 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-efficient Deep Neural Networks for Automotive Radar Interference Mitigation
Jan 25, 2022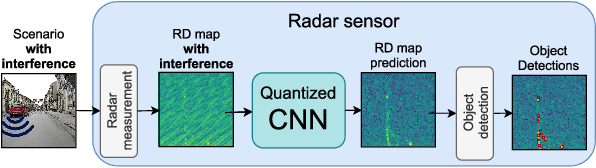
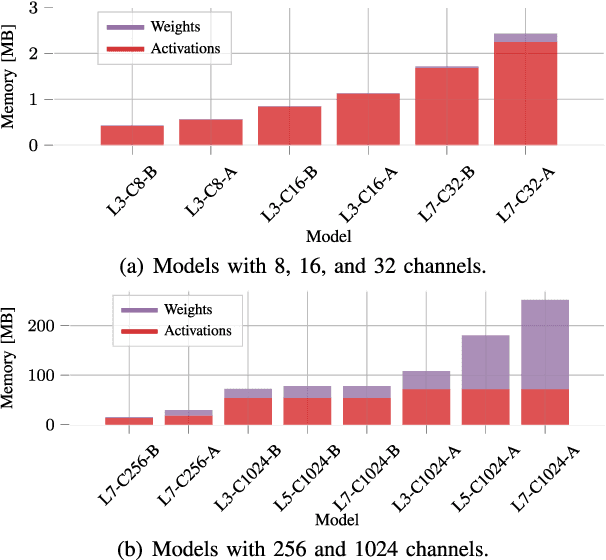
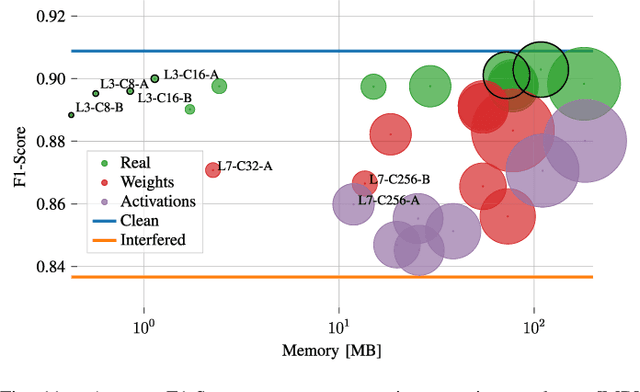
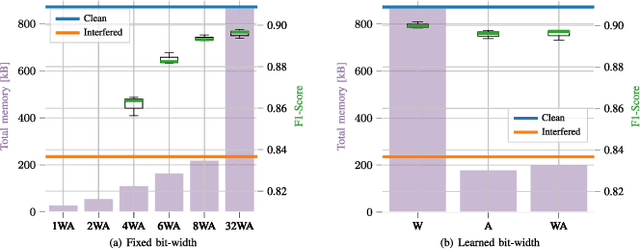
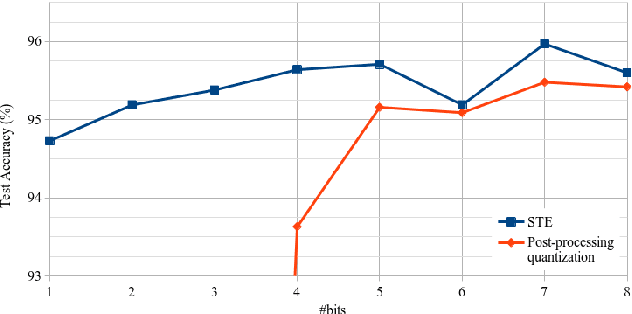
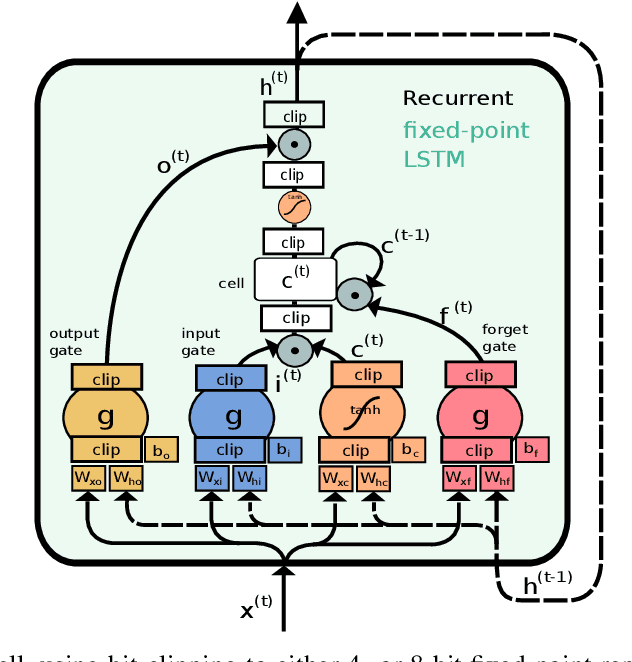
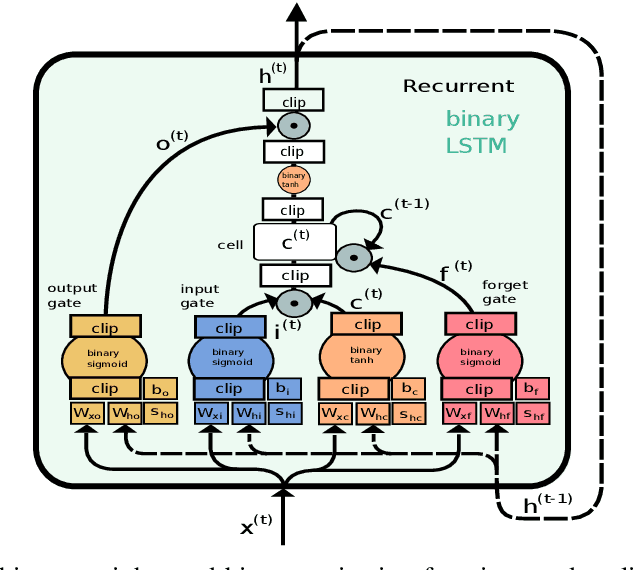
Radar sensors are crucial for environment perception of driver assistance systems as well as autonomous vehicles. With a rising number of radar sensors and the so far unregulated automotive radar frequency band, mutual interference is inevitable and must be dealt with. Algorithms and models operating on radar data are required to run the early processing steps on specialized radar sensor hardware. This specialized hardware typically has strict resource-constraints, i.e. a low memory capacity and low computational power. Convolutional Neural Network (CNN)-based approaches for denoising and interference mitigation yield promising results for radar processing in terms of performance. Regarding resource-constraints, however, CNNs typically exceed the hardware's capacities by far. In this paper we investigate quantization techniques for CNN-based denoising and interference mitigation of radar signals. We analyze the quantization of (i) weights and (ii) activations of different CNN-based model architectures. This quantization results in reduced memory requirements for model storage and during inference. We compare models with fixed and learned bit-widths and contrast two different methodologies for training quantized CNNs, i.e. the straight-through gradient estimator and training distributions over discrete weights. We illustrate the importance of structurally small real-valued base models for quantization and show that learned bit-widths yield the smallest models. We achieve a memory reduction of around 80\% compared to the real-valued baseline. Due to practical reasons, however, we recommend the use of 8 bits for weights and activations, which results in models that require only 0.2 megabytes of memory.
