 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Near-Optimal Gate Control: A Case Study from the Danish West Coast
Apr 06, 2026Ringkoebing Fjord is an inland water basin on the Danish west coast separated from the North Sea by a set of gates used to control the amount of water entering and leaving the fjord. Currently, human operators decide when and how many gates to open or close for controlling the fjord's water level, with the goal to satisfy a range of conflicting safety and performance requirements such as keeping the water level in a target range, allowing maritime traffic, and enabling fish migration. Uppaal Stratego. We then use this digital twin along with forecasts of the sea level and the wind speed to learn a gate controller in an online fashion. We evaluate the learned controllers under different sea-level scenarios, representing normal tidal behavior, high waters, and low waters. Our evaluation demonstrates that, unlike a baseline controller, the learned controllers satisfy the safety requirements, while performing similarly regarding the other requirements.
* In Proceedings MARS 2026, arXiv:2604.03053
Compositional Shielding and Reinforcement Learning for Multi-Agent Systems
Oct 14, 2024
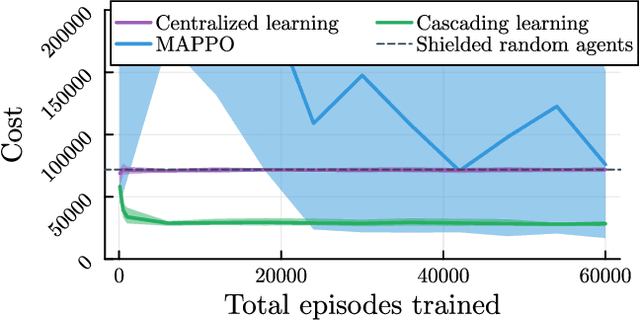
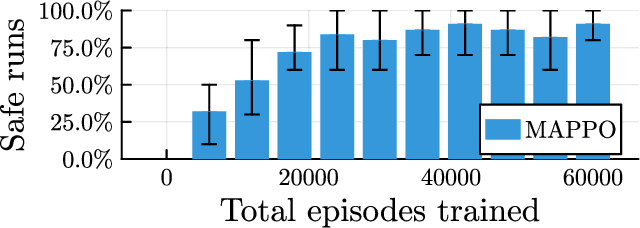
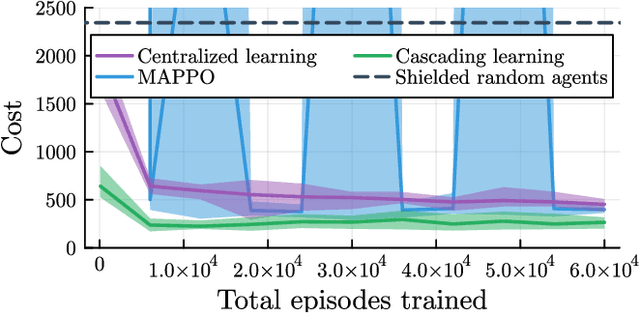
Deep reinforcement learning has emerged as a powerful tool for obtaining high-performance policies. However, the safety of these policies has been a long-standing issue. One promising paradigm to guarantee safety is a shield, which shields a policy from making unsafe actions. However, computing a shield scales exponentially in the number of state variables. This is a particular concern in multi-agent systems with many agents. In this work, we propose a novel approach for multi-agent shielding. We address scalability by computing individual shields for each agent. The challenge is that typical safety specifications are global properties, but the shields of individual agents only ensure local properties. Our key to overcome this challenge is to apply assume-guarantee reasoning. Specifically, we present a sound proof rule that decomposes a (global, complex) safety specification into (local, simple) obligations for the shields of the individual agents. Moreover, we show that applying the shields during reinforcement learning significantly improves the quality of the policies obtained for a given training budget. We demonstrate the effectiveness and scalability of our multi-agent shielding framework in two case studies, reducing the computation time from hours to seconds and achieving fast learning convergence.
In Search of Trees: Decision-Tree Policy Synthesis for Black-Box Systems via Search
Sep 05, 2024



Decision trees, owing to their interpretability, are attractive as control policies for (dynamical) systems. Unfortunately, constructing, or synthesising, such policies is a challenging task. Previous approaches do so by imitating a neural-network policy, approximating a tabular policy obtained via formal synthesis, employing reinforcement learning, or modelling the problem as a mixed-integer linear program. However, these works may require access to a hard-to-obtain accurate policy or a formal model of the environment (within reach of formal synthesis), and may not provide guarantees on the quality or size of the final tree policy. In contrast, we present an approach to synthesise optimal decision-tree policies given a black-box environment and specification, and a discretisation of the tree predicates, where optimality is defined with respect to the number of steps to achieve the goal. Our approach is a specialised search algorithm which systematically explores the (exponentially large) space of decision trees under the given discretisation. The key component is a novel pruning mechanism that significantly reduces the search space. Our approach represents a conceptually novel way of synthesising small decision-tree policies with optimality guarantees even for black-box environments with black-box specifications.
