 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Omega-Regular Specifications on Continuous-Time MDP
Paper and Code
Mar 16, 2023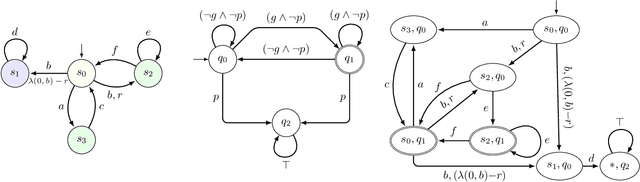



Continuous-time Markov decision processes (CTMDPs) are canonical models to express sequential decision-making under dense-time and stochastic environments. When the stochastic evolution of the environment is only available via sampling, model-free reinforcement learning (RL) is the algorithm-of-choice to compute optimal decision sequence. RL, on the other hand, requires the learning objective to be encoded as scalar reward signals. Since doing such translations manually is both tedious and error-prone, a number of techniques have been proposed to translate high-level objectives (expressed in logic or automata formalism) to scalar rewards for discrete-time Markov decision processes (MDPs). Unfortunately, no automatic translation exists for CTMDPs. We consider CTMDP environments against the learning objectives expressed as omega-regular languages. Omega-regular languages generalize regular languages to infinite-horizon specifications and can express properties given in popular linear-time logic LTL. To accommodate the dense-time nature of CTMDPs, we consider two different semantics of omega-regular objectives: 1) satisfaction semantics where the goal of the learner is to maximize the probability of spending positive time in the good states, and 2) expectation semantics where the goal of the learner is to optimize the long-run expected average time spent in the ``good states" of the automaton. We present an approach enabling correct translation to scalar reward signals that can be readily used by off-the-shelf RL algorithms for CTMDPs. We demonstrate the effectiveness of the proposed algorithms by evaluating it on some popular CTMDP benchmarks with omega-regular objectives.