* 15 pages; published in IEEE Journal of Selected Topics in Signal Processing, Special Issue on Recent Advances in Automotive Radar Signal Processing, Volume: 15, Issue: 4, June 2021. arXiv admin note: text overlap with arXiv:2011.12706
End-to-end Keyword Spotting using Neural Architecture Search and Quantization
Apr 14, 2021
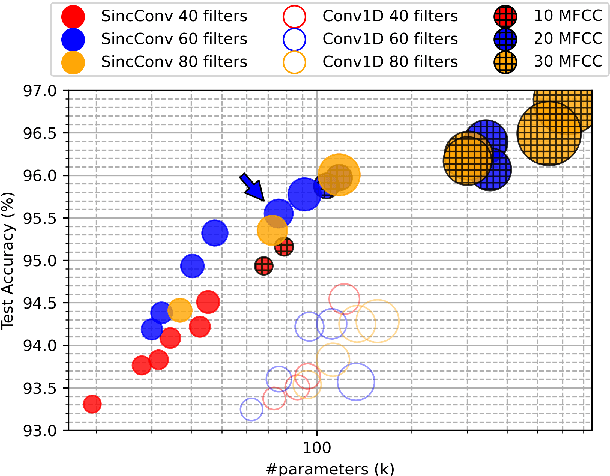
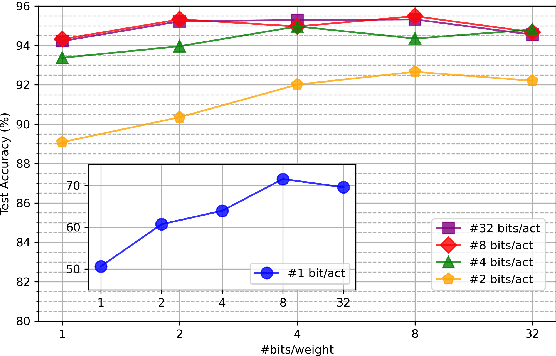
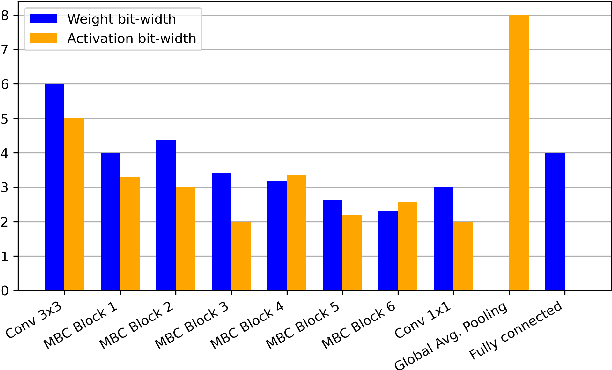
This paper introduces neural architecture search (NAS) for the automatic discovery of end-to-end keyword spotting (KWS) models in limited resource environments. We employ a differentiable NAS approach to optimize the structure of convolutional neural networks (CNNs) operating on raw audio waveforms. After a suitable KWS model is found with NAS, we conduct quantization of weights and activations to reduce the memory footprint. We conduct extensive experiments on the Google speech commands dataset. In particular, we compare our end-to-end approach to mel-frequency cepstral coefficient (MFCC) based systems. For quantization, we compare fixed bit-width quantization and trained bit-width quantization. Using NAS only, we were able to obtain a highly efficient model with an accuracy of 95.55% using 75.7k parameters and 13.6M operations. Using trained bit-width quantization, the same model achieves a test accuracy of 93.76% while using on average only 2.91 bits per activation and 2.51 bits per weight.
Resource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
Dec 18, 2020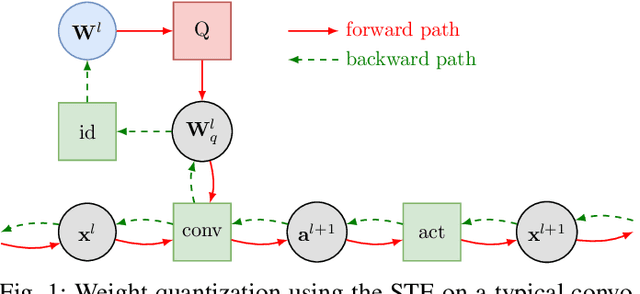
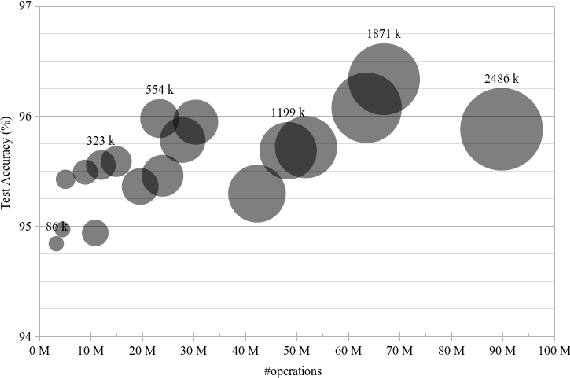
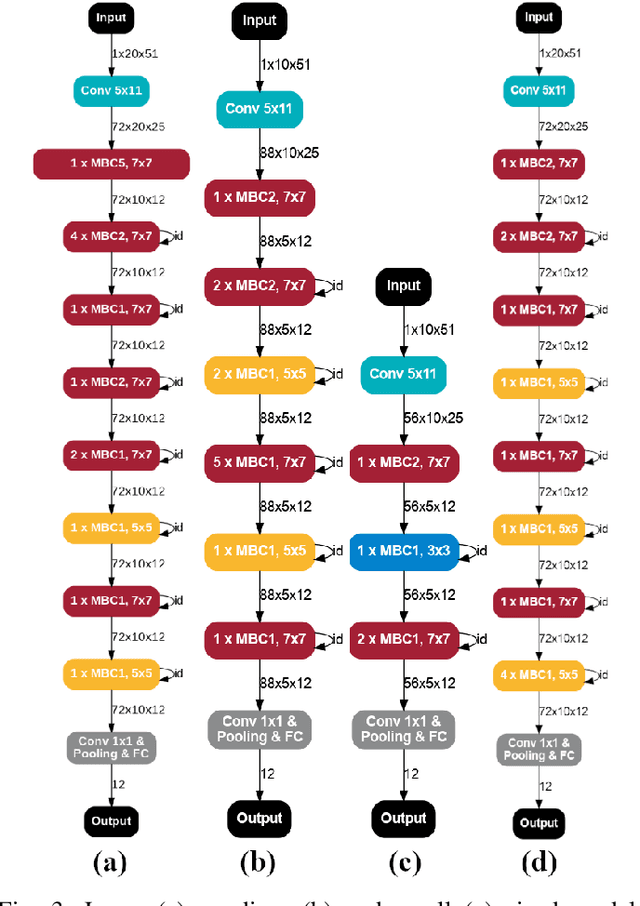
