 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Concept-Based Models: Interpretable models with distributed supervision
Feb 04, 2026Concept-based models (CMs) enhance interpretability in deep learning by grounding predictions in human-understandable concepts. However, concept annotations are expensive to obtain and rarely available at scale within a single data source. Federated learning (FL) could alleviate this limitation by enabling cross-institutional training that leverages concept annotations distributed across multiple data owners. Yet, FL lacks interpretable modeling paradigms. Integrating CMs with FL is non-trivial: CMs assume a fixed concept space and a predefined model architecture, whereas real-world FL is heterogeneous and non-stationary, with institutions joining over time and bringing new supervision. In this work, we propose Federated Concept-based Models (F-CMs), a new methodology for deploying CMs in evolving FL settings. F-CMs aggregate concept-level information across institutions and efficiently adapt the model architecture in response to changes in the available concept supervision, while preserving institutional privacy. Empirically, F-CMs preserve the accuracy and intervention effectiveness of training settings with full concept supervision, while outperforming non-adaptive federated baselines. Notably, F-CMs enable interpretable inference on concepts not available to a given institution, a key novelty with respect to existing approaches.
Mixture of Concept Bottleneck Experts
Feb 02, 2026Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs typically fix their task predictor to a single linear or Boolean expression, limiting both predictive accuracy and adaptability to diverse user needs. We propose Mixture of Concept Bottleneck Experts (M-CBEs), a framework that generalizes existing CBMs along two dimensions: the number of experts and the functional form of each expert, exposing an underexplored region of the design space. We investigate this region by instantiating two novel models: Linear M-CBE, which learns a finite set of linear expressions, and Symbolic M-CBE, which leverages symbolic regression to discover expert functions from data under user-specified operator vocabularies. Empirical evaluation demonstrates that varying the mixture size and functional form provides a robust framework for navigating the accuracy-interpretability trade-off, adapting to different user and task needs.
Interpretability in Deep Time Series Models Demands Semantic Alignment
Feb 02, 2026Deep time series models continue to improve predictive performance, yet their deployment remains limited by their black-box nature. In response, existing interpretability approaches in the field keep focusing on explaining the internal model computations, without addressing whether they align or not with how a human would reason about the studied phenomenon. Instead, we state interpretability in deep time series models should pursue semantic alignment: predictions should be expressed in terms of variables that are meaningful to the end user, mediated by spatial and temporal mechanisms that admit user-dependent constraints. In this paper, we formalize this requirement and require that, once established, semantic alignment must be preserved under temporal evolution: a constraint with no analog in static settings. Provided with this definition, we outline a blueprint for semantically aligned deep time series models, identify properties that support trust, and discuss implications for model design.
Causally Reliable Concept Bottleneck Models
Mar 06, 2025Concept-based models are an emerging paradigm in deep learning that constrains the inference process to operate through human-interpretable concepts, facilitating explainability and human interaction. However, these architectures, on par with popular opaque neural models, fail to account for the true causal mechanisms underlying the target phenomena represented in the data. This hampers their ability to support causal reasoning tasks, limits out-of-distribution generalization, and hinders the implementation of fairness constraints. To overcome these issues, we propose \emph{Causally reliable Concept Bottleneck Models} (C$^2$BMs), a class of concept-based architectures that enforce reasoning through a bottleneck of concepts structured according to a model of the real-world causal mechanisms. We also introduce a pipeline to automatically learn this structure from observational data and \emph{unstructured} background knowledge (e.g., scientific literature). Experimental evidence suggest that C$^2$BM are more interpretable, causally reliable, and improve responsiveness to interventions w.r.t. standard opaque and concept-based models, while maintaining their accuracy.