Efficient Shield Synthesis via State-Space Transformation
Jul 29, 2024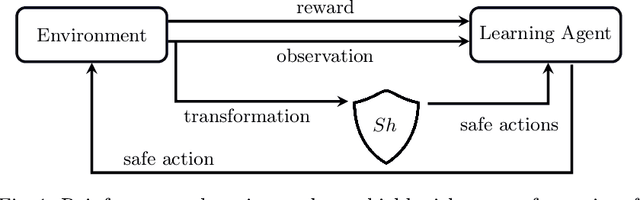
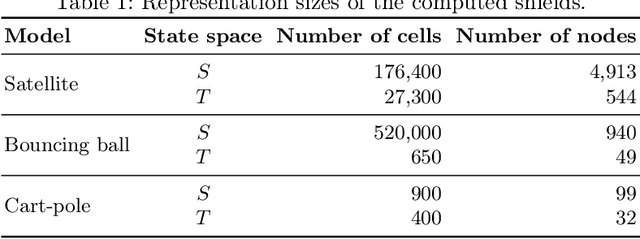
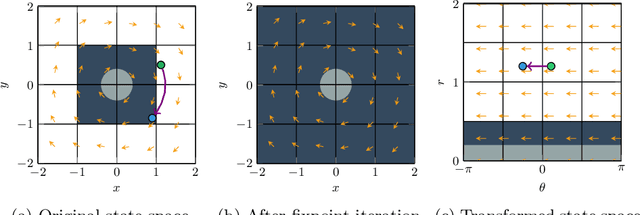

We consider the problem of synthesizing safety strategies for control systems, also known as shields. Since the state space is infinite, shields are typically computed over a finite-state abstraction, with the most common abstraction being a rectangular grid. However, for many systems, such a grid does not align well with the safety property or the system dynamics. That is why a coarse grid is rarely sufficient, but a fine grid is typically computationally infeasible to obtain. In this paper, we show that appropriate state-space transformations can still allow to use a coarse grid at almost no computational overhead. We demonstrate in three case studies that our transformation-based synthesis outperforms a standard synthesis by several orders of magnitude. In the first two case studies, we use domain knowledge to select a suitable transformation. In the third case study, we instead report on results in engineering a transformation without domain knowledge.
The Reachability Problem for Neural-Network Control Systems
Jul 06, 2024A control system consists of a plant component and a controller which periodically computes a control input for the plant. We consider systems where the controller is implemented by a feedforward neural network with ReLU activations. The reachability problem asks, given a set of initial states, whether a set of target states can be reached. We show that this problem is undecidable even for trivial plants and fixed-depth neural networks with three inputs and outputs. We also show that the problem becomes semi-decidable when the plant as well as the input and target sets are given by automata over infinite words.
Synthesis of Hierarchical Controllers Based on Deep Reinforcement Learning Policies
Feb 21, 2024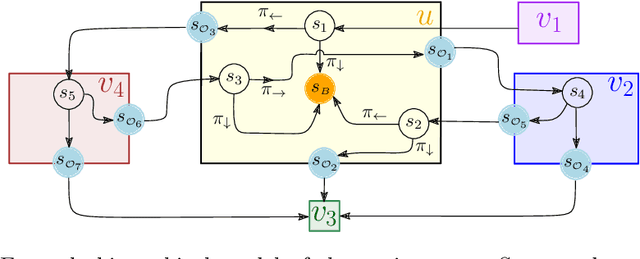
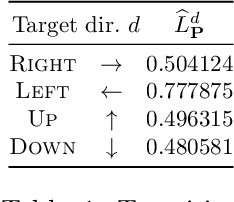
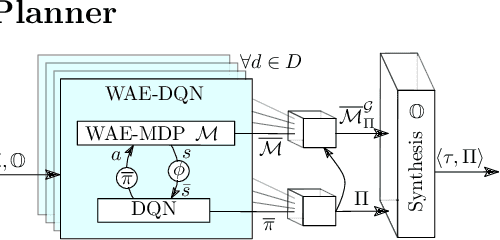
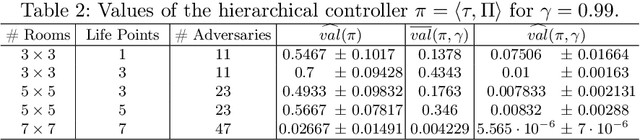
We propose a novel approach to the problem of controller design for environments modeled as Markov decision processes (MDPs). Specifically, we consider a hierarchical MDP a graph with each vertex populated by an MDP called a "room". We first apply deep reinforcement learning (DRL) to obtain low-level policies for each room, scaling to large rooms of unknown structure. We then apply reactive synthesis to obtain a high-level planner that chooses which low-level policy to execute in each room. The central challenge in synthesizing the planner is the need for modeling rooms. We address this challenge by developing a DRL procedure to train concise "latent" policies together with PAC guarantees on their performance. Unlike previous approaches, ours circumvents a model distillation step. Our approach combats sparse rewards in DRL and enables reusability of low-level policies. We demonstrate feasibility in a case study involving agent navigation amid moving obstacles.