This paper introduces neural architecture search (NAS) for the automatic discovery of small models for keyword spotting (KWS) in limited resource environments. We employ a differentiable NAS approach to optimize the structure of convolutional neural networks (CNNs) to maximize the classification accuracy while minimizing the number of operations per inference. Using NAS only, we were able to obtain a highly efficient model with 95.4% accuracy on the Google speech commands dataset with 494.8 kB of memory usage and 19.6 million operations. Additionally, weight quantization is used to reduce the memory consumption even further. We show that weight quantization to low bit-widths (e.g. 1 bit) can be used without substantial loss in accuracy. By increasing the number of input features from 10 MFCC to 20 MFCC we were able to increase the accuracy to 96.3% at 340.1 kB of memory usage and 27.1 million operations.
Quantized Neural Networks for Radar Interference Mitigation
Dec 01, 2020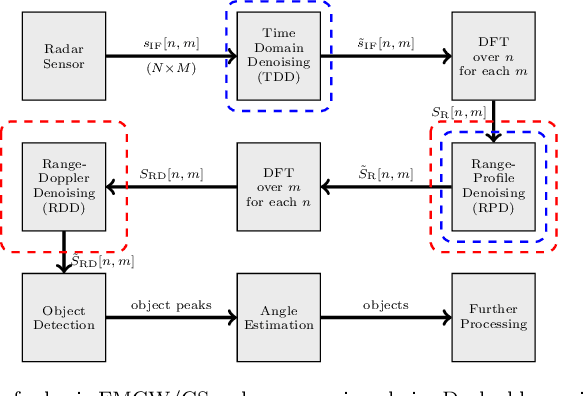
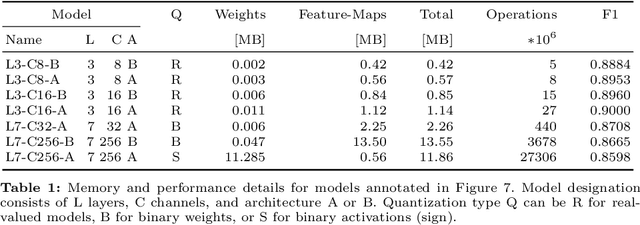
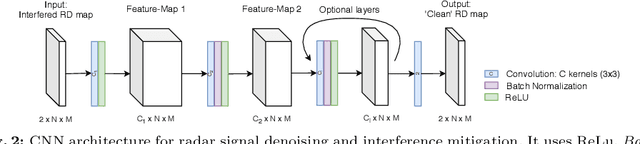
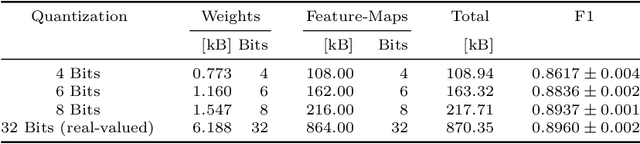
Radar sensors are crucial for environment perception of driver assistance systems as well as autonomous vehicles. Key performance factors are weather resistance and the possibility to directly measure velocity. With a rising number of radar sensors and the so far unregulated automotive radar frequency band, mutual interference is inevitable and must be dealt with. Algorithms and models operating on radar data in early processing stages are required to run directly on specialized hardware, i.e. the radar sensor. This specialized hardware typically has strict resource-constraints, i.e. a