 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
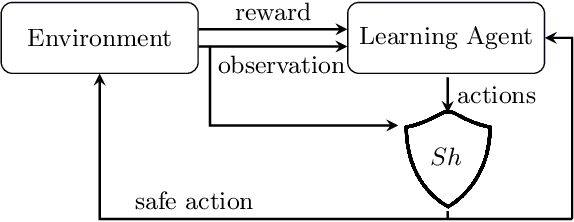
Add to EdgeSafety Shielding under Delayed Observation
Jul 05, 2023Agents operating in physical environments need to be able to handle delays in the input and output signals since neither data transmission nor sensing or actuating the environment are instantaneous. Shields are correct-by-construction runtime enforcers that guarantee safe execution by correcting any action that may cause a violation of a formal safety specification. Besides providing safety guarantees, shields should interfere minimally with the agent. Therefore, shields should pick the safe corrective actions in such a way that future interferences are most likely minimized. Current shielding approaches do not consider possible delays in the input signals in their safety analyses. In this paper, we address this issue. We propose synthesis algorithms to compute \emph{delay-resilient shields} that guarantee safety under worst-case assumptions on the delays of the input signals. We also introduce novel heuristics for deciding between multiple corrective actions, designed to minimize future shield interferences caused by delays. As a further contribution, we present the first integration of shields in a realistic driving simulator. We implemented our delayed shields in the driving simulator \textsc{Carla}. We shield potentially unsafe autonomous driving agents in different safety-critical scenarios and show the effect of delays on the safety analysis.
Automata Learning meets Shielding
Dec 04, 2022Safety is still one of the major research challenges in reinforcement learning (RL). In this paper, we address the problem of how to avoid safety violations of RL agents during exploration in probabilistic and partially unknown environments. Our approach combines automata learning for Markov Decision Processes (MDPs) and shield synthesis in an iterative approach. Initially, the MDP representing the environment is unknown. The agent starts exploring the environment and collects traces. From the collected traces, we passively learn MDPs that abstractly represent the safety-relevant aspects of the environment. Given a learned MDP and a safety specification, we construct a shield. For each state-action pair within a learned MDP, the shield computes exact probabilities on how likely it is that executing the action results in violating the specification from the current state within the next $k$ steps. After the shield is constructed, the shield is used during runtime and blocks any actions that induce a too large risk from the agent. The shielded agent continues to explore the environment and collects new data on the environment. Iteratively, we use the collected data to learn new MDPs with higher accuracy, resulting in turn in shields able to prevent more safety violations. We implemented our approach and present a detailed case study of a Q-learning agent exploring slippery Gridworlds. In our experiments, we show that as the agent explores more and more of the environment during training, the improved learned models lead to shields that are able to prevent many safety violations.
Online Shielding for Reinforcement Learning
Dec 04, 2022Besides the recent impressive results on reinforcement learning (RL), safety is still one of the major research challenges in RL. RL is a machine-learning approach to determine near-optimal policies in Markov decision processes (MDPs). In this paper, we consider the setting where the safety-relevant fragment of the MDP together with a temporal logic safety specification is given and many safety violations can be avoided by planning ahead a short time into the future. We propose an approach for online safety shielding of RL agents. During runtime, the shield analyses the safety of each available action. For any action, the shield computes the maximal probability to not violate the safety specification within the next $k$ steps when executing this action. Based on this probability and a given threshold, the shield decides whether to block an action from the agent. Existing offline shielding approaches compute exhaustively the safety of all state-action combinations ahead of time, resulting in huge computation times and large memory consumption. The intuition behind online shielding is to compute at runtime the set of all states that could be reached in the near future. For each of these states, the safety of all available actions is analysed and used for shielding as soon as one of the considered states is reached. Our approach is well suited for high-level planning problems where the time between decisions can be used for safety computations and it is sustainable for the agent to wait until these computations are finished. For our evaluation, we selected a 2-player version of the classical computer game SNAKE. The game represents a high-level planning problem that requires fast decisions and the multiplayer setting induces a large state space, which is computationally expensive to analyse exhaustively.
Correct-by-Construction Runtime Enforcement in AI -- A Survey
Aug 30, 2022Runtime enforcement refers to the theories, techniques, and tools for enforcing correct behavior with respect to a formal specification of systems at runtime. In this paper, we are interested in techniques for constructing runtime enforcers for the concrete application domain of enforcing safety in AI. We discuss how safety is traditionally handled in the field of AI and how more formal guarantees on the safety of a self-learning agent can be given by integrating a runtime enforcer. We survey a selection of work on such enforcers, where we distinguish between approaches for discrete and continuous action spaces. The purpose of this paper is to foster a better understanding of advantages and limitations of different enforcement techniques, focusing on the specific challenges that arise due to their application in AI. Finally, we present some open challenges and avenues for future work.
