 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACS: Multi-Agent Reinforcement Learning for Optimization of Crystal Structures
Jun 04, 2025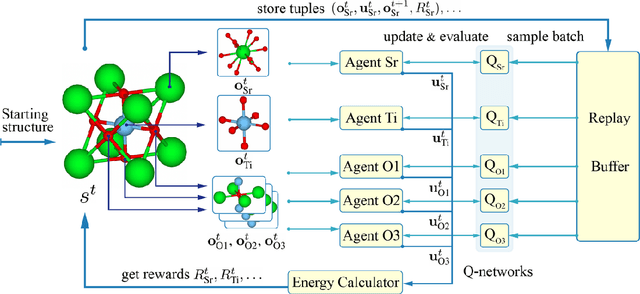



Geometry optimization of atomic structures is a common and crucial task in computational chemistry and materials design. Following the learning to optimize paradigm, we propose a new multi-agent reinforcement learning method called Multi-Agent Crystal Structure optimization (MACS) to address periodic crystal structure optimization. MACS treats geometry optimization as a partially observable Markov game in which atoms are agents that adjust their positions to collectively discover a stable configuration. We train MACS across various compositions of reported crystalline materials to obtain a policy that successfully optimizes structures from the training compositions as well as structures of larger sizes and unseen compositions, confirming its excellent scalability and zero-shot transferability. We benchmark our approach against a broad range of state-of-the-art optimization methods and demonstrate that MACS optimizes periodic crystal structures significantly faster, with fewer energy calculations, and the lowest failure rate.
Language-Based Bayesian Optimization Research Assistant (BORA)
Jan 27, 2025



Many important scientific problems involve multivariate optimization coupled with slow and laborious experimental measurements. These complex, high-dimensional searches can be defined by non-convex optimization landscapes that resemble needle-in-a-haystack surfaces, leading to entrapment in local minima. Contextualizing optimizers with human domain knowledge is a powerful approach to guide searches to localized fruitful regions. However, this approach is susceptible to human confirmation bias and it is also challenging for domain experts to keep track of the rapidly expanding scientific literature. Here, we propose the use of Large Language Models (LLMs) for contextualizing Bayesian optimization (BO) via a hybrid optimization framework that intelligently and economically blends stochastic inference with domain knowledge-based insights from the LLM, which is used to suggest new, better-performing areas of the search space for exploration. Our method fosters user engagement by offering real-time commentary on the optimization progress, explaining the reasoning behind the search strategies. We validate the effectiveness of our approach on synthetic benchmarks with up to 15 independent variables and demonstrate the ability of LLMs to reason in four real-world experimental tasks where context-aware suggestions boost optimization performance substantially.
Establishing Deep InfoMax as an effective self-supervised learning methodology in materials informatics
Jun 30, 2024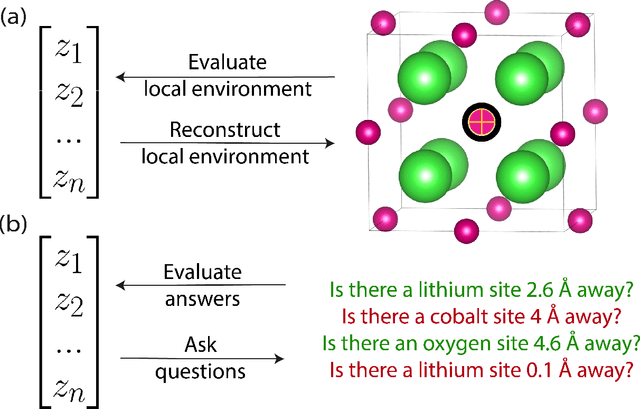

