 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficulty Estimation and Simplification of French Text Using LLMs
Jul 25, 2024We leverage generative large language models for language learning applications, focusing on estimating the difficulty of foreign language texts and simplifying them to lower difficulty levels. We frame both tasks as prediction problems and develop a difficulty classification model using labeled examples, transfer learning, and large language models, demonstrating superior accuracy compared to previous approaches. For simplification, we evaluate the trade-off between simplification quality and meaning preservation, comparing zero-shot and fine-tuned performances of large language models. We show that meaningful text simplifications can be obtained with limited fine-tuning. Our experiments are conducted on French texts, but our methods are language-agnostic and directly applicable to other foreign languages.
Large Language Models for Difficulty Estimation of Foreign Language Content with Application to Language Learning
Sep 10, 2023We use large language models to aid learners enhance proficiency in a foreign language. This is accomplished by identifying content on topics that the user is interested in, and that closely align with the learner's proficiency level in that foreign language. Our work centers on French content, but our approach is readily transferable to other languages. Our solution offers several distinctive characteristics that differentiate it from existing language-learning solutions, such as, a) the discovery of content across topics that the learner cares about, thus increasing motivation, b) a more precise estimation of the linguistic difficulty of the content than traditional readability measures, and c) the availability of both textual and video-based content. The linguistic complexity of video content is derived from the video captions. It is our aspiration that such technology will enable learners to remain engaged in the language-learning process by continuously adapting the topics and the difficulty of the content to align with the learners' evolving interests and learning objectives.
A Survey of Deep Learning: From Activations to Transformers
Feb 01, 2023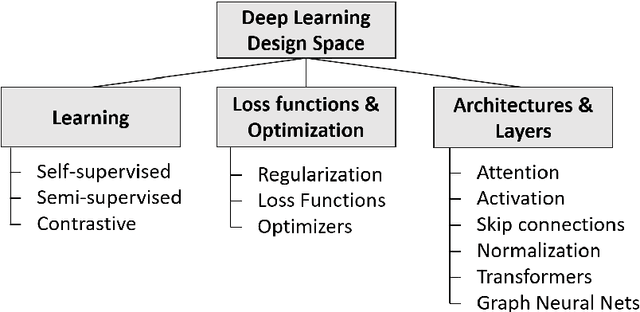

Deep learning has made tremendous progress in the last decade. A key success factor is the large amount of architectures, layers, objectives, and optimization techniques that have emerged in recent years. They include a myriad of variants related to attention, normalization, skip connection, transformer and self-supervised learning schemes -- to name a few. We provide a comprehensive overview of the most important, recent works in these areas to those who already have a basic understanding of deep learning. We hope that a holistic and unified treatment of influential, recent works helps researchers to form new connections between diverse areas of deep learning.
Reflective-Net: Learning from Explanations
Nov 27, 2020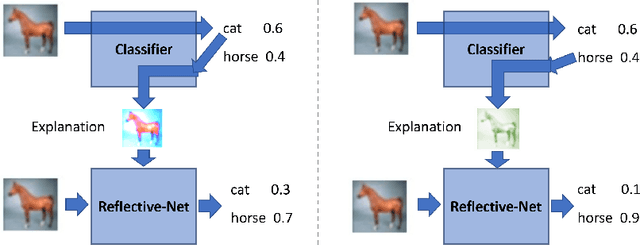
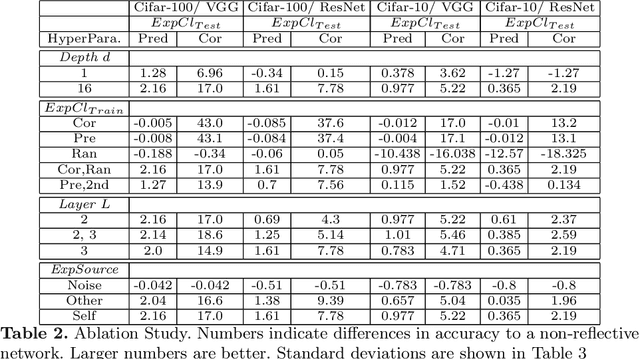
Humans possess a remarkable capability to make fast, intuitive decisions, but also to self-reflect, i.e., to explain to oneself, and to efficiently learn from explanations by others. This work provides the first steps toward mimicking this process by capitalizing on the explanations generated based on existing explanation methods, i.e. Grad-CAM. Learning from explanations combined with conventional labeled data yields significant improvements for classification in terms of accuracy and training time.