Safety Synthesis Sans Specification
Nov 27, 2020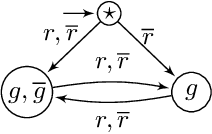
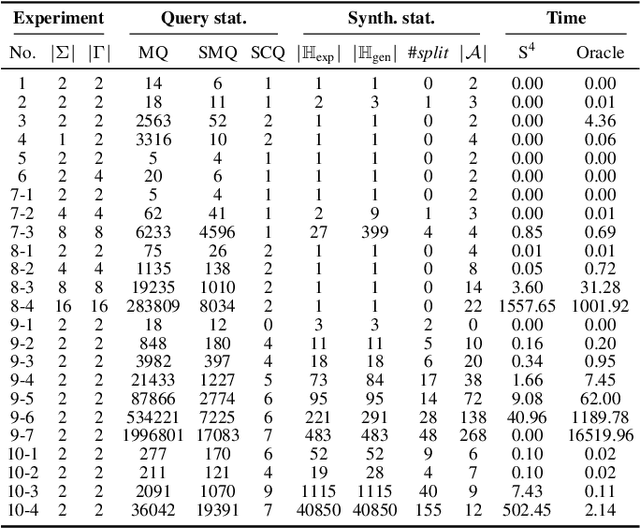
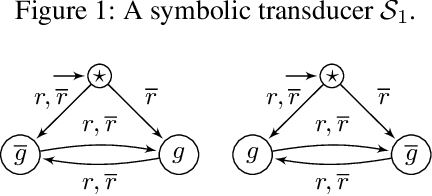
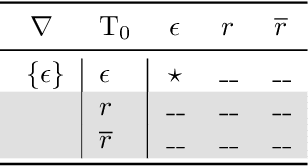
We define the problem of learning a transducer ${S}$ from a target language $U$ containing possibly conflicting transducers, using membership queries and conjecture queries. The requirement is that the language of ${S}$ be a subset of $U$. We argue that this is a natural question in many situations in hardware and software verification. We devise a learning algorithm for this problem and show that its time and query complexity is polynomial with respect to the rank of the target language, its incompatibility measure, and the maximal length of a given counterexample. We report on experiments conducted with a prototype implementation.
It's Time to Play Safe: Shield Synthesis for Timed Systems
Jun 30, 2020
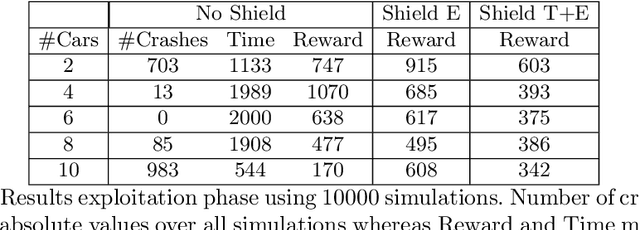
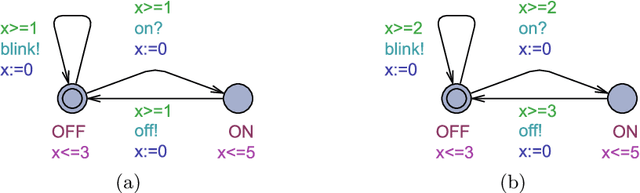
Erroneous behaviour in safety critical real-time systems may inflict serious consequences. In this paper, we show how to synthesize timed shields from timed safety properties given as timed automata. A timed shield enforces the safety of a running system while interfering with the system as little as possible. We present timed post-shields and timed pre-shields. A timed pre-shield is placed before the system and provides a set of safe outputs. This set restricts the choices of the system. A timed post-shield is implemented after the system. It monitors the system and corrects the system's output only if necessary. We further extend the timed post-shield construction to provide a guarantee on the recovery phase, i.e., the time between a specification violation and the point at which full control can be handed back to the system. In our experimental results, we use timed post-shields to ensure the safety in a reinforcement learning setting for controlling a platoon of cars, during the learning and execution phase, and study the effect.
