 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin-Empowered Voltage Control for Power Systems
Dec 09, 2024


Emerging digital twin technology has the potential to revolutionize voltage control in power systems. However, the state-of-the-art digital twin method suffers from low computational and sampling efficiency, which hinders its applications. To address this issue, we propose a Gumbel-Consistency Digital Twin (GC-DT) method that enhances voltage control with improved computational and sampling efficiency. First, the proposed method incorporates a Gumbel-based strategy improvement that leverages the Gumbel-top trick to enhance non-repetitive sampling actions and reduce the reliance on Monte Carlo Tree Search simulations, thereby improving computational efficiency. Second, a consistency loss function aligns predicted hidden states with actual hidden states in the latent space, which increases both prediction accuracy and sampling efficiency. Experiments on IEEE 123-bus, 34-bus, and 13-bus systems demonstrate that the proposed GC-DT outperforms the state-of-the-art DT method in both computational and sampling efficiency.
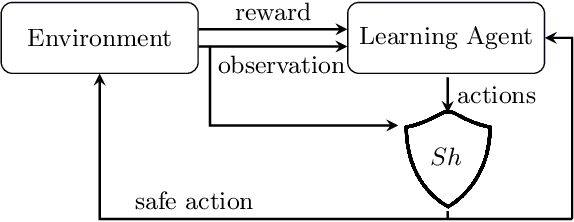
Compositional Shielding and Reinforcement Learning for Multi-Agent Systems
Oct 14, 2024
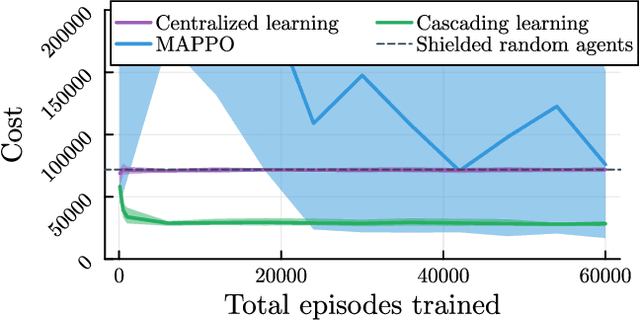
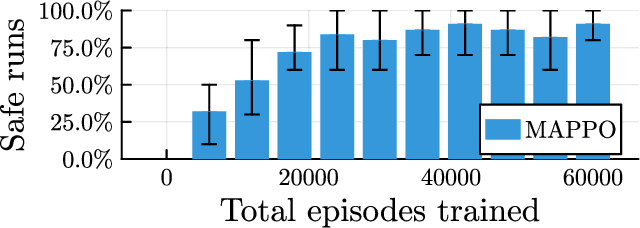
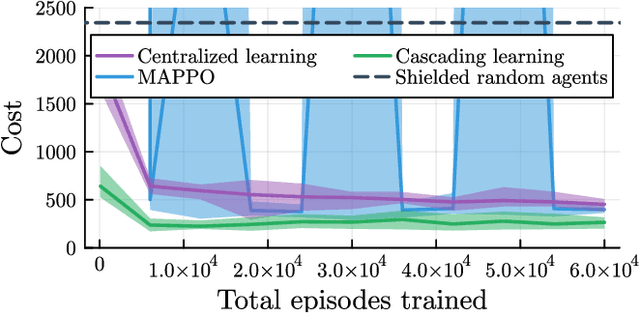
Deep reinforcement learning has emerged as a powerful tool for obtaining high-performance policies. However, the safety of these policies has been a long-standing issue. One promising paradigm to guarantee safety is a shield, which shields a policy from making unsafe actions. However, computing a shield scales exponentially in the number of state variables. This is a particular concern in multi-agent systems with many agents. In this work, we propose a novel approach for multi-agent shielding. We address scalability by computing individual shields for each agent. The challenge is that typical safety specifications are global properties, but the shields of individual agents only ensure local properties. Our key to overcome this challenge is to apply assume-guarantee reasoning. Specifically, we present a sound proof rule that decomposes a (global, complex) safety specification into (local, simple) obligations for the shields of the individual agents. Moreover, we show that applying the shields during reinforcement learning significantly improves the quality of the policies obtained for a given training budget. We demonstrate the effectiveness and scalability of our multi-agent shielding framework in two case studies, reducing the computation time from hours to seconds and achieving fast learning convergence.
