 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sparse Federated Analytics: Location Heatmaps under Distributed Differential Privacy with Secure Aggregation
Nov 03, 2021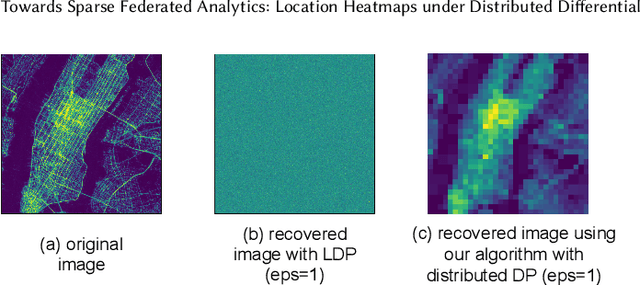
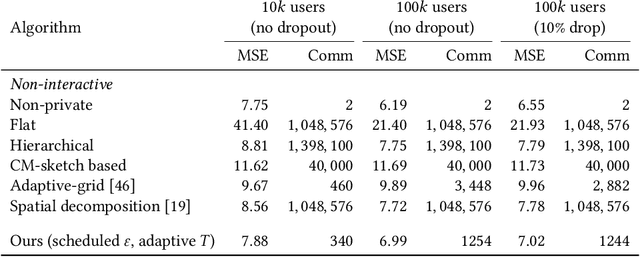
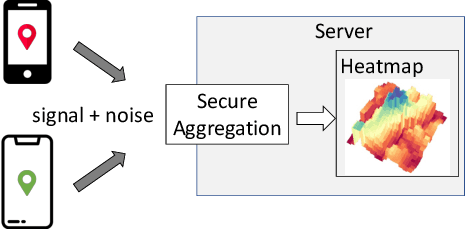

We design a scalable algorithm to privately generate location heatmaps over decentralized data from millions of user devices. It aims to ensure differential privacy before data becomes visible to a service provider while maintaining high data accuracy and minimizing resource consumption on users' devices. To achieve this, we revisit the distributed differential privacy concept based on recent results in the secure multiparty computation field and design a scalable and adaptive distributed differential privacy approach for location analytics. Evaluation on public location datasets shows that this approach successfully generates metropolitan-scale heatmaps from millions of user samples with a worst-case client communication overhead that is significantly smaller than existing state-of-the-art private protocols of similar accuracy.
MPC-Friendly Commitments for Publicly Verifiable Covert Security
Sep 15, 2021



We address the problem of efficiently verifying a commitment in a two-party computation. This addresses the scenario where a party P1 commits to a value $x$ to be used in a subsequent secure computation with another party P2 that wants to receive assurance that P1 did not cheat, i.e. that $x$ was indeed the value inputted into the secure computation. Our constructions operate in the publicly verifiable covert (PVC) security model, which is a relaxation of the malicious model of MPC appropriate in settings where P1 faces a reputational harm if caught cheating. We introduce the notion of PVC commitment scheme and indexed hash functions to build commitments schemes tailored to the PVC framework, and propose constructions for both arithmetic and Boolean circuits that result in very efficient circuits. From a practical standpoint, our constructions for Boolean circuits are $60\times$ faster to evaluate securely, and use $36\times$ less communication than baseline methods based on hashing. Moreover, we show that our constructions are tight in terms of required non-linear operations, by proving lower bounds on the nonlinear gate count of commitment verification circuits. Finally, we present a technique to amplify the security properties our constructions that allows to efficiently recover malicious guarantees with statistical security.
