 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing the Reachability Value of Posterior-Deterministic POMDPs
Feb 07, 2026Partially observable Markov decision processes (POMDPs) are a fundamental model for sequential decision-making under uncertainty. However, many verification and synthesis problems for POMDPs are undecidable or intractable. Most prominently, the seminal result of Madani et al. (2003) states that there is no algorithm that, given a POMDP and a set of target states, can compute the maximal probability of reaching the target states, or even approximate it up to a non-trivial constant. This is in stark contrast to fully observable Markov decision processes (MDPs), where the reachability value can be computed in polynomial time. In this work, we introduce posterior-deterministic POMDPs, a novel class of POMDPs. Our main technical contribution is to show that for posterior-deterministic POMDPs, the maximal probability of reaching a given set of states can be approximated up to arbitrary precision. A POMDP is posterior-deterministic if the next state can be uniquely determined by the current state, the action taken, and the observation received. While the actual state is generally uncertain in POMDPs, the posterior-deterministic property tells us that once the true state is known it remains known forever. This simple and natural definition includes all MDPs and captures classical non-trivial examples such as the Tiger POMDP (Kaelbling et al. 1998), making it one of the largest known classes of POMDPs for which the reachability value can be approximated.
GPU accelerated program synthesis: Enumerate semantics, not syntax!
Apr 26, 2025Program synthesis is an umbrella term for generating programs and logical formulae from specifications. With the remarkable performance improvements that GPUs enable for deep learning, a natural question arose: can we also implement a search-based program synthesiser on GPUs to achieve similar performance improvements? In this article we discuss our insights on this question, based on recent works~. The goal is to build a synthesiser running on GPUs which takes as input positive and negative example traces and returns a logical formula accepting the positive and rejecting the negative traces. With GPU-friendly programming techniques -- using the semantics of formulae to minimise data movement and reduce data-dependent branching -- our synthesiser scales to significantly larger synthesis problems, and operates much faster than the previous CPU-based state-of-the-art. We believe the insights that make our approach GPU-friendly have wide potential for enhancing the performance of other formal methods (FM) workloads.
EcoSearch: A Constant-Delay Best-First Search Algorithm for Program Synthesis
Dec 23, 2024Many approaches to program synthesis perform a combinatorial search within a large space of programs to find one that satisfies a given specification. To tame the search space blowup, previous works introduced probabilistic and neural approaches to guide this combinatorial search by inducing heuristic cost functions. Best-first search algorithms ensure to search in the exact order induced by the cost function, significantly reducing the portion of the program space to be explored. We present a new best-first search algorithm called EcoSearch, which is the first constant-delay algorithm for pre-generation cost function: the amount of compute required between outputting two programs is constant, and in particular does not increase over time. This key property yields important speedups: we observe that EcoSearch outperforms its predecessors on two classic domains.
Revelations: A Decidable Class of POMDPs with Omega-Regular Objectives
Dec 16, 2024



Partially observable Markov decision processes (POMDPs) form a prominent model for uncertainty in sequential decision making. We are interested in constructing algorithms with theoretical guarantees to determine whether the agent has a strategy ensuring a given specification with probability 1. This well-studied problem is known to be undecidable already for very simple omega-regular objectives, because of the difficulty of reasoning on uncertain events. We introduce a revelation mechanism which restricts information loss by requiring that almost surely the agent has eventually full information of the current state. Our main technical results are to construct exact algorithms for two classes of POMDPs called weakly and strongly revealing. Importantly, the decidable cases reduce to the analysis of a finite belief-support Markov decision process. This yields a conceptually simple and exact algorithm for a large class of POMDPs.
LTL learning on GPUs
Feb 19, 2024Linear temporal logic (LTL) is widely used in industrial verification. LTL formulae can be learned from traces. Scaling LTL formula learning is an open problem. We implement the first GPU-based LTL learner using a novel form of enumerative program synthesis. The learner is sound and complete. Our benchmarks indicate that it handles traces at least 2048 times more numerous, and on average at least 46 times faster than existing state-of-the-art learners. This is achieved with, among others, novel branch-free LTL semantics that has $O(\log n)$ time complexity, where $n$ is trace length, while previous implementations are $O(n^2)$ or worse (assuming bitwise boolean operations and shifts by powers of 2 have unit costs -- a realistic assumption on modern processors).