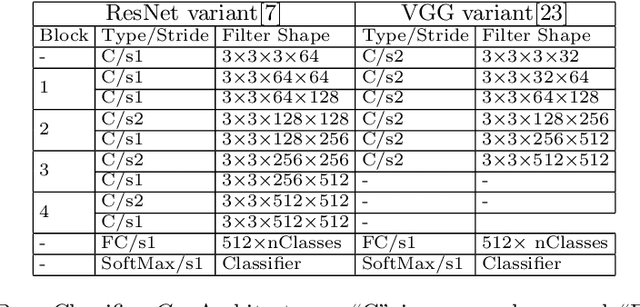
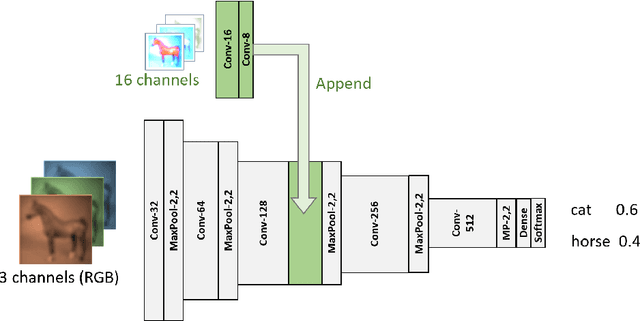
Explaining Neural Networks by Decoding Layer Activations
May 27, 2020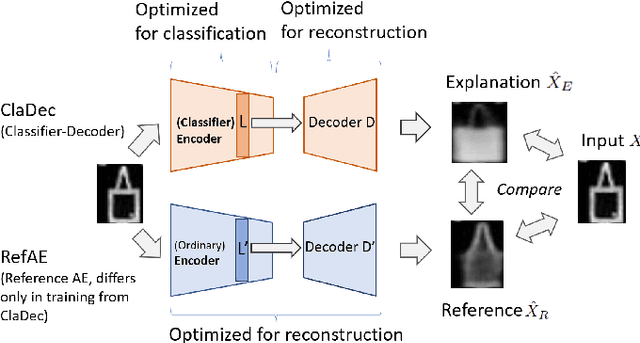
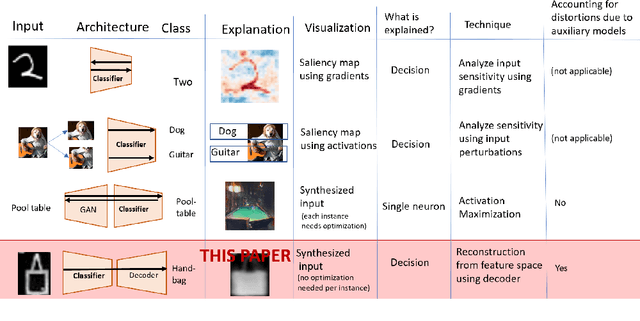
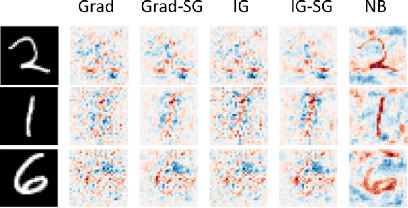
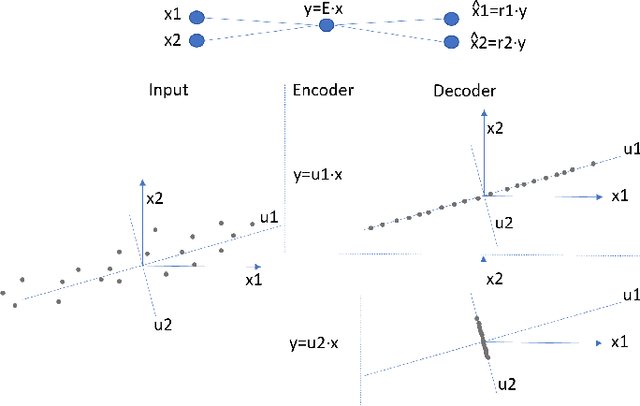
To derive explanations for deep learning models, ie. classifiers, we propose a `CLAssifier-DECoder' architecture (\emph{ClaDec}). \emph{ClaDec} allows to explain the output of an arbitrary layer. To this end, it uses a decoder that transforms the non-interpretable representation of the given layer to a representation that is more similar to training data. One can recognize what information a layer maintains by contrasting reconstructed images of \emph{ClaDec} with those of a conventional auto-encoder(AE) serving as reference. Our extended version also allows to trade human interpretability and fidelity to customize explanations to individual needs. We evaluate our approach for image classification using CNNs. In alignment with our theoretical motivation, the qualitative evaluation highlights that reconstructed images (of the network to be explained) tend to replace specific objects with more generic object templates and provide smoother reconstructions. We also show quantitatively that reconstructed visualizations using encodings from a classifier do capture more relevant information for classification than conventional AEs despite the fact that the latter contain more information on the original input.
Deceptive AI Explanations: Creation and Detection
Jan 21, 2020
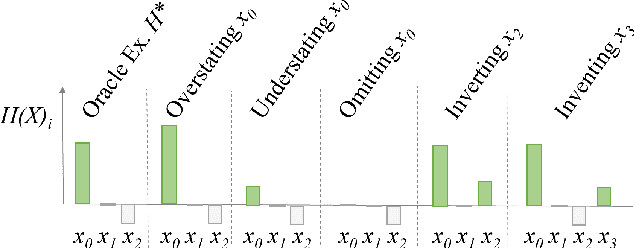


Artificial intelligence comes with great opportunities and but also great risks. We investigate to what extent deep learning can be used to create and detect deceptive explanations that either aim to lure a human into believing a decision that is not truthful to the model or provide reasoning that is non-faithful to the decision. Our theoretical insights show some limits of deception and detection in the absence of domain knowledge. For empirical evaluation, we focus on text classification. To create deceptive explanations, we alter explanations originating from GradCAM, a state-of-art technique for creating explanations in neural networks. We evaluate the effectiveness of deceptive explanations on 200 participants. Our findings indicate that deceptive explanations can indeed fool humans. Our classifier can detect even seemingly minor attempts of deception with accuracy that exceeds 80\% given sufficient domain knowledge encoded in the form of training data.