 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpelling Bee Embeddings for Language Modeling
Jan 25, 2026We introduce a simple modification to the embedding layer. The key change is to infuse token embeddings with information about their spelling. Models trained with these embeddings improve not only on spelling, but also across standard benchmarks. We conduct scaling studies for models with 40M to 800M parameters, which suggest that the improvements are equivalent to needing about 8% less compute and data to achieve the same test loss.
MACS: Multi-Agent Reinforcement Learning for Optimization of Crystal Structures
Jun 04, 2025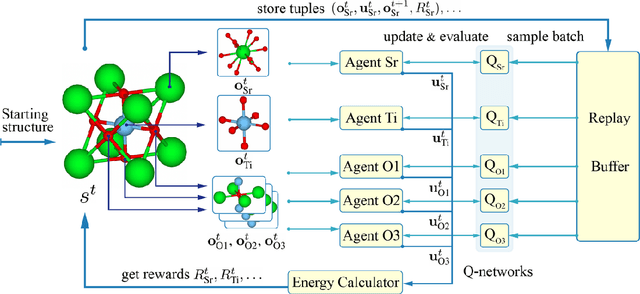



Geometry optimization of atomic structures is a common and crucial task in computational chemistry and materials design. Following the learning to optimize paradigm, we propose a new multi-agent reinforcement learning method called Multi-Agent Crystal Structure optimization (MACS) to address periodic crystal structure optimization. MACS treats geometry optimization as a partially observable Markov game in which atoms are agents that adjust their positions to collectively discover a stable configuration. We train MACS across various compositions of reported crystalline materials to obtain a policy that successfully optimizes structures from the training compositions as well as structures of larger sizes and unseen compositions, confirming its excellent scalability and zero-shot transferability. We benchmark our approach against a broad range of state-of-the-art optimization methods and demonstrate that MACS optimizes periodic crystal structures significantly faster, with fewer energy calculations, and the lowest failure rate.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Data Generation for Neural Programming by Example
Nov 06, 2019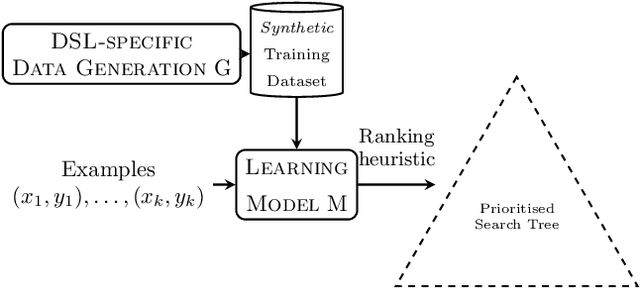



Programming by example is the problem of synthesizing a program from a small set of input / output pairs. Recent works applying machine learning methods to this task show promise, but are typically reliant on generating synthetic examples for training. A particular challenge lies in generating meaningful sets of inputs and outputs, which well-characterize a given program and accurately demonstrate its behavior. Where examples used for testing are generated by the same method as training data then the performance of a model may be partly reliant on this similarity. In this paper we introduce a novel approach using an SMT solver to synthesize inputs which cover a diverse set of behaviors for a given program. We carry out a case study comparing this method to existing synthetic data generation procedures in the literature, and find that data generated using our approach improves both the discriminatory power of example sets and the ability of trained machine learning models to generalize to unfamiliar data.