Theoretical foundations for programmatic reinforcement learning
Feb 18, 2024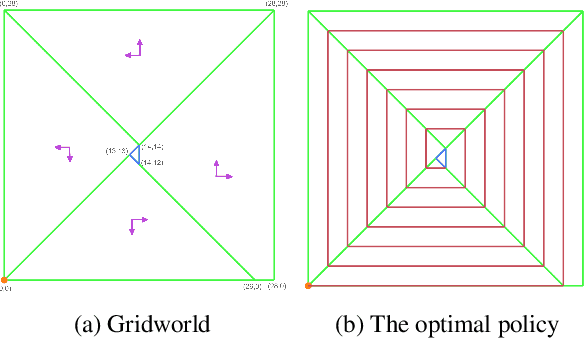
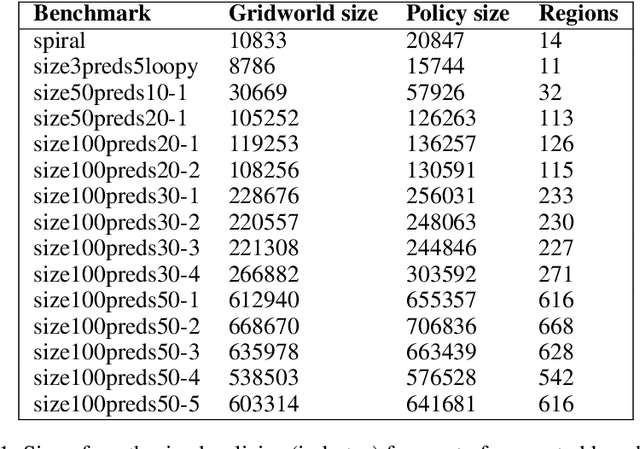
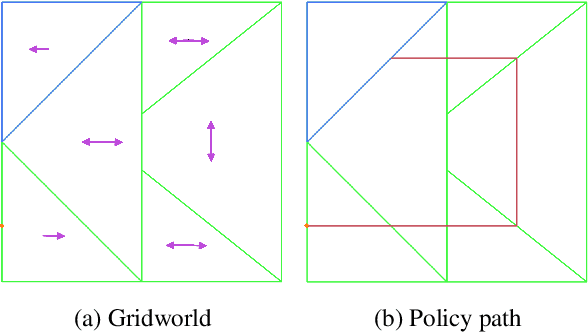

The field of Reinforcement Learning (RL) is concerned with algorithms for learning optimal policies in unknown stochastic environments. Programmatic RL studies representations of policies as programs, meaning involving higher order constructs such as control loops. Despite attracting a lot of attention at the intersection of the machine learning and formal methods communities, very little is known on the theoretical front about programmatic RL: what are good classes of programmatic policies? How large are optimal programmatic policies? How can we learn them? The goal of this paper is to give first answers to these questions, initiating a theoretical study of programmatic RL.
Learning temporal formulas from examples is hard
Dec 26, 2023We study the problem of learning linear temporal logic (LTL) formulas from examples, as a first step towards expressing a property separating positive and negative instances in a way that is comprehensible for humans. In this paper we initiate the study of the computational complexity of the problem. Our main results are hardness results: we show that the LTL learning problem is NP-complete, both for the full logic and for almost all of its fragments. This motivates the search for efficient heuristics, and highlights the complexity of expressing separating properties in concise natural language.
WikiCoder: Learning to Write Knowledge-Powered Code
Mar 15, 2023We tackle the problem of automatic generation of computer programs from a few pairs of input-output examples. The starting point of this work is the observation that in many applications a solution program must use external knowledge not present in the examples: we call such programs knowledge-powered since they can refer to information collected from a knowledge graph such as Wikipedia. This paper makes a first step towards knowledge-powered program synthesis. We present WikiCoder, a system building upon state of the art machine-learned program synthesizers and integrating knowledge graphs. We evaluate it to show its wide applicability over different domains and discuss its limitations. WikiCoder solves tasks that no program synthesizers were able to solve before thanks to the use of knowledge graphs, while integrating with recent developments in the field to operate at scale.
Scalable Anytime Algorithms for Learning Formulas in Linear Temporal Logic
Oct 27, 2021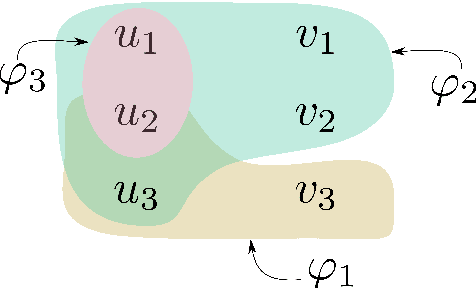
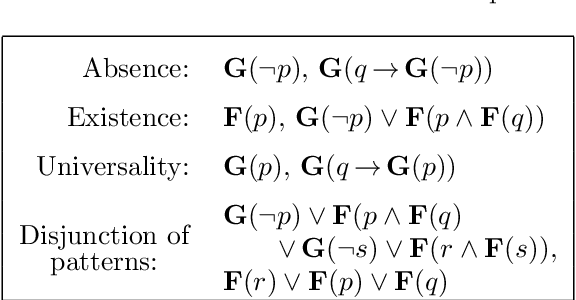
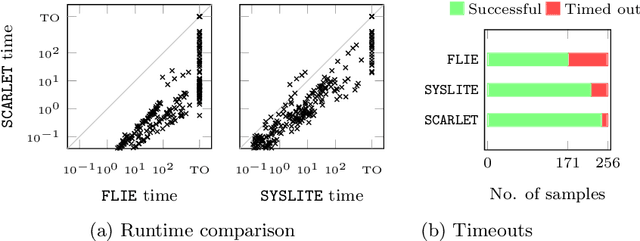
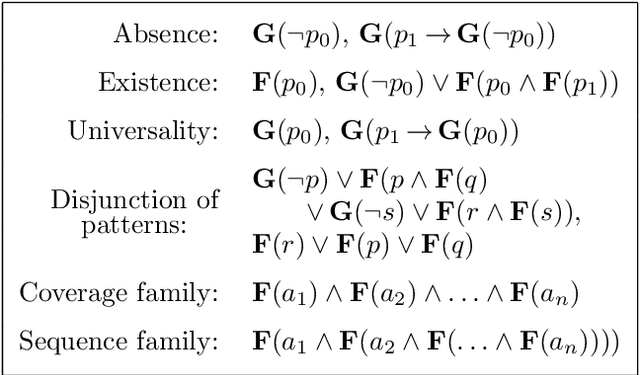
Linear temporal logic (LTL) is a specification language for finite sequences (called traces) widely used in program verification, motion planning in robotics, process mining, and many other areas. We consider the problem of learning LTL formulas for classifying traces; despite a growing interest of the research community, existing solutions suffer from two limitations: they do not scale beyond small formulas, and they may exhaust computational resources without returning any result. We introduce a new algorithm addressing both issues: our algorithm is able to construct formulas an order of magnitude larger than previous methods, and it is anytime, meaning that it in most cases successfully outputs a formula, albeit possibly not of minimal size. We evaluate the performances of our algorithm using an open source implementation against publicly available benchmarks.
