and time-consuming process of manually detecting stenotic lesions in coronary arteries in X-ray coronary angiography images. To overcome this challenge, we employ a specialized Convnext-V2 backbone based Mask RCNN model pre-trained for instance segmentation tasks. Our empirical findings affirm that the proposed model exhibits commendable performance in identifying stenotic lesions. Notably, our approach achieves a substantial F1 score of 0.5353 in this demanding task, underscoring its effectiveness in streamlining this intensive process.
Large Language Models for Difficulty Estimation of Foreign Language Content with Application to Language Learning
Sep 10, 2023We use large language models to aid learners enhance proficiency in a foreign language. This is accomplished by identifying content on topics that the user is interested in, and that closely align with the learner's proficiency level in that foreign language. Our work centers on French content, but our approach is readily transferable to other languages. Our solution offers several distinctive characteristics that differentiate it from existing language-learning solutions, such as, a) the discovery of content across topics that the learner cares about, thus increasing motivation, b) a more precise estimation of the linguistic difficulty of the content than traditional readability measures, and c) the availability of both textual and video-based content. The linguistic complexity of video content is derived from the video captions. It is our aspiration that such technology will enable learners to remain engaged in the language-learning process by continuously adapting the topics and the difficulty of the content to align with the learners' evolving interests and learning objectives.