 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Path Alignment for Long-Range Motion Generation and Domain Transitions
Mar 31, 2026Long-range human movement generation remains a central challenge in computer vision and graphics. Generating coherent transitions across semantically distinct motion domains remains largely unexplored. This capability is particularly important for applications such as dance choreography, where movements must fluidly transition across diverse stylistic and semantic motifs. We propose a simple and effective inference-time optimization framework inspired by diffusion-based stochastic optimal control. Specifically, a control-energy objective that explicitly regularizes the transition trajectories of a pretrained diffusion model. We show that optimizing this objective at inference time yields transitions with fidelity and temporal coherence. This is the first work to provide a general framework for controlled long-range human motion generation with explicit transition modeling.
Federated Concept-Based Models: Interpretable models with distributed supervision
Feb 04, 2026Concept-based models (CMs) enhance interpretability in deep learning by grounding predictions in human-understandable concepts. However, concept annotations are expensive to obtain and rarely available at scale within a single data source. Federated learning (FL) could alleviate this limitation by enabling cross-institutional training that leverages concept annotations distributed across multiple data owners. Yet, FL lacks interpretable modeling paradigms. Integrating CMs with FL is non-trivial: CMs assume a fixed concept space and a predefined model architecture, whereas real-world FL is heterogeneous and non-stationary, with institutions joining over time and bringing new supervision. In this work, we propose Federated Concept-based Models (F-CMs), a new methodology for deploying CMs in evolving FL settings. F-CMs aggregate concept-level information across institutions and efficiently adapt the model architecture in response to changes in the available concept supervision, while preserving institutional privacy. Empirically, F-CMs preserve the accuracy and intervention effectiveness of training settings with full concept supervision, while outperforming non-adaptive federated baselines. Notably, F-CMs enable interpretable inference on concepts not available to a given institution, a key novelty with respect to existing approaches.
Mixture of Concept Bottleneck Experts
Feb 02, 2026Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs typically fix their task predictor to a single linear or Boolean expression, limiting both predictive accuracy and adaptability to diverse user needs. We propose Mixture of Concept Bottleneck Experts (M-CBEs), a framework that generalizes existing CBMs along two dimensions: the number of experts and the functional form of each expert, exposing an underexplored region of the design space. We investigate this region by instantiating two novel models: Linear M-CBE, which learns a finite set of linear expressions, and Symbolic M-CBE, which leverages symbolic regression to discover expert functions from data under user-specified operator vocabularies. Empirical evaluation demonstrates that varying the mixture size and functional form provides a robust framework for navigating the accuracy-interpretability trade-off, adapting to different user and task needs.
Enhanced Data-Driven Product Development via Gradient Based Optimization and Conformalized Monte Carlo Dropout Uncertainty Estimation
Jan 02, 2026Data-Driven Product Development (DDPD) leverages data to learn the relationship between product design specifications and resulting properties. To discover improved designs, we train a neural network on past experiments and apply Projected Gradient Descent to identify optimal input features that maximize performance. Since many products require simultaneous optimization of multiple correlated properties, our framework employs joint neural networks to capture interdependencies among targets. Furthermore, we integrate uncertainty estimation via \emph{Conformalised Monte Carlo Dropout} (ConfMC), a novel method combining Nested Conformal Prediction with Monte Carlo dropout to provide model-agnostic, finite-sample coverage guarantees under data exchangeability. Extensive experiments on five real-world datasets show that our method matches state-of-the-art performance while offering adaptive, non-uniform prediction intervals and eliminating the need for retraining when adjusting coverage levels.
Focus on the Likely: Test-time Instance-based Uncertainty Removal
May 02, 2025



We propose two novel test-time fine-tuning methods to improve uncertain model predictions. Our methods require no auxiliary data and use the given test instance only. Instead of performing a greedy selection of the most likely class to make a prediction, we introduce an additional focus on the likely classes step during inference. By applying a single-step gradient descent, we refine predictions when an initial forward pass indicates high uncertainty. This aligns predictions more closely with the ideal of assigning zero probability to less plausible outcomes. Our theoretical discussion provides a deeper understanding highlighting the impact on shared and non-shared features among (focus) classes. The experimental evaluation highlights accuracy gains on samples exhibiting high decision uncertainty for a diverse set of models from both the text and image domain using the same hyperparameters.