Learning a Behavior Model of Hybrid Systems Through Combining Model-Based Testing and Machine Learning
Jul 10, 2019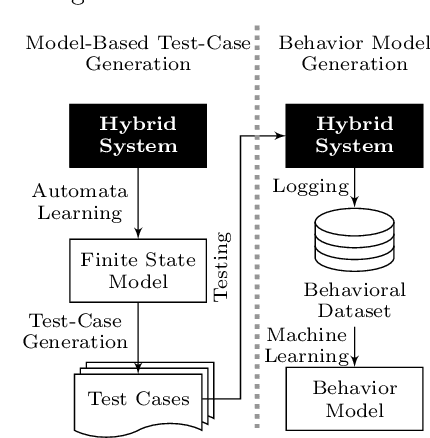
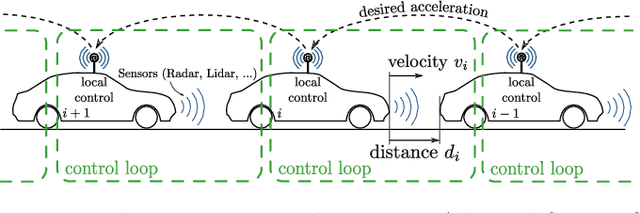
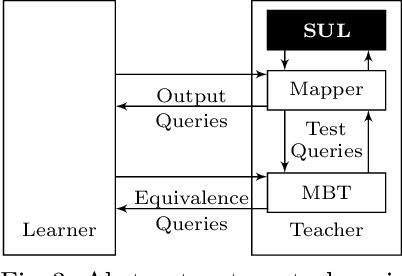
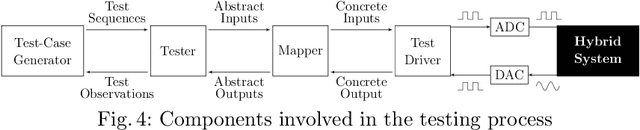
Models play an essential role in the design process of cyber-physical systems. They form the basis for simulation and analysis and help in identifying design problems as early as possible. However, the construction of models that comprise physical and digital behavior is challenging. Therefore, there is considerable interest in learning such hybrid behavior by means of machine learning which requires sufficient and representative training data covering the behavior of the physical system adequately. In this work, we exploit a combination of automata learning and model-based testing to generate sufficient training data fully automatically. Experimental results on a platooning scenario show that recurrent neural networks learned with this data achieved significantly better results compared to models learned from randomly generated data. In particular, the classification error for crash detection is reduced by a factor of five and a similar F1-score is obtained with up to three orders of magnitude fewer training samples.
QBF Solving by Counterexample-guided Expansion
Jul 27, 2018
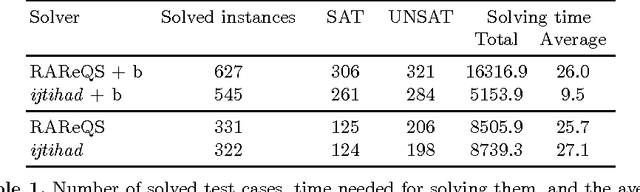
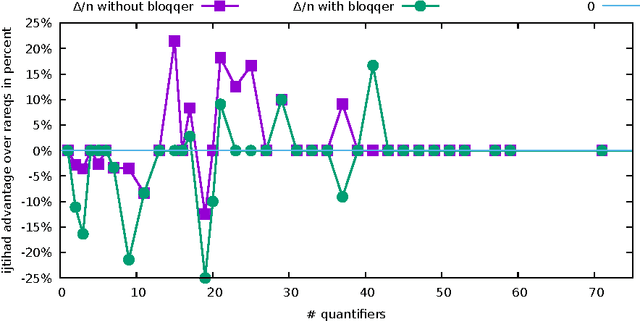

We introduce a novel generalization of Counterexample-Guided Inductive Synthesis (CEGIS) and instantiate it to yield a novel, competitive algorithm for solving Quantified Boolean Formulas (QBF). Current QBF solvers based on counterexample-guided expansion use a recursive approach which scales poorly with the number of quantifier alternations. Our generalization of CEGIS removes the need for this recursive approach, and we instantiate it to yield a simple and efficient algorithm for QBF solving. Lastly, this research is supported by a competitive, though straightforward, implementation of the algorithm, making it possible to study the practical impact of our algorithm design decisions, along with various optimizations.
Shielded Decision-Making in MDPs
Jul 16, 2018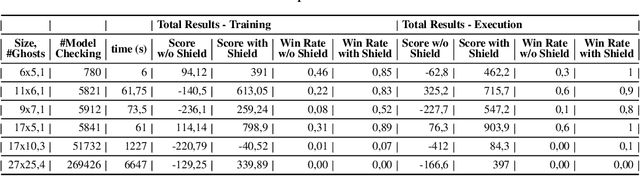
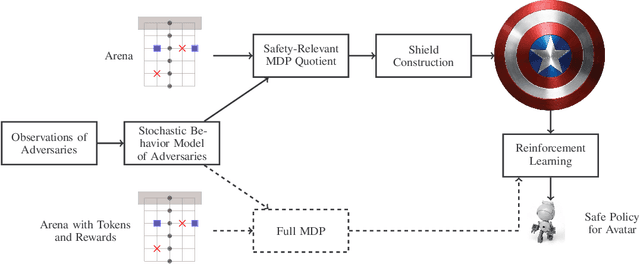
A prominent problem in artificial intelligence and machine learning is the safe exploration of an environment. In particular, reinforcement learning is a well-known technique to determine optimal policies for complicated dynamic systems, but suffers from the fact that such policies may induce harmful behavior. We present the concept of a shield that forces decision-making to provably adhere to safety requirements with high probability. Our method exploits the inherent uncertainties in scenarios given by Markov decision processes. We present a method to compute probabilities of decision making regarding temporal logic constraints. We use that information to realize a shield that---when applied to a reinforcement learning algorithm---ensures (near-)optimal behavior both for the safety constraints and for the actual learning objective. In our experiments, we show on the arcade game PAC-MAN that the learning efficiency increases as the learning needs orders of magnitude fewer episodes. We show tradeoffs between sufficient progress in exploration of the environment and ensuring strict safety.