On the Regularization of Learnable Embeddings for Time Series Processing
Oct 18, 2024In processing multiple time series, accounting for the individual features of each sequence can be challenging. To address this, modern deep learning methods for time series analysis combine a shared (global) model with local layers, specific to each time series, often implemented as learnable embeddings. Ideally, these local embeddings should encode meaningful representations of the unique dynamics of each sequence. However, when these are learned end-to-end as parameters of a forecasting model, they may end up acting as mere sequence identifiers. Shared processing blocks may then become reliant on such identifiers, limiting their transferability to new contexts. In this paper, we address this issue by investigating methods to regularize the learning of local learnable embeddings for time series processing. Specifically, we perform the first extensive empirical study on the subject and show how such regularizations consistently improve performance in widely adopted architectures. Furthermore, we show that methods preventing the co-adaptation of local and global parameters are particularly effective in this context. This hypothesis is validated by comparing several methods preventing the downstream models from relying on sequence identifiers, going as far as completely resetting the embeddings during training. The obtained results provide an important contribution to understanding the interplay between learnable local parameters and shared processing layers: a key challenge in modern time series processing models and a step toward developing effective foundation models for time series.
Graph-based Virtual Sensing from Sparse and Partial Multivariate Observations
Feb 19, 2024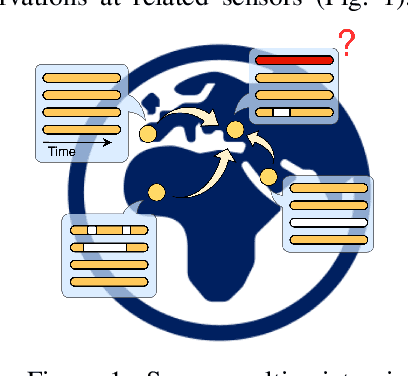
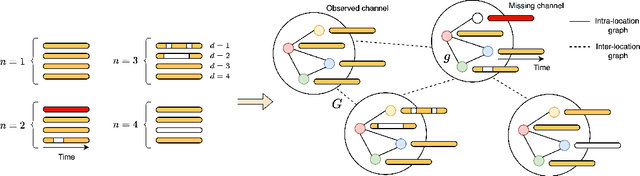
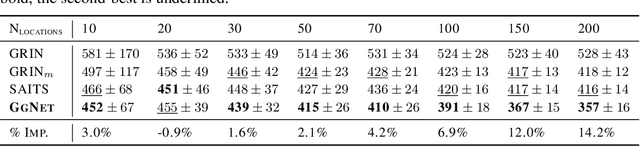
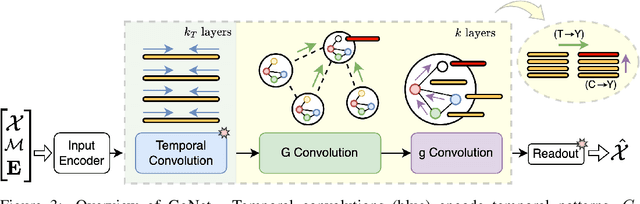
Virtual sensing techniques allow for inferring signals at new unmonitored locations by exploiting spatio-temporal measurements coming from physical sensors at different locations. However, as the sensor coverage becomes sparse due to costs or other constraints, physical proximity cannot be used to support interpolation. In this paper, we overcome this challenge by leveraging dependencies between the target variable and a set of correlated variables (covariates) that can frequently be associated with each location of interest. From this viewpoint, covariates provide partial observability, and the problem consists of inferring values for unobserved channels by exploiting observations at other locations to learn how such variables can correlate. We introduce a novel graph-based methodology to exploit such relationships and design a graph deep learning architecture, named GgNet, implementing the framework. The proposed approach relies on propagating information over a nested graph structure that is used to learn dependencies between variables as well as locations. GgNet is extensively evaluated under different virtual sensing scenarios, demonstrating higher reconstruction accuracy compared to the state-of-the-art.
Quantum Natural Language Processing on Near-Term Quantum Computers
May 08, 2020In this work, we describe a full-stack pipeline for natural language processing on near-term quantum computers, aka QNLP. The language modelling framework we employ is that of compositional distributional semantics (DisCoCat), which extends and complements the compositional structure of pregroup grammars. Within this model, the grammatical reduction of a sentence is interpreted as a diagram, encoding a specific interaction of words according to the grammar. It is this interaction which, together with a specific choice of word embedding, realises the meaning (or "semantics") of a sentence. Building on the formal quantum-like nature of such interactions, we present a method for mapping DisCoCat diagrams to quantum circuits. Our methodology is compatible both with NISQ devices and with established Quantum Machine Learning techniques, paving the way to near-term applications of quantum technology to natural language processing.