Advances and Open Problems in Federated Learning
Dec 10, 2019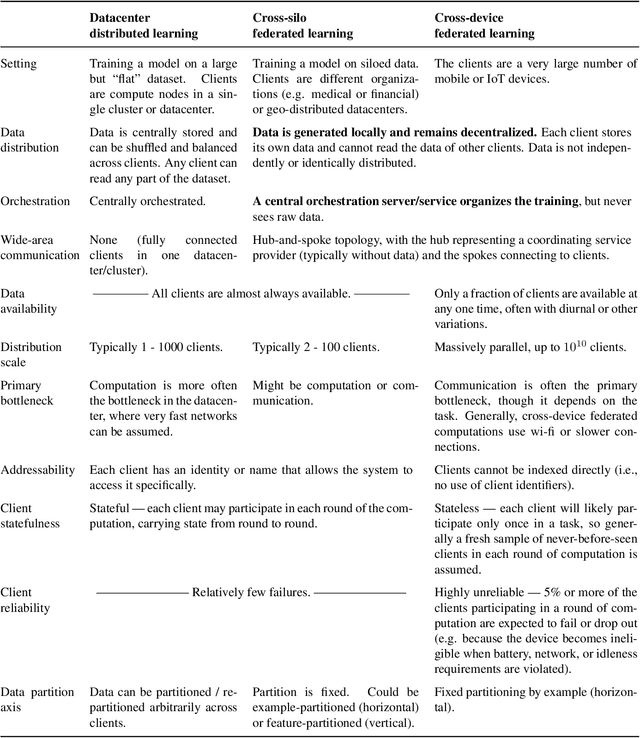
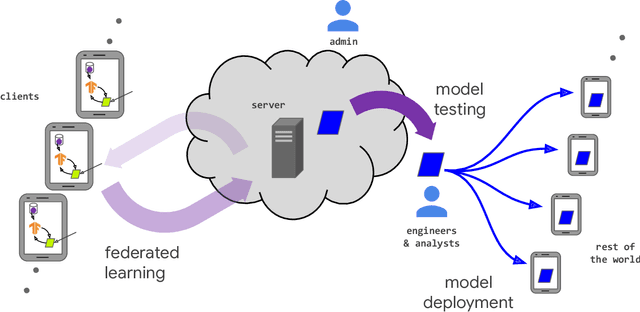
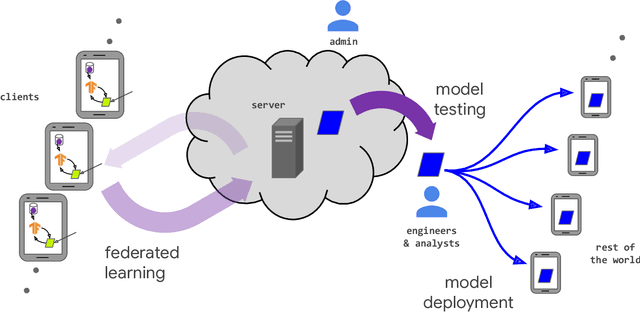

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Data Generation for Neural Programming by Example
Nov 06, 2019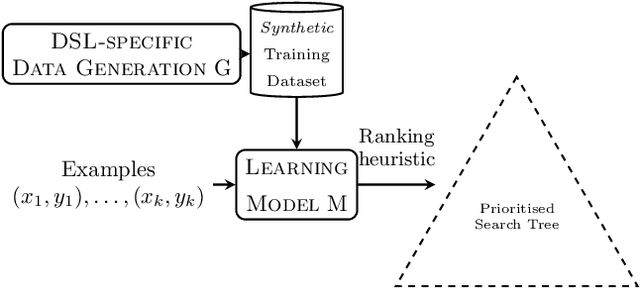



Programming by example is the problem of synthesizing a program from a small set of input / output pairs. Recent works applying machine learning methods to this task show promise, but are typically reliant on generating synthetic examples for training. A particular challenge lies in generating meaningful sets of inputs and outputs, which well-characterize a given program and accurately demonstrate its behavior. Where examples used for testing are generated by the same method as training data then the performance of a model may be partly reliant on this similarity. In this paper we introduce a novel approach using an SMT solver to synthesize inputs which cover a diverse set of behaviors for a given program. We carry out a case study comparing this method to existing synthetic data generation procedures in the literature, and find that data generated using our approach improves both the discriminatory power of example sets and the ability of trained machine learning models to generalize to unfamiliar data.