Safe Reinforcement Learning via Shielding
Sep 03, 2017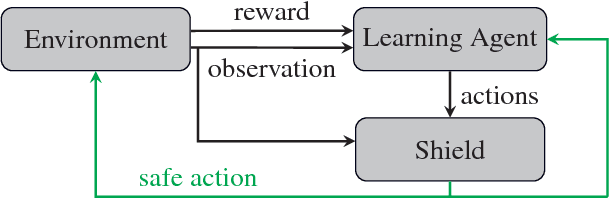
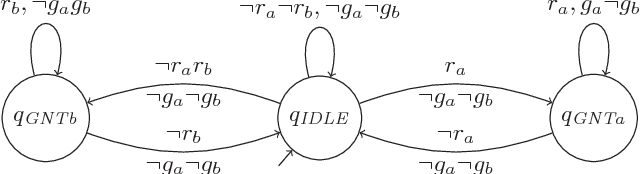
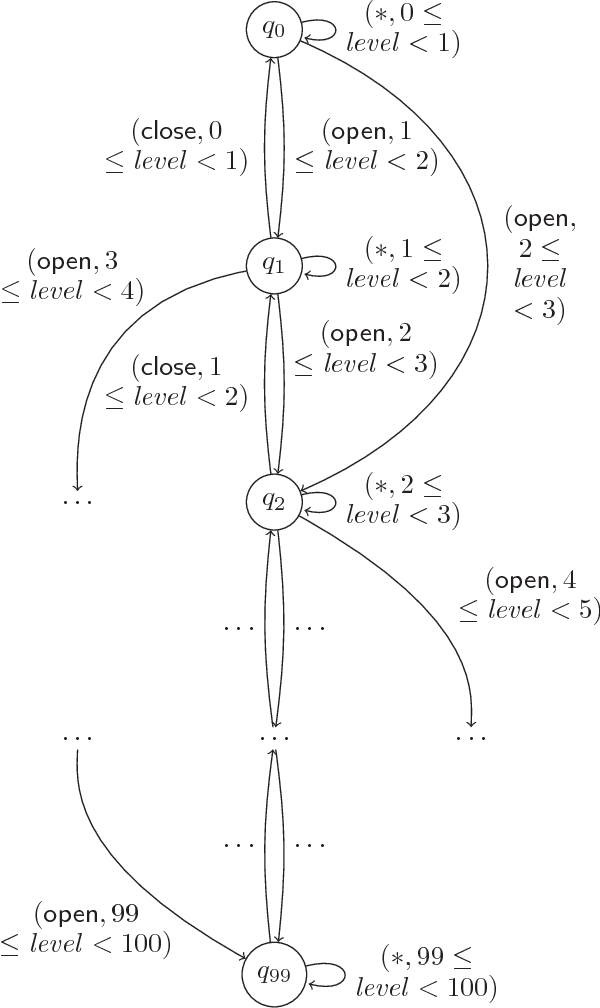
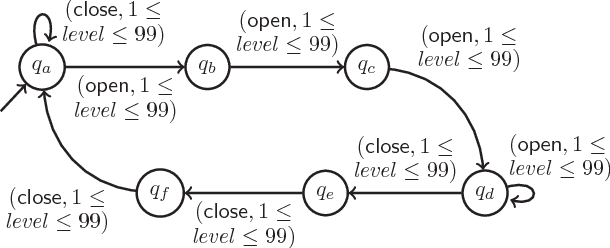
Reinforcement learning algorithms discover policies that maximize reward, but do not necessarily guarantee safety during learning or execution phases. We introduce a new approach to learn optimal policies while enforcing properties expressed in temporal logic. To this end, given the temporal logic specification that is to be obeyed by the learning system, we propose to synthesize a reactive system called a shield. The shield is introduced in the traditional learning process in two alternative ways, depending on the location at which the shield is implemented. In the first one, the shield acts each time the learning agent is about to make a decision and provides a list of safe actions. In the second way, the shield is introduced after the learning agent. The shield monitors the actions from the learner and corrects them only if the chosen action causes a violation of the specification. We discuss which requirements a shield must meet to preserve the convergence guarantees of the learner. Finally, we demonstrate the versatility of our approach on several challenging reinforcement learning scenarios.