 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing the Reachability Value of Posterior-Deterministic POMDPs
Feb 07, 2026Partially observable Markov decision processes (POMDPs) are a fundamental model for sequential decision-making under uncertainty. However, many verification and synthesis problems for POMDPs are undecidable or intractable. Most prominently, the seminal result of Madani et al. (2003) states that there is no algorithm that, given a POMDP and a set of target states, can compute the maximal probability of reaching the target states, or even approximate it up to a non-trivial constant. This is in stark contrast to fully observable Markov decision processes (MDPs), where the reachability value can be computed in polynomial time. In this work, we introduce posterior-deterministic POMDPs, a novel class of POMDPs. Our main technical contribution is to show that for posterior-deterministic POMDPs, the maximal probability of reaching a given set of states can be approximated up to arbitrary precision. A POMDP is posterior-deterministic if the next state can be uniquely determined by the current state, the action taken, and the observation received. While the actual state is generally uncertain in POMDPs, the posterior-deterministic property tells us that once the true state is known it remains known forever. This simple and natural definition includes all MDPs and captures classical non-trivial examples such as the Tiger POMDP (Kaelbling et al. 1998), making it one of the largest known classes of POMDPs for which the reachability value can be approximated.
Analyzing Value Functions of States in Parametric Markov Chains
Apr 23, 2025Parametric Markov chains (pMC) are used to model probabilistic systems with unknown or partially known probabilities. Although (universal) pMC verification for reachability properties is known to be coETR-complete, there have been efforts to approach it using potentially easier-to-check properties such as asking whether the pMC is monotonic in certain parameters. In this paper, we first reduce monotonicity to asking whether the reachability probability from a given state is never less than that of another given state. Recent results for the latter property imply an efficient algorithm to collapse same-value equivalence classes, which in turn preserves verification results and monotonicity. We implement our algorithm to collapse "trivial" equivalence classes in the pMC and show empirical evidence for the following: First, the collapse gives reductions in size for some existing benchmarks and significant reductions on some custom benchmarks; Second, the collapse speeds up existing algorithms to check monotonicity and parameter lifting, and hence can be used as a fast pre-processing step in practice.
Revelations: A Decidable Class of POMDPs with Omega-Regular Objectives
Dec 16, 2024



Partially observable Markov decision processes (POMDPs) form a prominent model for uncertainty in sequential decision making. We are interested in constructing algorithms with theoretical guarantees to determine whether the agent has a strategy ensuring a given specification with probability 1. This well-studied problem is known to be undecidable already for very simple omega-regular objectives, because of the difficulty of reasoning on uncertain events. We introduce a revelation mechanism which restricts information loss by requiring that almost surely the agent has eventually full information of the current state. Our main technical results are to construct exact algorithms for two classes of POMDPs called weakly and strongly revealing. Importantly, the decidable cases reduce to the analysis of a finite belief-support Markov decision process. This yields a conceptually simple and exact algorithm for a large class of POMDPs.
Active Learning of Mealy Machines with Timers
Mar 04, 2024