Scaling Neural Program Synthesis with Distribution-based Search
Oct 24, 2021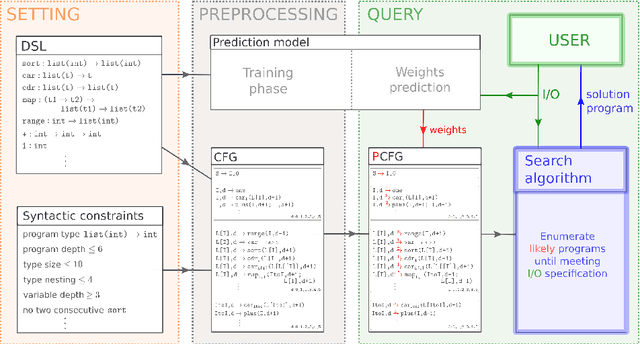
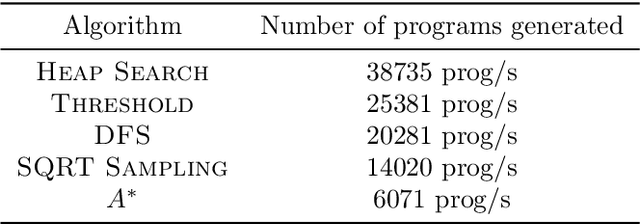
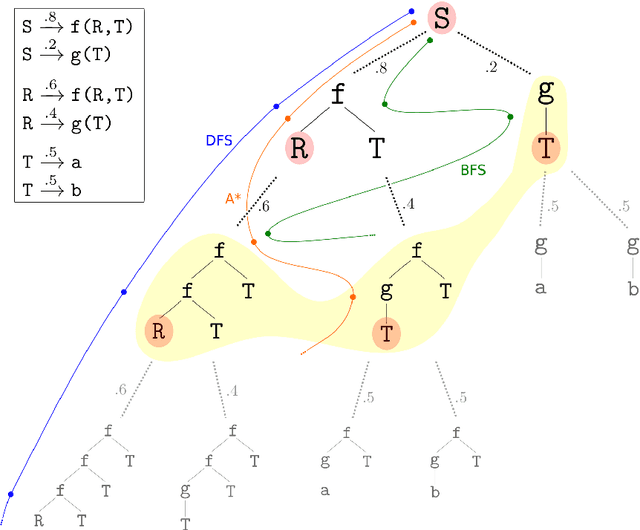
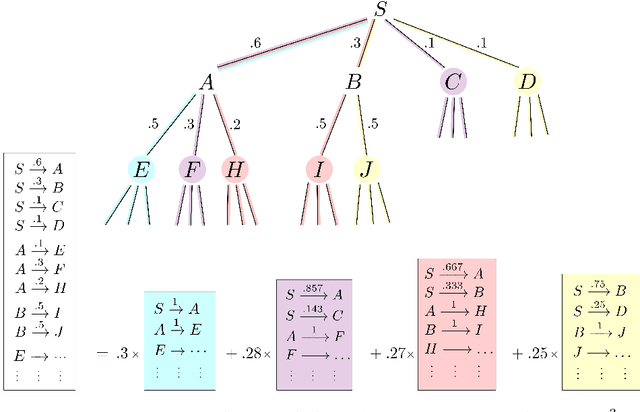
We consider the problem of automatically constructing computer programs from input-output examples. We investigate how to augment probabilistic and neural program synthesis methods with new search algorithms, proposing a framework called distribution-based search. Within this framework, we introduce two new search algorithms: Heap Search, an enumerative method, and SQRT Sampling, a probabilistic method. We prove certain optimality guarantees for both methods, show how they integrate with probabilistic and neural techniques, and demonstrate how they can operate at scale across parallel compute environments. Collectively these findings offer theoretical and applied studies of search algorithms for program synthesis that integrate with recent developments in machine-learned program synthesizers.