 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevelations: A Decidable Class of POMDPs with Omega-Regular Objectives
Dec 16, 2024



Partially observable Markov decision processes (POMDPs) form a prominent model for uncertainty in sequential decision making. We are interested in constructing algorithms with theoretical guarantees to determine whether the agent has a strategy ensuring a given specification with probability 1. This well-studied problem is known to be undecidable already for very simple omega-regular objectives, because of the difficulty of reasoning on uncertain events. We introduce a revelation mechanism which restricts information loss by requiring that almost surely the agent has eventually full information of the current state. Our main technical results are to construct exact algorithms for two classes of POMDPs called weakly and strongly revealing. Importantly, the decidable cases reduce to the analysis of a finite belief-support Markov decision process. This yields a conceptually simple and exact algorithm for a large class of POMDPs.
Rhoban Football Club: RoboCup Humanoid Kid-Size 2023 Champion Team Paper
Feb 01, 2024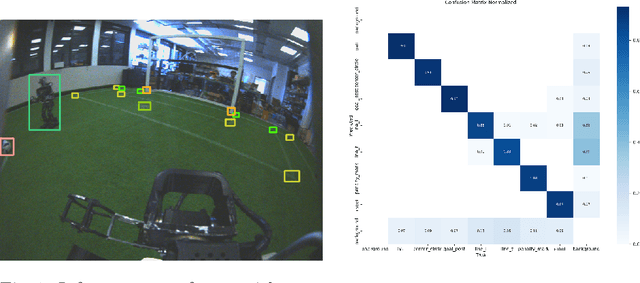
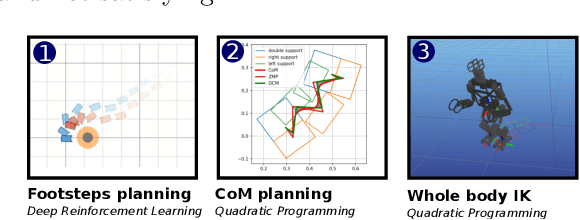
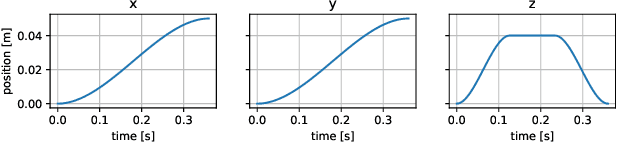
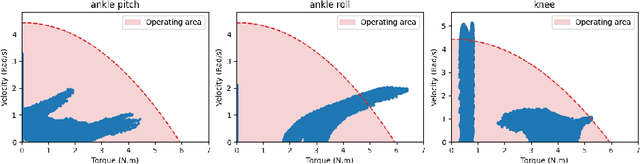
In 2023, Rhoban Football Club reached the first place of the KidSize soccer competition for the fifth time, and received the best humanoid award. This paper presents and reviews important points in robots architecture and workflow, with hindsights from the competition.
Online Reinforcement Learning for Real-Time Exploration in Continuous State and Action Markov Decision Processes
Dec 12, 2016



This paper presents a new method to learn online policies in continuous state, continuous action, model-free Markov decision processes, with two properties that are crucial for practical applications. First, the policies are implementable with a very low computational cost: once the policy is computed, the action corresponding to a given state is obtained in logarithmic time with respect to the number of samples used. Second, our method is versatile: it does not rely on any a priori knowledge of the structure of optimal policies. We build upon the Fitted Q-iteration algorithm which represents the $Q$-value as the average of several regression trees. Our algorithm, the Fitted Policy Forest algorithm (FPF), computes a regression forest representing the Q-value and transforms it into a single tree representing the policy, while keeping control on the size of the policy using resampling and leaf merging. We introduce an adaptation of Multi-Resolution Exploration (MRE) which is particularly suited to FPF. We assess the performance of FPF on three classical benchmarks for reinforcement learning: the "Inverted Pendulum", the "Double Integrator" and "Car on the Hill" and show that FPF equals or outperforms other algorithms, although these algorithms rely on the use of particular representations of the policies, especially chosen in order to fit each of the three problems. Finally, we exhibit that the combination of FPF and MRE allows to find nearly optimal solutions in problems where $\epsilon$-greedy approaches would fail.