CommonUppRoad: A Framework of Formal Modelling, Verifying, Learning, and Visualisation of Autonomous Vehicles
Aug 02, 2024



Combining machine learning and formal methods (FMs) provides a possible solution to overcome the safety issue of autonomous driving (AD) vehicles. However, there are gaps to be bridged before this combination becomes practically applicable and useful. In an attempt to facilitate researchers in both FMs and AD areas, this paper proposes a framework that combines two well-known tools, namely CommonRoad and UPPAAL. On the one hand, CommonRoad can be enhanced by the rigorous semantics of models in UPPAAL, which enables a systematic and comprehensive understanding of the AD system's behaviour and thus strengthens the safety of the system. On the other hand, controllers synthesised by UPPAAL can be visualised by CommonRoad in real-world road networks, which facilitates AD vehicle designers greatly adopting formal models in system design. In this framework, we provide automatic model conversions between CommonRoad and UPPAAL. Therefore, users only need to program in Python and the framework takes care of the formal models, learning, and verification in the backend. We perform experiments to demonstrate the applicability of our framework in various AD scenarios, discuss the advantages of solving motion planning in our framework, and show the scalability limit and possible solutions.
Efficient Shield Synthesis via State-Space Transformation
Jul 29, 2024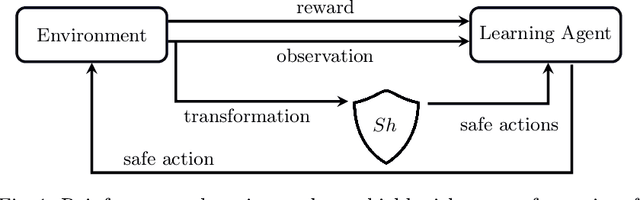
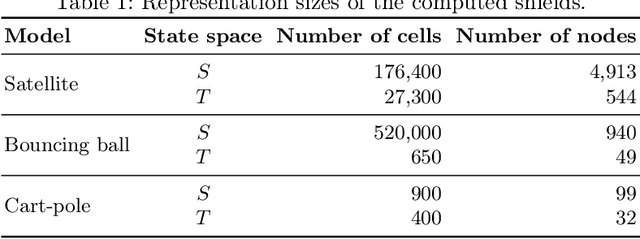
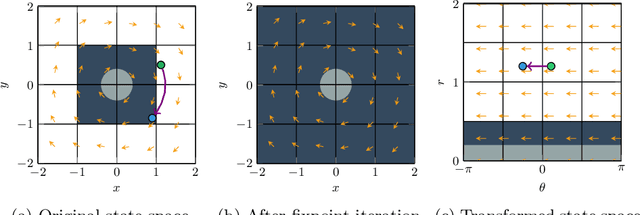

We consider the problem of synthesizing safety strategies for control systems, also known as shields. Since the state space is infinite, shields are typically computed over a finite-state abstraction, with the most common abstraction being a rectangular grid. However, for many systems, such a grid does not align well with the safety property or the system dynamics. That is why a coarse grid is rarely sufficient, but a fine grid is typically computationally infeasible to obtain. In this paper, we show that appropriate state-space transformations can still allow to use a coarse grid at almost no computational overhead. We demonstrate in three case studies that our transformation-based synthesis outperforms a standard synthesis by several orders of magnitude. In the first two case studies, we use domain knowledge to select a suitable transformation. In the third case study, we instead report on results in engineering a transformation without domain knowledge.
Shielded Reinforcement Learning for Hybrid Systems
Aug 28, 2023Safe and optimal controller synthesis for switched-controlled hybrid systems, which combine differential equations and discrete changes of the system's state, is known to be intricately hard. Reinforcement learning has been leveraged to construct near-optimal controllers, but their behavior is not guaranteed to be safe, even when it is encouraged by reward engineering. One way of imposing safety to a learned controller is to use a shield, which is correct by design. However, obtaining a shield for non-linear and hybrid environments is itself intractable. In this paper, we propose the construction of a shield using the so-called barbaric method, where an approximate finite representation of an underlying partition-based two-player safety game is extracted via systematically picked samples of the true transition function. While hard safety guarantees are out of reach, we experimentally demonstrate strong statistical safety guarantees with a prototype implementation and UPPAAL STRATEGO. Furthermore, we study the impact of the synthesized shield when applied as either a pre-shield (applied before learning a controller) or a post-shield (only applied after learning a controller). We experimentally demonstrate superiority of the pre-shielding approach. We apply our technique on a range of case studies, including two industrial examples, and further study post-optimization of the post-shielding approach.