Enhancing ML Model Interpretability: Leveraging Fine-Tuned Large Language Models for Better Understanding of AI
May 02, 2025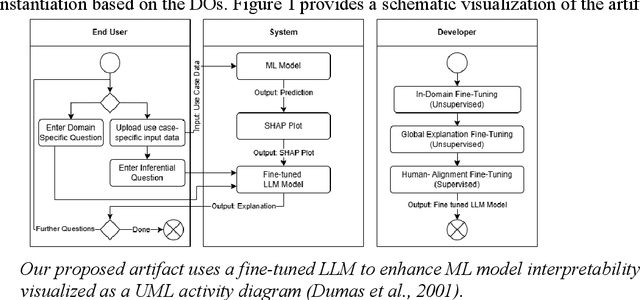
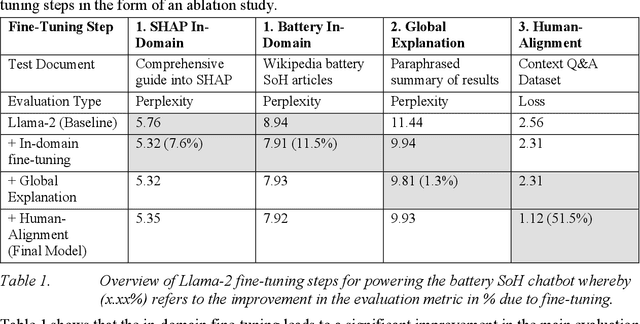
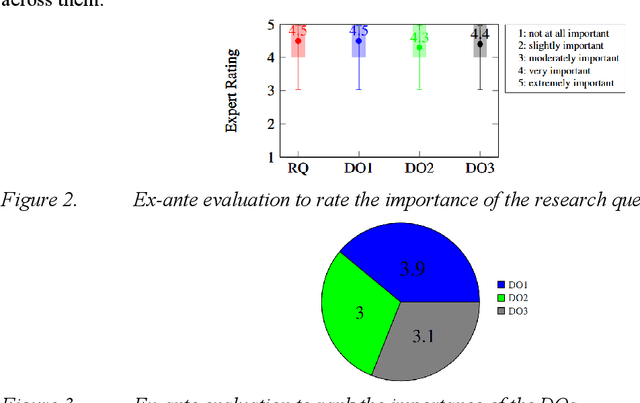
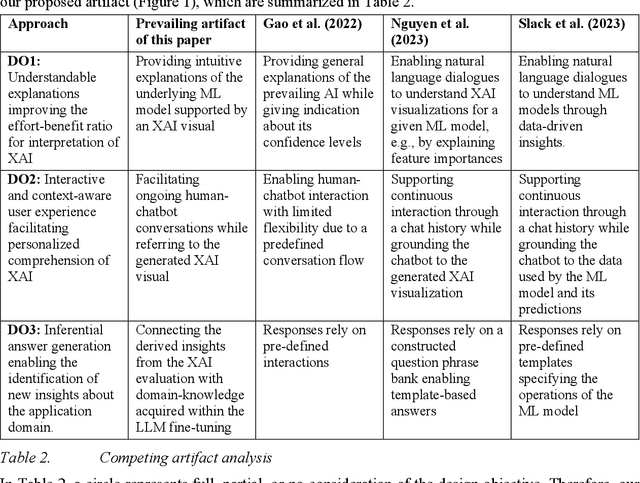
Across various sectors applications of eXplainableAI (XAI) gained momentum as the increasing black-boxedness of prevailing Machine Learning (ML) models became apparent. In parallel, Large Language Models (LLMs) significantly developed in their abilities to understand human language and complex patterns. By combining both, this paper presents a novel reference architecture for the interpretation of XAI through an interactive chatbot powered by a fine-tuned LLM. We instantiate the reference architecture in the context of State-of-Health (SoH) prediction for batteries and validate its design in multiple evaluation and demonstration rounds. The evaluation indicates that the implemented prototype enhances the human interpretability of ML, especially for users with less experience with XAI.
