 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship Between RNN Hidden State Vectors and Semantic Ground Truth
Jun 29, 2023



We examine the assumption that the hidden-state vectors of recurrent neural networks (RNNs) tend to form clusters of semantically similar vectors, which we dub the clustering hypothesis. While this hypothesis has been assumed in the analysis of RNNs in recent years, its validity has not been studied thoroughly on modern neural network architectures. We examine the clustering hypothesis in the context of RNNs that were trained to recognize regular languages. This enables us to draw on perfect ground-truth automata in our evaluation, against which we can compare the RNN's accuracy and the distribution of the hidden-state vectors. We start with examining the (piecewise linear) separability of an RNN's hidden-state vectors into semantically different classes. We continue the analysis by computing clusters over the hidden-state vector space with multiple state-of-the-art unsupervised clustering approaches. We formally analyze the accuracy of computed clustering functions and the validity of the clustering hypothesis by determining whether clusters group semantically similar vectors to the same state in the ground-truth model. Our evaluation supports the validity of the clustering hypothesis in the majority of examined cases. We observed that the hidden-state vectors of well-trained RNNs are separable, and that the unsupervised clustering techniques succeed in finding clusters of similar state vectors.
Learning Environment Models with Continuous Stochastic Dynamics
Jun 29, 2023



Solving control tasks in complex environments automatically through learning offers great potential. While contemporary techniques from deep reinforcement learning (DRL) provide effective solutions, their decision-making is not transparent. We aim to provide insights into the decisions faced by the agent by learning an automaton model of environmental behavior under the control of an agent. However, for most control problems, automata learning is not scalable enough to learn a useful model. In this work, we raise the capabilities of automata learning such that it is possible to learn models for environments that have complex and continuous dynamics. The core of the scalability of our method lies in the computation of an abstract state-space representation, by applying dimensionality reduction and clustering on the observed environmental state space. The stochastic transitions are learned via passive automata learning from observed interactions of the agent and the environment. In an iterative model-based RL process, we sample additional trajectories to learn an accurate environment model in the form of a discrete-state Markov decision process (MDP). We apply our automata learning framework on popular RL benchmarking environments in the OpenAI Gym, including LunarLander, CartPole, Mountain Car, and Acrobot. Our results show that the learned models are so precise that they enable the computation of policies solving the respective control tasks. Yet the models are more concise and more general than neural-network-based policies and by using MDPs we benefit from a wealth of tools available for analyzing them. When solving the task of LunarLander, the learned model even achieved similar or higher rewards than deep RL policies learned with stable-baselines3.