Private Protocols for U-Statistics in the Local Model and Beyond
Oct 09, 2019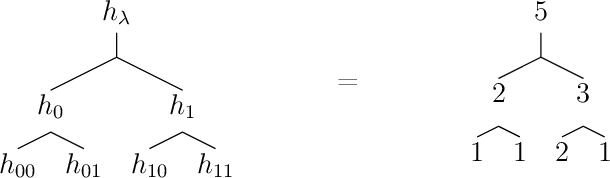

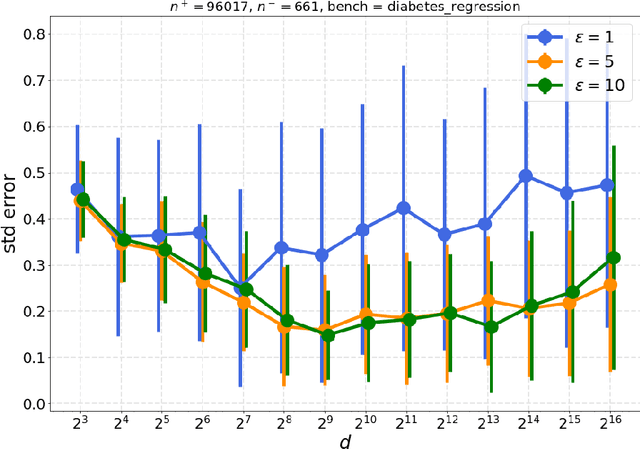
In this paper, we study the problem of computing $U$-statistics of degree $2$, i.e., quantities that come in the form of averages over pairs of data points, in the local model of differential privacy (LDP). The class of $U$-statistics covers many statistical estimates of interest, including Gini mean difference, Kendall's tau coefficient and Area under the ROC Curve (AUC), as well as empirical risk measures for machine learning problems such as ranking, clustering and metric learning. We first introduce an LDP protocol based on quantizing the data into bins and applying randomized response, which guarantees an $\epsilon$-LDP estimate with a Mean Squared Error (MSE) of $O(1/\sqrt{n}\epsilon)$ under regularity assumptions on the $U$-statistic or the data distribution. We then propose a specialized protocol for AUC based on a novel use of hierarchical histograms that achieves MSE of $O(\alpha^3/n\epsilon^2)$ for arbitrary data distribution. We also show that 2-party secure computation allows to design a protocol with MSE of $O(1/n\epsilon^2)$, without any assumption on the kernel function or data distribution and with total communication linear in the number of users $n$. Finally, we evaluate the performance of our protocols through experiments on synthetic and real datasets.
QUOTIENT: Two-Party Secure Neural Network Training and Prediction
Jul 08, 2019



Recently, there has been a wealth of effort devoted to the design of secure protocols for machine learning tasks. Much of this is aimed at enabling secure prediction from highly-accurate Deep Neural Networks (DNNs). However, as DNNs are trained on data, a key question is how such models can be also trained securely. The few prior works on secure DNN training have focused either on designing custom protocols for existing training algorithms, or on developing tailored training algorithms and then applying generic secure protocols. In this work, we investigate the advantages of designing training algorithms alongside a novel secure protocol, incorporating optimizations on both fronts. We present QUOTIENT, a new method for discretized training of DNNs, along with a customized secure two-party protocol for it. QUOTIENT incorporates key components of state-of-the-art DNN training such as layer normalization and adaptive gradient methods, and improves upon the state-of-the-art in DNN training in two-party computation. Compared to prior work, we obtain an improvement of 50X in WAN time and 6% in absolute accuracy.