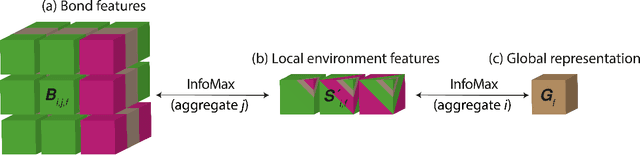

The scarcity of property labels remains a key challenge in materials informatics, whereas materials data without property labels are abundant in comparison. By pretraining supervised property prediction models on self-supervised tasks that depend only on the "intrinsic information" available in any Crystallographic Information File (CIF), there is potential to leverage the large amount of crystal data without property labels to improve property prediction results on small datasets. We apply Deep InfoMax as a self-supervised machine learning framework for materials informatics that explicitly maximises the mutual information between a point set (or graph) representation of a crystal and a vector representation suitable for downstream learning. This allows the pretraining of supervised models on large materials datasets without the need for property labels and without requiring the model to reconstruct the crystal from a representation vector. We investigate the benefits of Deep InfoMax pretraining implemented on the Site-Net architecture to improve the performance of downstream property prediction models with small amounts (<10^3) of data, a situation relevant to experimentally measured materials property databases. Using a property label masking methodology, where we perform self-supervised learning on larger supervised datasets and then train supervised models on a small subset of the labels, we isolate Deep InfoMax pretraining from the effects of distributional shift. We demonstrate performance improvements in the contexts of representation learning and transfer learning on the tasks of band gap and formation energy prediction. Having established the effectiveness of Deep InfoMax pretraining in a controlled environment, our findings provide a foundation for extending the approach to address practical challenges in materials informatics.
Graph-based Virtual Sensing from Sparse and Partial Multivariate Observations
Feb 19, 2024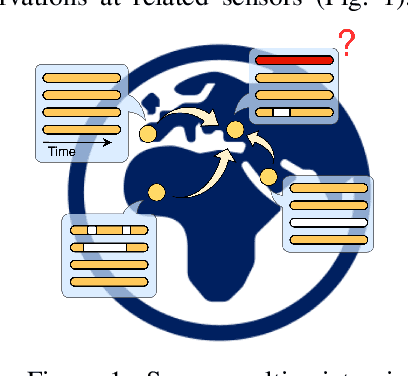
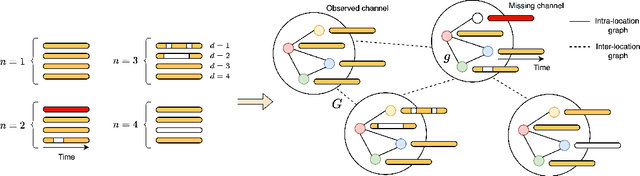
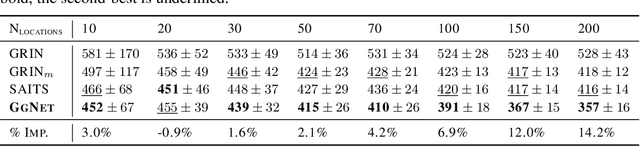
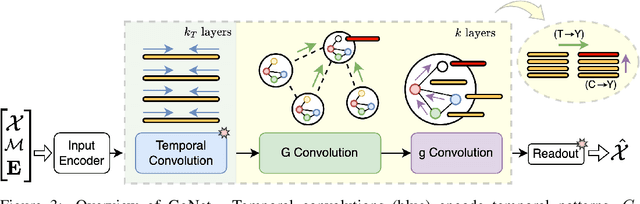
Virtual sensing techniques allow for inferring signals at new unmonitored locations by exploiting spatio-temporal measurements coming from physical sensors at different locations. However, as the sensor coverage becomes sparse due to costs or other constraints, physical proximity cannot be used to support interpolation. In this paper, we overcome this challenge by leveraging dependencies between the target variable and a set of correlated variables (covariates) that can frequently be associated with each location of interest. From this viewpoint, covariates provide partial observability, and the problem consists of inferring values for unobserved channels by exploiting observations at other locations to learn how such variables can correlate. We introduce a novel graph-based methodology to exploit such relationships and design a graph deep learning architecture, named GgNet, implementing the framework. The proposed approach relies on propagating information over a nested graph structure that is used to learn dependencies between variables as well as locations. GgNet is extensively evaluated under different virtual sensing scenarios, demonstrating higher reconstruction accuracy compared to the state-of-the-art.
HypBO: Expert-Guided Chemist-in-the-Loop Bayesian Search for New Materials
Aug 24, 2023



Robotics and automation offer massive accelerations for solving intractable, multivariate scientific problems such as materials discovery, but the available search spaces can be dauntingly large. Bayesian optimization (BO) has emerged as a popular sample-efficient optimization engine, thriving in tasks where no analytic form of the target function/property is known. Here we exploit expert human knowledge in the form of hypotheses to direct Bayesian searches more quickly to promising regions of chemical space. Previous methods have used underlying distributions derived from existing experimental measurements, which is unfeasible for new, unexplored scientific tasks. Also, such distributions cannot capture intricate hypotheses. Our proposed method, which we call HypBO, uses expert human hypotheses to generate an improved seed of samples. Unpromising seeds are automatically discounted, while promising seeds are used to augment the surrogate model data, thus achieving better-informed sampling. This process continues in a global versus local search fashion, organized in a bilevel optimization framework. We validate the performance of our method on a range of synthetic functions and demonstrate its practical utility on a real chemical design task where the use of expert hypotheses accelerates the search performance significantly.