 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Deep InfoMax as an effective self-supervised learning methodology in materials informatics
Jun 30, 2024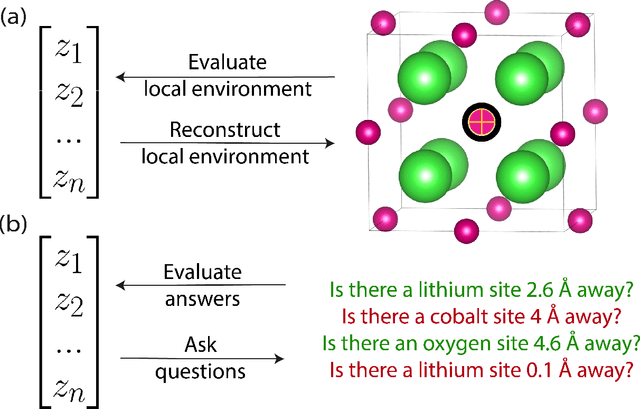

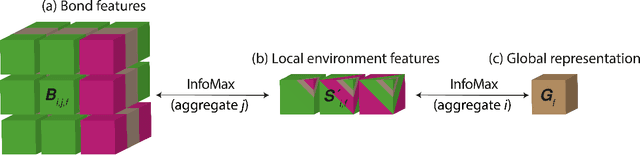

The scarcity of property labels remains a key challenge in materials informatics, whereas materials data without property labels are abundant in comparison. By pretraining supervised property prediction models on self-supervised tasks that depend only on the "intrinsic information" available in any Crystallographic Information File (CIF), there is potential to leverage the large amount of crystal data without property labels to improve property prediction results on small datasets. We apply Deep InfoMax as a self-supervised machine learning framework for materials informatics that explicitly maximises the mutual information between a point set (or graph) representation of a crystal and a vector representation suitable for downstream learning. This allows the pretraining of supervised models on large materials datasets without the need for property labels and without requiring the model to reconstruct the crystal from a representation vector. We investigate the benefits of Deep InfoMax pretraining implemented on the Site-Net architecture to improve the performance of downstream property prediction models with small amounts (<10^3) of data, a situation relevant to experimentally measured materials property databases. Using a property label masking methodology, where we perform self-supervised learning on larger supervised datasets and then train supervised models on a small subset of the labels, we isolate Deep InfoMax pretraining from the effects of distributional shift. We demonstrate performance improvements in the contexts of representation learning and transfer learning on the tasks of band gap and formation energy prediction. Having established the effectiveness of Deep InfoMax pretraining in a controlled environment, our findings provide a foundation for extending the approach to address practical challenges in materials informatics.