TAPAS: Tricks to Accelerate Prediction As a Service
Jun 09, 2018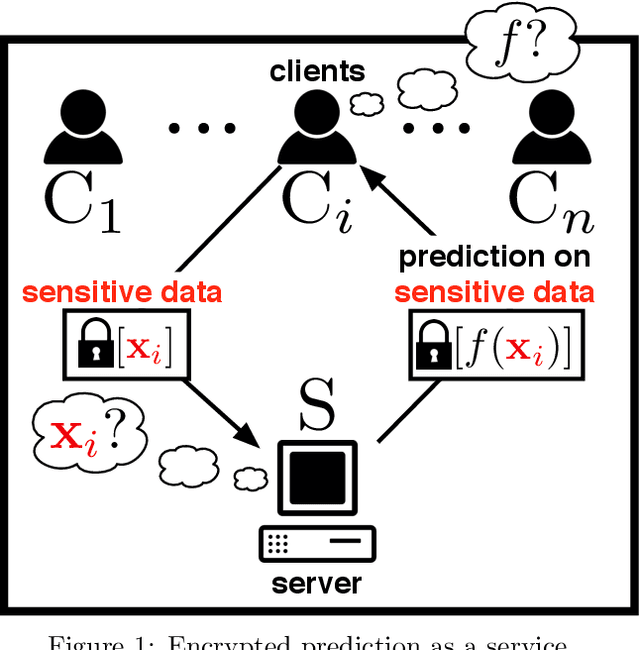
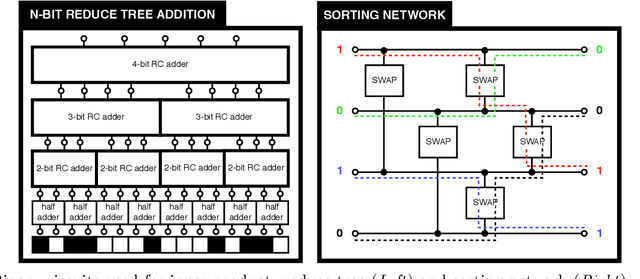
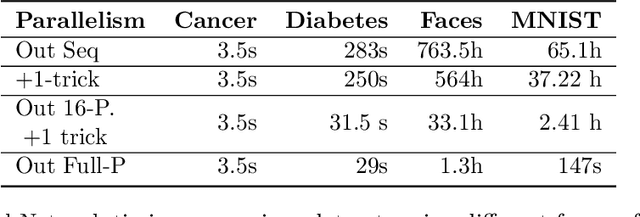
Machine learning methods are widely used for a variety of prediction problems. \emph{Prediction as a service} is a paradigm in which service providers with technological expertise and computational resources may perform predictions for clients. However, data privacy severely restricts the applicability of such services, unless measures to keep client data private (even from the service provider) are designed. Equally important is to minimize the amount of computation and communication required between client and server. Fully homomorphic encryption offers a possible way out, whereby clients may encrypt their data, and on which the server may perform arithmetic computations. The main drawback of using fully homomorphic encryption is the amount of time required to evaluate large machine learning models on encrypted data. We combine ideas from the machine learning literature, particularly work on binarization and sparsification of neural networks, together with algorithmic tools to speed-up and parallelize computation using encrypted data.
Blind Justice: Fairness with Encrypted Sensitive Attributes
Jun 08, 2018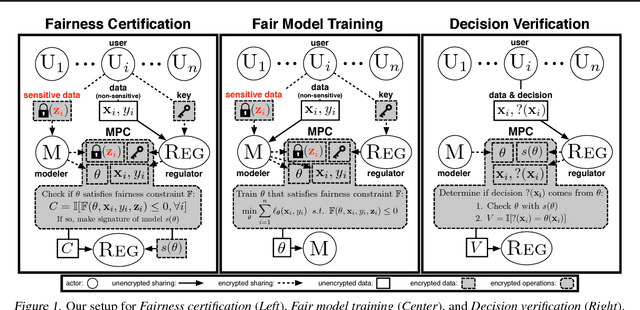
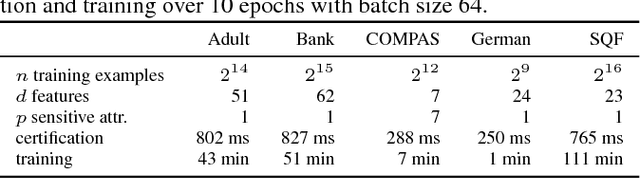
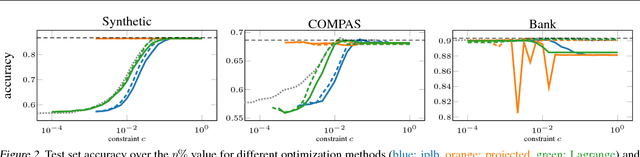
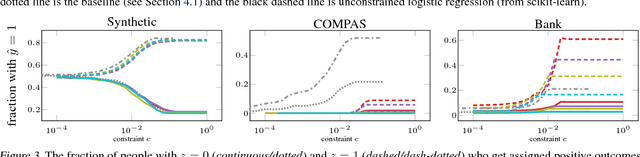
Recent work has explored how to train machine learning models which do not discriminate against any subgroup of the population as determined by sensitive attributes such as gender or race. To avoid disparate treatment, sensitive attributes should not be considered. On the other hand, in order to avoid disparate impact, sensitive attributes must be examined, e.g., in order to learn a fair model, or to check if a given model is fair. We introduce methods from secure multi-party computation which allow us to avoid both. By encrypting sensitive attributes, we show how an outcome-based fair model may be learned, checked, or have its outputs verified and held to account, without users revealing their sensitive attributes.
* published at ICML 2018