 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Shielding under Delayed Observation
Jul 05, 2023Agents operating in physical environments need to be able to handle delays in the input and output signals since neither data transmission nor sensing or actuating the environment are instantaneous. Shields are correct-by-construction runtime enforcers that guarantee safe execution by correcting any action that may cause a violation of a formal safety specification. Besides providing safety guarantees, shields should interfere minimally with the agent. Therefore, shields should pick the safe corrective actions in such a way that future interferences are most likely minimized. Current shielding approaches do not consider possible delays in the input signals in their safety analyses. In this paper, we address this issue. We propose synthesis algorithms to compute \emph{delay-resilient shields} that guarantee safety under worst-case assumptions on the delays of the input signals. We also introduce novel heuristics for deciding between multiple corrective actions, designed to minimize future shield interferences caused by delays. As a further contribution, we present the first integration of shields in a realistic driving simulator. We implemented our delayed shields in the driving simulator \textsc{Carla}. We shield potentially unsafe autonomous driving agents in different safety-critical scenarios and show the effect of delays on the safety analysis.
Analyzing Intentional Behavior in Autonomous Agents under Uncertainty
Jul 04, 2023Principled accountability for autonomous decision-making in uncertain environments requires distinguishing intentional outcomes from negligent designs from actual accidents. We propose analyzing the behavior of autonomous agents through a quantitative measure of the evidence of intentional behavior. We model an uncertain environment as a Markov Decision Process (MDP). For a given scenario, we rely on probabilistic model checking to compute the ability of the agent to influence reaching a certain event. We call this the scope of agency. We say that there is evidence of intentional behavior if the scope of agency is high and the decisions of the agent are close to being optimal for reaching the event. Our method applies counterfactual reasoning to automatically generate relevant scenarios that can be analyzed to increase the confidence of our assessment. In a case study, we show how our method can distinguish between 'intentional' and 'accidental' traffic collisions.
Search-Based Testing of Reinforcement Learning
May 14, 2022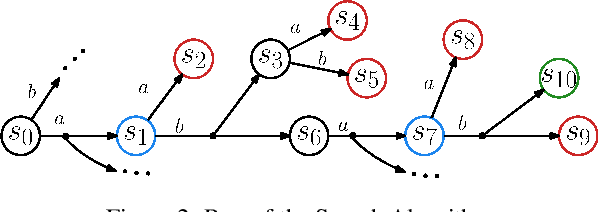
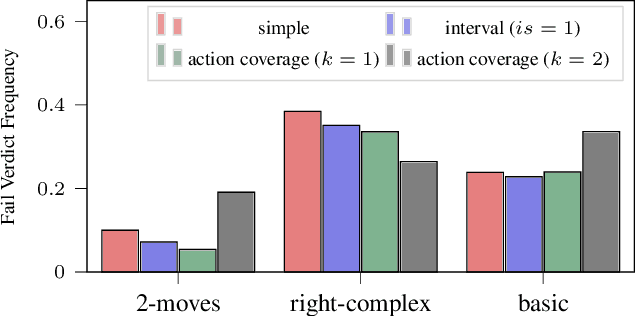
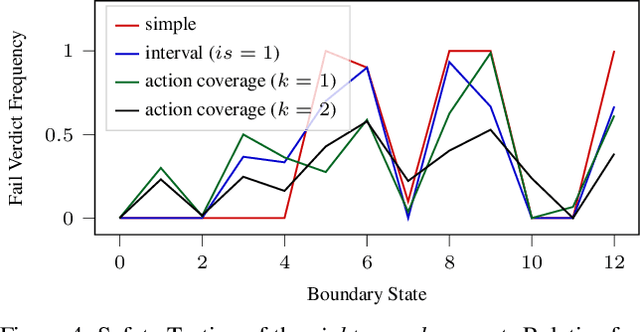
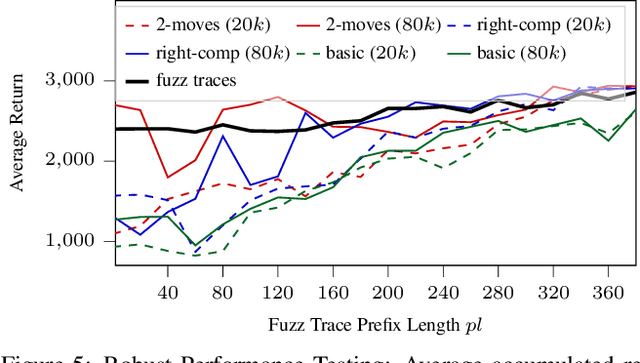
Evaluation of deep reinforcement learning (RL) is inherently challenging. Especially the opaqueness of learned policies and the stochastic nature of both agents and environments make testing the behavior of deep RL agents difficult. We present a search-based testing framework that enables a wide range of novel analysis capabilities for evaluating the safety and performance of deep RL agents. For safety testing, our framework utilizes a search algorithm that searches for a reference trace that solves the RL task. The backtracking states of the search, called boundary states, pose safety-critical situations. We create safety test-suites that evaluate how well the RL agent escapes safety-critical situations near these boundary states. For robust performance testing, we create a diverse set of traces via fuzz testing. These fuzz traces are used to bring the agent into a wide variety of potentially unknown states from which the average performance of the agent is compared to the average performance of the fuzz traces. We apply our search-based testing approach on RL for Nintendo's Super Mario Bros.