Shielded Reinforcement Learning for Hybrid Systems
Aug 28, 2023Safe and optimal controller synthesis for switched-controlled hybrid systems, which combine differential equations and discrete changes of the system's state, is known to be intricately hard. Reinforcement learning has been leveraged to construct near-optimal controllers, but their behavior is not guaranteed to be safe, even when it is encouraged by reward engineering. One way of imposing safety to a learned controller is to use a shield, which is correct by design. However, obtaining a shield for non-linear and hybrid environments is itself intractable. In this paper, we propose the construction of a shield using the so-called barbaric method, where an approximate finite representation of an underlying partition-based two-player safety game is extracted via systematically picked samples of the true transition function. While hard safety guarantees are out of reach, we experimentally demonstrate strong statistical safety guarantees with a prototype implementation and UPPAAL STRATEGO. Furthermore, we study the impact of the synthesized shield when applied as either a pre-shield (applied before learning a controller) or a post-shield (only applied after learning a controller). We experimentally demonstrate superiority of the pre-shielding approach. We apply our technique on a range of case studies, including two industrial examples, and further study post-optimization of the post-shielding approach.
The inverse problem for neural networks
Aug 27, 2023We study the problem of computing the preimage of a set under a neural network with piecewise-affine activation functions. We recall an old result that the preimage of a polyhedral set is again a union of polyhedral sets and can be effectively computed. We show several applications of computing the preimage for analysis and interpretability of neural networks.
Open- and Closed-Loop Neural Network Verification using Polynomial Zonotopes
Jul 06, 2022
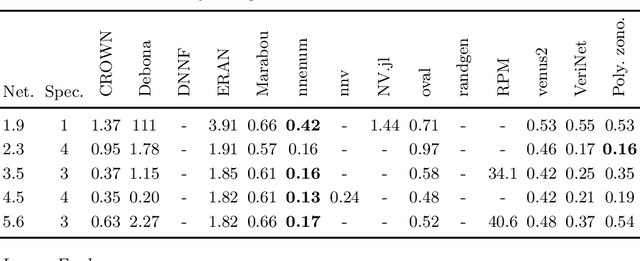
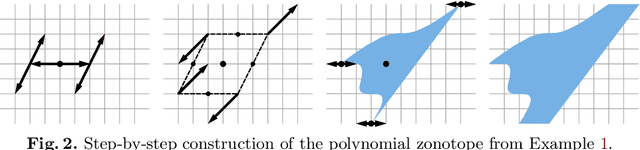
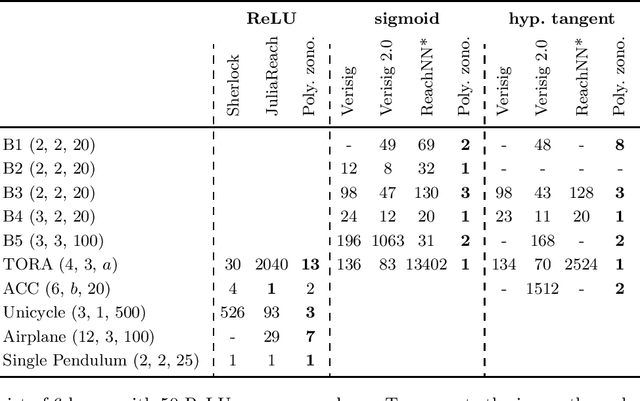
We present a novel approach to efficiently compute tight non-convex enclosures of the image through neural networks with ReLU, sigmoid, or hyperbolic tangent activation functions. In particular, we abstract the input-output relation of each neuron by a polynomial approximation, which is evaluated in a set-based manner using polynomial zonotopes. Our proposed method is especially well suited for reachability analysis of neural network controlled systems since polynomial zonotopes are able to capture the non-convexity in both, the image through the neural network as well as the reachable set. We demonstrate the superior performance of our approach compared to other state of the art methods on various benchmark systems.
