 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Omega-Regular Specifications on Continuous-Time MDP
Mar 16, 2023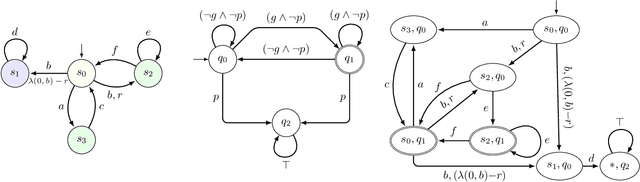



Continuous-time Markov decision processes (CTMDPs) are canonical models to express sequential decision-making under dense-time and stochastic environments. When the stochastic evolution of the environment is only available via sampling, model-free reinforcement learning (RL) is the algorithm-of-choice to compute optimal decision sequence. RL, on the other hand, requires the learning objective to be encoded as scalar reward signals. Since doing such translations manually is both tedious and error-prone, a number of techniques have been proposed to translate high-level objectives (expressed in logic or automata formalism) to scalar rewards for discrete-time Markov decision processes (MDPs). Unfortunately, no automatic translation exists for CTMDPs. We consider CTMDP environments against the learning objectives expressed as omega-regular languages. Omega-regular languages generalize regular languages to infinite-horizon specifications and can express properties given in popular linear-time logic LTL. To accommodate the dense-time nature of CTMDPs, we consider two different semantics of omega-regular objectives: 1) satisfaction semantics where the goal of the learner is to maximize the probability of spending positive time in the good states, and 2) expectation semantics where the goal of the learner is to optimize the long-run expected average time spent in the ``good states" of the automaton. We present an approach enabling correct translation to scalar reward signals that can be readily used by off-the-shelf RL algorithms for CTMDPs. We demonstrate the effectiveness of the proposed algorithms by evaluating it on some popular CTMDP benchmarks with omega-regular objectives.
PAC Statistical Model Checking of Mean Payoff in Discrete- and Continuous-Time MDP
Jun 03, 2022


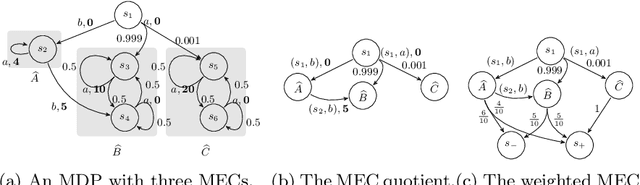
Markov decision processes (MDP) and continuous-time MDP (CTMDP) are the fundamental models for non-deterministic systems with probabilistic uncertainty. Mean payoff (a.k.a. long-run average reward) is one of the most classic objectives considered in their context. We provide the first algorithm to compute mean payoff probably approximately correctly in unknown MDP; further, we extend it to unknown CTMDP. We do not require any knowledge of the state space, only a lower bound on the minimum transition probability, which has been advocated in literature. In addition to providing probably approximately correct (PAC) bounds for our algorithm, we also demonstrate its practical nature by running experiments on standard benchmarks.