Reinforcement Learning under Partial Observability Guided by Learned Environment Models
Jun 23, 2022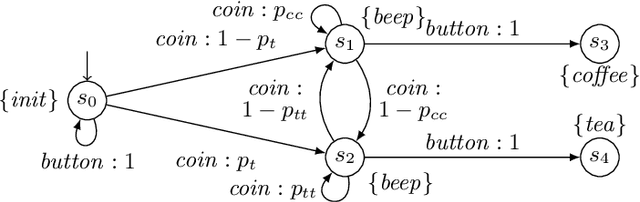
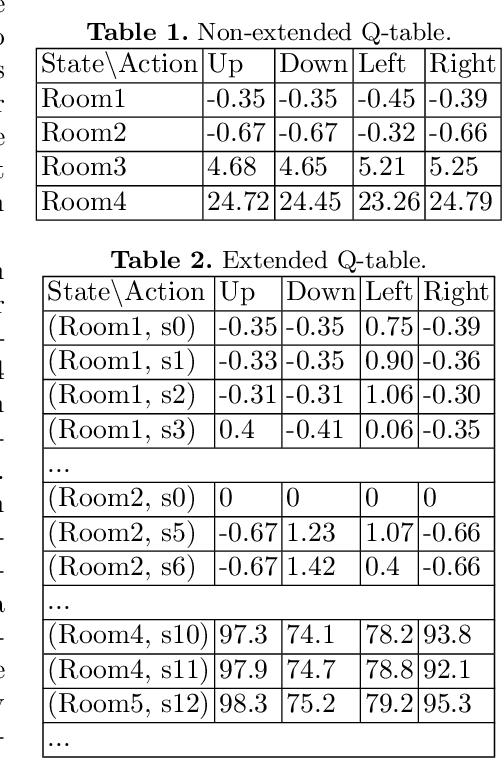
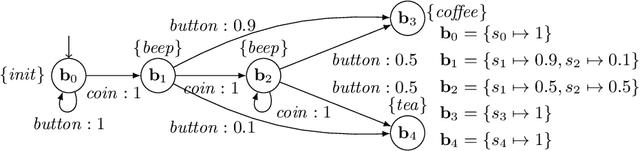
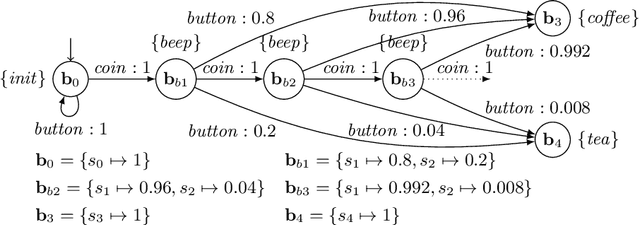
In practical applications, we can rarely assume full observability of a system's environment, despite such knowledge being important for determining a reactive control system's precise interaction with its environment. Therefore, we propose an approach for reinforcement learning (RL) in partially observable environments. While assuming that the environment behaves like a partially observable Markov decision process with known discrete actions, we assume no knowledge about its structure or transition probabilities. Our approach combines Q-learning with IoAlergia, a method for learning Markov decision processes (MDP). By learning MDP models of the environment from episodes of the RL agent, we enable RL in partially observable domains without explicit, additional memory to track previous interactions for dealing with ambiguities stemming from partial observability. We instead provide RL with additional observations in the form of abstract environment states by simulating new experiences on learned environment models to track the explored states. In our evaluation, we report on the validity of our approach and its promising performance in comparison to six state-of-the-art deep RL techniques with recurrent neural networks and fixed memory.
Search-Based Testing of Reinforcement Learning
May 14, 2022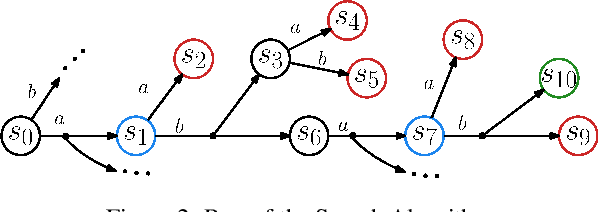
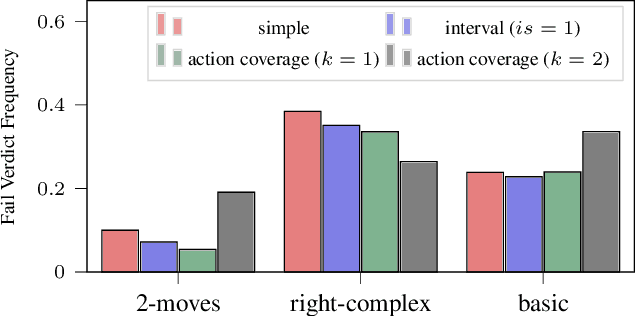
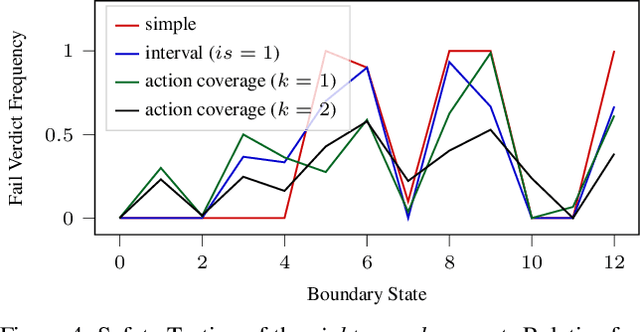
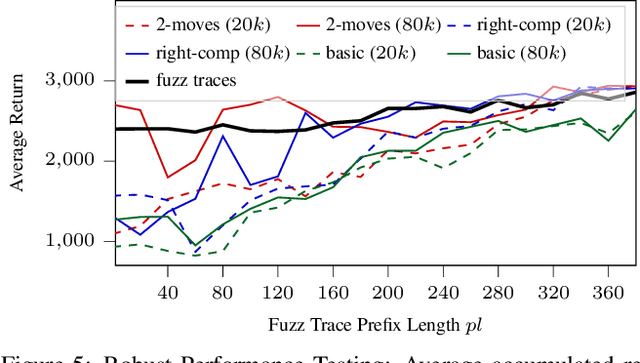
Evaluation of deep reinforcement learning (RL) is inherently challenging. Especially the opaqueness of learned policies and the stochastic nature of both agents and environments make testing the behavior of deep RL agents difficult. We present a search-based testing framework that enables a wide range of novel analysis capabilities for evaluating the safety and performance of deep RL agents. For safety testing, our framework utilizes a search algorithm that searches for a reference trace that solves the RL task. The backtracking states of the search, called boundary states, pose safety-critical situations. We create safety test-suites that evaluate how well the RL agent escapes safety-critical situations near these boundary states. For robust performance testing, we create a diverse set of traces via fuzz testing. These fuzz traces are used to bring the agent into a wide variety of potentially unknown states from which the average performance of the agent is compared to the average performance of the fuzz traces. We apply our search-based testing approach on RL for Nintendo's Super Mario Bros.