Verification of Neural-Network Control Systems by Integrating Taylor Models and Zonotopes
Dec 16, 2021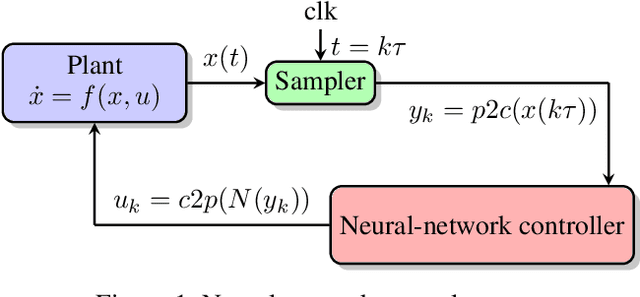
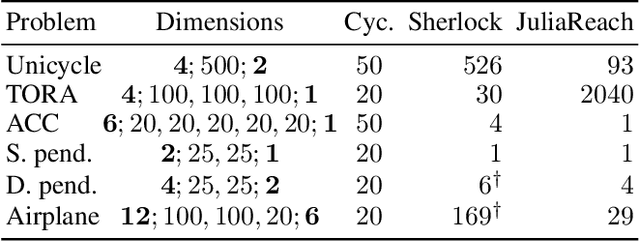

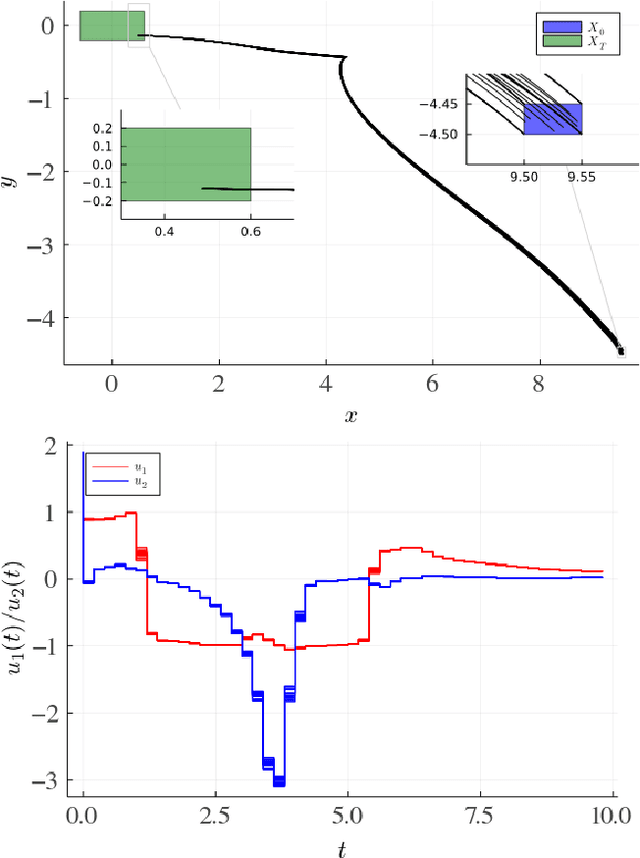
We study the verification problem for closed-loop dynamical systems with neural-network controllers (NNCS). This problem is commonly reduced to computing the set of reachable states. When considering dynamical systems and neural networks in isolation, there exist precise approaches for that task based on set representations respectively called Taylor models and zonotopes. However, the combination of these approaches to NNCS is non-trivial because, when converting between the set representations, dependency information gets lost in each control cycle and the accumulated approximation error quickly renders the result useless. We present an algorithm to chain approaches based on Taylor models and zonotopes, yielding a precise reachability algorithm for NNCS. Because the algorithm only acts at the interface of the isolated approaches, it is applicable to general dynamical systems and neural networks and can benefit from future advances in these areas. Our implementation delivers state-of-the-art performance and is the first to successfully analyze all benchmark problems of an annual reachability competition for NNCS.