Generative to Agentic AI: Survey, Conceptualization, and Challenges
Apr 26, 2025
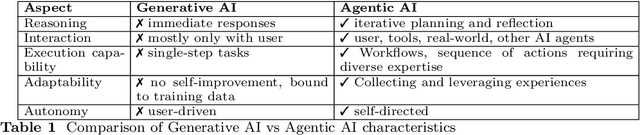
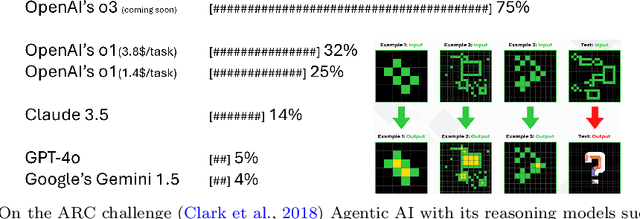
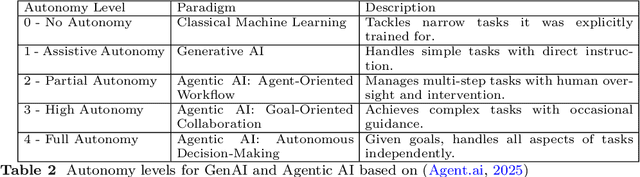
Agentic Artificial Intelligence (AI) builds upon Generative AI (GenAI). It constitutes the next major step in the evolution of AI with much stronger reasoning and interaction capabilities that enable more autonomous behavior to tackle complex tasks. Since the initial release of ChatGPT (3.5), Generative AI has seen widespread adoption, giving users firsthand experience. However, the distinction between Agentic AI and GenAI remains less well understood. To address this gap, our survey is structured in two parts. In the first part, we compare GenAI and Agentic AI using existing literature, discussing their key characteristics, how Agentic AI remedies limitations of GenAI, and the major steps in GenAI's evolution toward Agentic AI. This section is intended for a broad audience, including academics in both social sciences and engineering, as well as industry professionals. It provides the necessary insights to comprehend novel applications that are possible with Agentic AI but not with GenAI. In the second part, we deep dive into novel aspects of Agentic AI, including recent developments and practical concerns such as defining agents. Finally, we discuss several challenges that could serve as a future research agenda, while cautioning against risks that can emerge when exceeding human intelligence.
Using Phonemes in cascaded S2S translation pipeline
Apr 22, 2025This paper explores the idea of using phonemes as a textual representation within a conventional multilingual simultaneous speech-to-speech translation pipeline, as opposed to the traditional reliance on text-based language representations. To investigate this, we trained an open-source sequence-to-sequence model on the WMT17 dataset in two formats: one using standard textual representation and the other employing phonemic representation. The performance of both approaches was assessed using the BLEU metric. Our findings shows that the phonemic approach provides comparable quality but offers several advantages, including lower resource requirements or better suitability for low-resource languages.
Causally Reliable Concept Bottleneck Models
Mar 06, 2025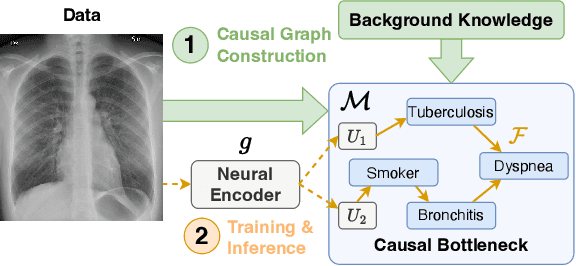



Concept-based models are an emerging paradigm in deep learning that constrains the inference process to operate through human-interpretable concepts, facilitating explainability and human interaction. However, these architectures, on par with popular opaque neural models, fail to account for the true causal mechanisms underlying the target phenomena represented in the data. This hampers their ability to support causal reasoning tasks, limits out-of-distribution generalization, and hinders the implementation of fairness constraints. To overcome these issues, we propose \emph{Causally reliable Concept Bottleneck Models} (C$^2$BMs), a class of concept-based architectures that enforce reasoning through a bottleneck of concepts structured according to a model of the real-world causal mechanisms. We also introduce a pipeline to automatically learn this structure from observational data and \emph{unstructured} background knowledge (e.g., scientific literature). Experimental evidence suggest that C$^2$BM are more interpretable, causally reliable, and improve responsiveness to interventions w.r.t. standard opaque and concept-based models, while maintaining their accuracy.
Improving Next Tokens via Second-Last Predictions with Generate and Refine
Nov 23, 2024



Autoregressive language models like GPT aim at predicting next tokens, while autoencoding models such as BERT are trained on tasks such as predicting masked tokens. We train a decoder only architecture for predicting the second last token for a sequence of tokens. Our approach yields higher computational training efficiency than BERT-style models by employing a structured deterministic approach towards masking tokens. We use our model to improve the next token predictions of a standard GPT by combining both predictions in a ``generate-then-refine'' approach. We show on different variants of GPT-2 and different datasets that (not unexpectedly) second last token predictions are much more accurate, i.e., more than 15\% higher accuracy than ordinary next token predictors. The ``generate-then-refine'' approach also demonstrates notable improvements in next-token predictions, yielding smaller yet consistent and significant gains.