It's Time to Play Safe: Shield Synthesis for Timed Systems
Jun 30, 2020
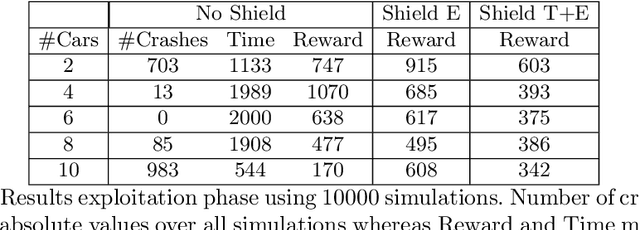
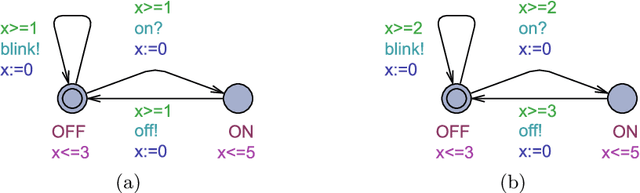
Erroneous behaviour in safety critical real-time systems may inflict serious consequences. In this paper, we show how to synthesize timed shields from timed safety properties given as timed automata. A timed shield enforces the safety of a running system while interfering with the system as little as possible. We present timed post-shields and timed pre-shields. A timed pre-shield is placed before the system and provides a set of safe outputs. This set restricts the choices of the system. A timed post-shield is implemented after the system. It monitors the system and corrects the system's output only if necessary. We further extend the timed post-shield construction to provide a guarantee on the recovery phase, i.e., the time between a specification violation and the point at which full control can be handed back to the system. In our experimental results, we use timed post-shields to ensure the safety in a reinforcement learning setting for controlling a platoon of cars, during the learning and execution phase, and study the effect.
Approximating Euclidean by Imprecise Markov Decision Processes
Jun 26, 2020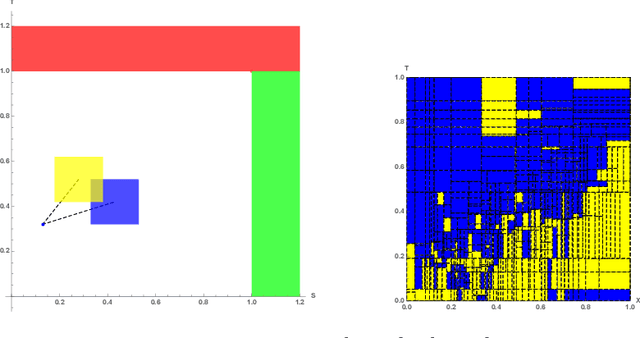
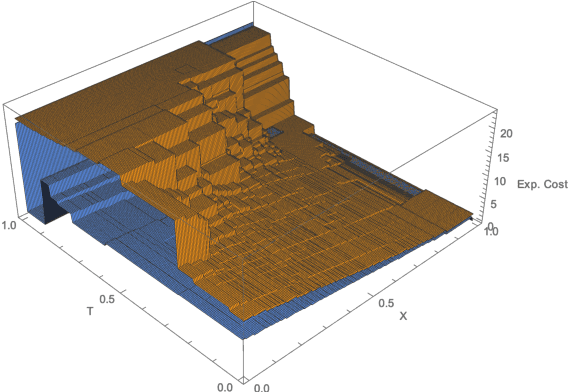
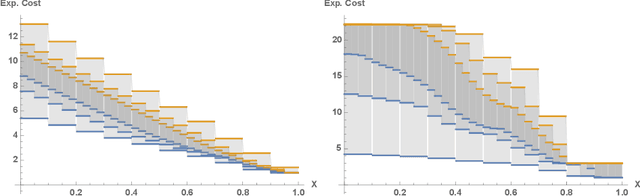
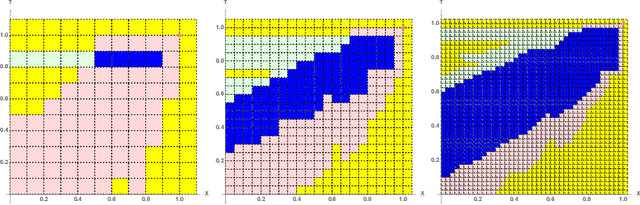
Euclidean Markov decision processes are a powerful tool for modeling control problems under uncertainty over continuous domains. Finite state imprecise, Markov decision processes can be used to approximate the behavior of these infinite models. In this paper we address two questions: first, we investigate what kind of approximation guarantees are obtained when the Euclidean process is approximated by finite state approximations induced by increasingly fine partitions of the continuous state space. We show that for cost functions over finite time horizons the approximations become arbitrarily precise. Second, we use imprecise Markov decision process approximations as a tool to analyse and validate cost functions and strategies obtained by reinforcement learning. We find that, on the one hand, our new theoretical results validate basic design choices of a previously proposed reinforcement learning approach. On the other hand, the imprecise Markov decision process approximations reveal some inaccuracies in the learned cost functions.