Safe Learning for Near Optimal Scheduling
May 19, 2020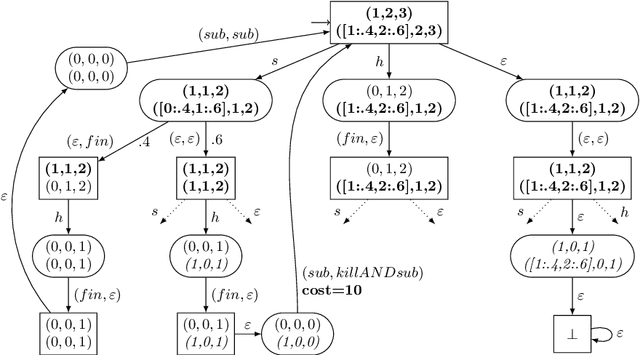
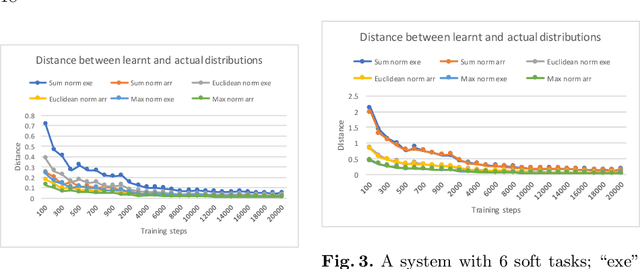
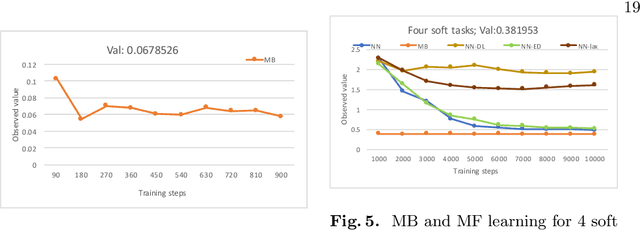
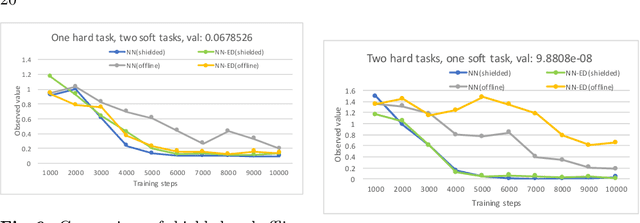
In this paper, we investigate the combination of synthesis techniques and learning techniques to obtain safe and near optimal schedulers for a preemptible task scheduling problem. We study both model-based learning techniques with PAC guarantees and model-free learning techniques based on shielded deep Q-learning. The new learning algorithms have been implemented to conduct experimental evaluations.
Mixing Probabilistic and non-Probabilistic Objectives in Markov Decision Processes
Apr 28, 2020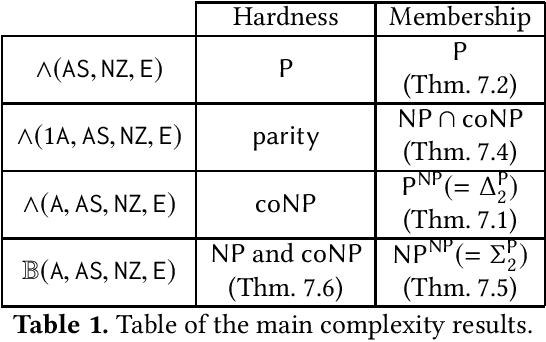
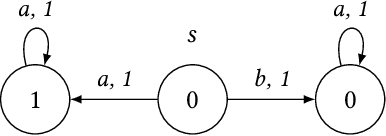
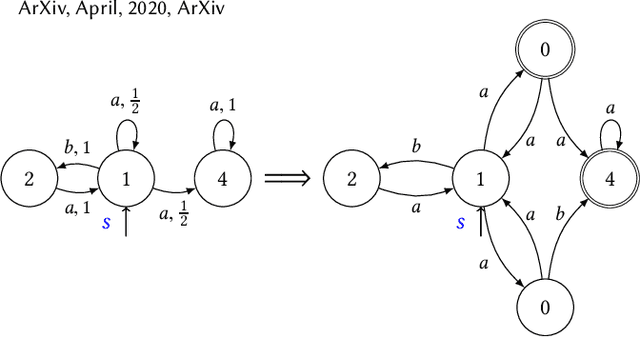
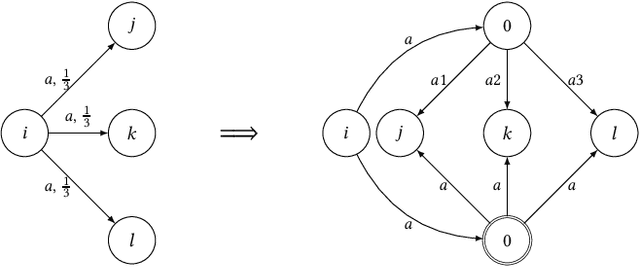
In this paper, we consider algorithms to decide the existence of strategies in MDPs for Boolean combinations of objectives. These objectives are omega-regular properties that need to be enforced either surely, almost surely, existentially, or with non-zero probability. In this setting, relevant strategies are randomized infinite memory strategies: both infinite memory and randomization may be needed to play optimally. We provide algorithms to solve the general case of Boolean combinations and we also investigate relevant subcases. We further report on complexity bounds for these problems.