Learning a Behavior Model of Hybrid Systems Through Combining Model-Based Testing and Machine Learning
Jul 10, 2019
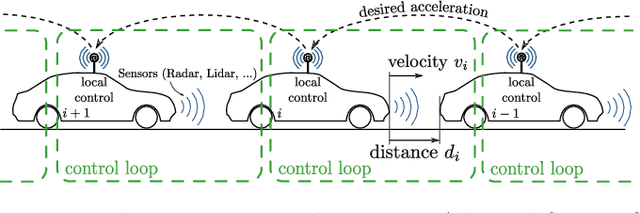
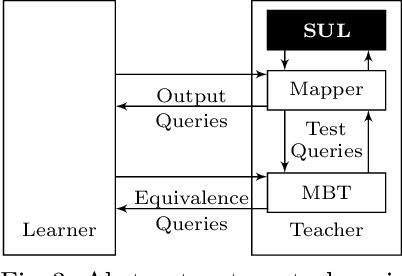
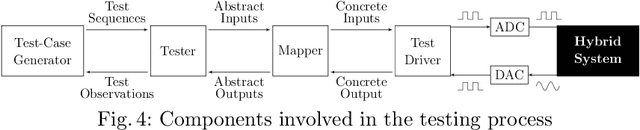
Models play an essential role in the design process of cyber-physical systems. They form the basis for simulation and analysis and help in identifying design problems as early as possible. However, the construction of models that comprise physical and digital behavior is challenging. Therefore, there is considerable interest in learning such hybrid behavior by means of machine learning which requires sufficient and representative training data covering the behavior of the physical system adequately. In this work, we exploit a combination of automata learning and model-based testing to generate sufficient training data fully automatically. Experimental results on a platooning scenario show that recurrent neural networks learned with this data achieved significantly better results compared to models learned from randomly generated data. In particular, the classification error for crash detection is reduced by a factor of five and a similar F1-score is obtained with up to three orders of magnitude fewer training samples.
L*-Based Learning of Markov Decision Processes
Jun 28, 2019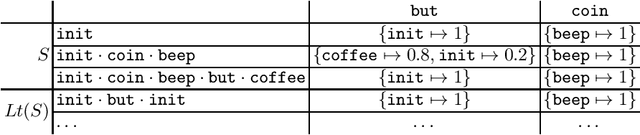
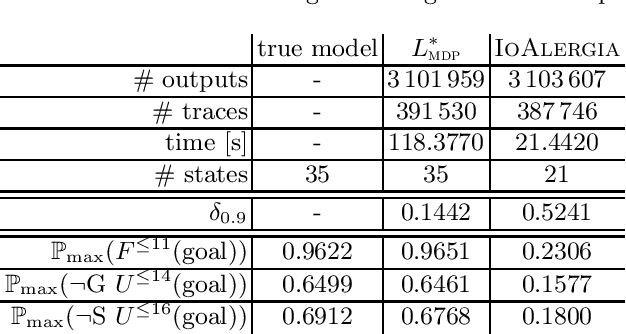
Automata learning techniques automatically generate system models from test observations. These techniques usually fall into two categories: passive and active. Passive learning uses a predetermined data set, e.g., system logs. In contrast, active learning actively queries the system under learning, which is considered more efficient. An influential active learning technique is Angluin's L* algorithm for regular languages which inspired several generalisations from DFAs to other automata-based modelling formalisms. In this work, we study L*-based learning of deterministic Markov decision processes, first assuming an ideal setting with perfect information. Then, we relax this assumption and present a novel learning algorithm that collects information by sampling system traces via testing. Experiments with the implementation of our sampling-based algorithm suggest that it achieves better accuracy than state-of-the-art passive learning techniques with the same amount of test data. Unlike existing learning algorithms with predefined states, our algorithm learns the complete model structure including the states.