We present the first algorithm for query learning of a general class of Mealy machines with timers (MMTs) in a black-box context. Our algorithm is an extension of the L# algorithm of Vaandrager et al. to a timed setting. Like the algorithm for learning timed automata proposed by Waga, our algorithm is inspired by ideas of Maler & Pnueli. Based on the elementary languages of, both Waga's and our algorithm use symbolic queries, which are then implemented using finitely many concrete queries. However, whereas Waga needs exponentially many concrete queries to implement a single symbolic query, we only need a polynomial number. This is because in order to learn a timed automaton, a learner needs to determine the exact guard and reset for each transition (out of exponentially many possibilities), whereas for learning an MMT a learner only needs to figure out which of the preceding transitions caused a timeout. As shown in our previous work, this can be done efficiently for a subclass of MMTs that are race-avoiding: if a timeout is caused by a preceding input then a slight change in the timing of this input will induce a corresponding change in the timing of the timeout ("wiggling"). Experiments with a prototype implementation, written in Rust, show that our algorithm is able to efficiently learn realistic benchmarks.
Synthesis of Hierarchical Controllers Based on Deep Reinforcement Learning Policies
Feb 21, 2024
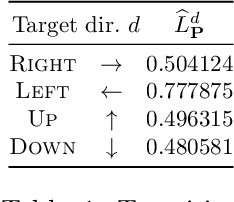
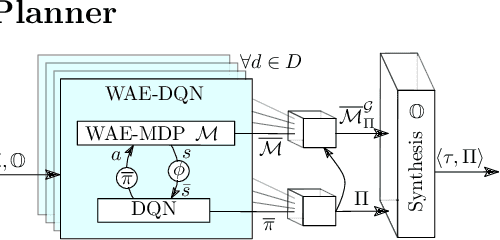
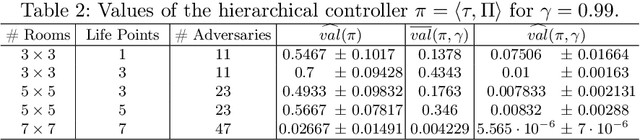
We propose a novel approach to the problem of controller design for environments modeled as Markov decision processes (MDPs). Specifically, we consider a hierarchical MDP a graph with each vertex populated by an MDP called a "room". We first apply deep reinforcement learning (DRL) to obtain low-level policies for each room, scaling to large rooms of unknown structure. We then apply reactive synthesis to obtain a high-level planner that chooses which low-level policy to execute in each room. The central challenge in synthesizing the planner is the need for modeling rooms. We address this challenge by developing a DRL procedure to train concise "latent" policies together with PAC guarantees on their performance. Unlike previous approaches, ours circumvents a model distillation step. Our approach combats sparse rewards in DRL and enables reusability of low-level policies. We demonstrate feasibility in a case study involving agent navigation amid moving obstacles.
Formally-Sharp DAgger for MCTS: Lower-Latency Monte Carlo Tree Search using Data Aggregation with Formal Methods
Aug 15, 2023



We study how to efficiently combine formal methods, Monte Carlo Tree Search (MCTS), and deep learning in order to produce high-quality receding horizon policies in large Markov Decision processes (MDPs). In particular, we use model-checking techniques to guide the MCTS algorithm in order to generate offline samples of high-quality decisions on a representative set of states of the MDP. Those samples can then be used to train a neural network that imitates the policy used to generate them. This neural network can either be used as a guide on a lower-latency MCTS online search, or alternatively be used as a full-fledged policy when minimal latency is required. We use statistical model checking to detect when additional samples are needed and to focus those additional samples on configurations where the learnt neural network policy differs from the (computationally-expensive) offline policy. We illustrate the use of our method on MDPs that model the Frozen Lake and Pac-Man environments -- two popular benchmarks to evaluate reinforcement-learning algorithms.
Graph-Based Reductions for Parametric and Weighted MDPs
May 09, 2023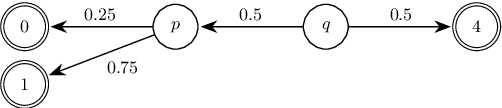

