 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive AI Explanations: Creation and Detection
Paper and Code
Jan 21, 2020
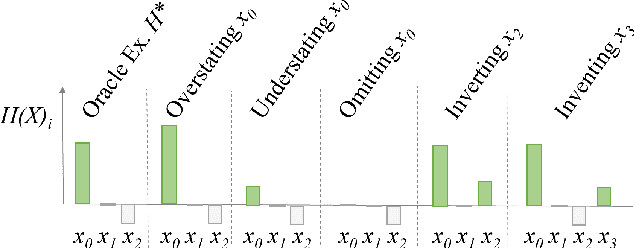


Artificial intelligence comes with great opportunities and but also great risks. We investigate to what extent deep learning can be used to create and detect deceptive explanations that either aim to lure a human into believing a decision that is not truthful to the model or provide reasoning that is non-faithful to the decision. Our theoretical insights show some limits of deception and detection in the absence of domain knowledge. For empirical evaluation, we focus on text classification. To create deceptive explanations, we alter explanations originating from GradCAM, a state-of-art technique for creating explanations in neural networks. We evaluate the effectiveness of deceptive explanations on 200 participants. Our findings indicate that deceptive explanations can indeed fool humans. Our classifier can detect even seemingly minor attempts of deception with accuracy that exceeds 80\% given sufficient domain knowledge encoded in the form of training data.