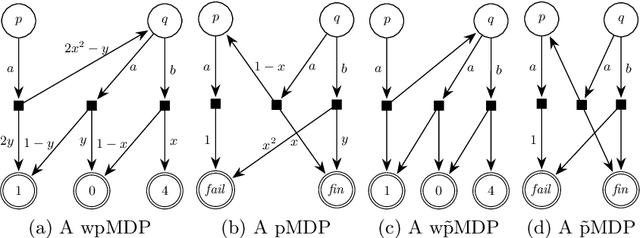
We study the complexity of reductions for weighted reachability in parametric Markov decision processes. That is, we say a state p is never worse than q if for all valuations of the polynomial indeterminates it is the case that the maximal expected weight that can be reached from p is greater than the same value from q. In terms of computational complexity, we establish that determining whether p is never worse than q is coETR-complete. On the positive side, we give a polynomial-time algorithm to compute the equivalence classes of the order we study for Markov chains. Additionally, we describe and implement two inference rules to under-approximate the never-worse relation and empirically show that it can be used as an efficient preprocessing step for the analysis of large Markov decision processes.
Wasserstein Auto-encoded MDPs: Formal Verification of Efficiently Distilled RL Policies with Many-sided Guarantees
Mar 22, 2023



Although deep reinforcement learning (DRL) has many success stories, the large-scale deployment of policies learned through these advanced techniques in safety-critical scenarios is hindered by their lack of formal guarantees. Variational Markov Decision Processes (VAE-MDPs) are discrete latent space models that provide a reliable framework for distilling formally verifiable controllers from any RL policy. While the related guarantees address relevant practical aspects such as the satisfaction of performance and safety properties, the VAE approach suffers from several learning flaws (posterior collapse, slow learning speed, poor dynamics estimates), primarily due to the absence of abstraction and representation guarantees to support latent optimization. We introduce the Wasserstein auto-encoded MDP (WAE-MDP), a latent space model that fixes those issues by minimizing a penalized form of the optimal transport between the behaviors of the agent executing the original policy and the distilled policy, for which the formal guarantees apply. Our approach yields bisimulation guarantees while learning the distilled policy, allowing concrete optimization of the abstraction and representation model quality. Our experiments show that, besides distilling policies up to 10 times faster, the latent model quality is indeed better in general. Moreover, we present experiments from a simple time-to-failure verification algorithm on the latent space. The fact that our approach enables such simple verification techniques highlights its applicability.
The Wasserstein Believer: Learning Belief Updates for Partially Observable Environments through Reliable Latent Space Models
Mar 06, 2023



Partially Observable Markov Decision Processes (POMDPs) are useful tools to model environments where the full state cannot be perceived by an agent. As such the agent needs to reason taking into account the past observations and actions. However, simply remembering the full history is generally intractable due to the exponential growth in the history space. Keeping a probability distribution that models the belief over what the true state is can be used as a sufficient statistic of the history, but its computation requires access to the model of the environment and is also intractable. Current state-of-the-art algorithms use Recurrent Neural Networks (RNNs) to compress the observation-action history aiming to learn a sufficient statistic, but they lack guarantees of success and can lead to suboptimal policies. To overcome this, we propose the Wasserstein-Belief-Updater (WBU), an RL algorithm that learns a latent model of the POMDP and an approximation of the belief update. Our approach comes with theoretical guarantees on the quality of our approximation ensuring that our outputted beliefs allow for learning the optimal value function.
Distillation of RL Policies with Formal Guarantees via Variational Abstraction of Markov Decision Processes (Technical Report)
Dec 17, 2021



We consider the challenge of policy simplification and verification in the context of policies learned through reinforcement learning (RL) in continuous environments. In well-behaved settings, RL algorithms have convergence guarantees in the limit. While these guarantees are valuable, they are insufficient for safety-critical applications. Furthermore, they are lost when applying advanced techniques such as deep-RL. To recover guarantees when applying advanced RL algorithms to more complex environments with (i) reachability, (ii) safety-constrained reachability, or (iii) discounted-reward objectives, we build upon the DeepMDP framework introduced by Gelada et al. to derive new bisimulation bounds between the unknown environment and a learned discrete latent model of it. Our bisimulation bounds enable the application of formal methods for Markov decision processes. Finally, we show how one can use a policy obtained via state-of-the-art RL to efficiently train a variational autoencoder that yields a discrete latent model with provably approximately correct bisimulation guarantees. Additionally, we obtain a distilled version of the policy for the latent model.