low memory capacity and low computational power. Convolutional Neural Network (CNN)-based approaches for denoising and interference mitigation yield promising results for radar processing in terms of performance. However, these models typically contain millions of parameters, stored in hundreds of megabytes of memory, and require additional memory during execution. In this paper we investigate quantization techniques for CNN-based denoising and interference mitigation of radar signals. We analyze the quantization potential of different CNN-based model architectures and sizes by considering (i) quantized weights and (ii) piecewise constant activation functions, which results in reduced memory requirements for model storage and during the inference step respectively.
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Oct 22, 2020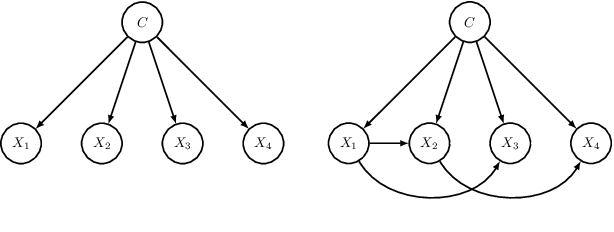
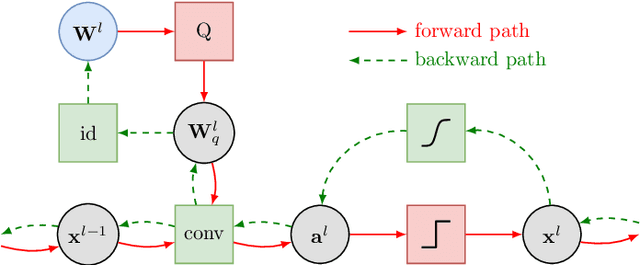
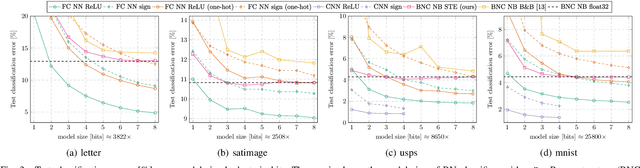
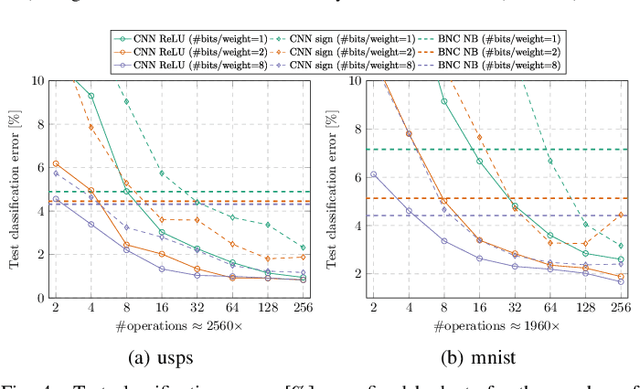
We present two methods to reduce the complexity of Bayesian network (BN) classifiers. First, we introduce quantization-aware training using the straight-through gradient estimator to quantize the parameters of BNs to few bits. Second, we extend a recently proposed differentiable tree-augmented naive Bayes (TAN) structure learning approach by also considering the model size. Both methods are motivated by recent developments in the deep learning community, and they provide effective means to trade off between model size and prediction accuracy, which is demonstrated in extensive experiments. Furthermore, we contrast quantized BN classifiers with quantized deep neural networks (DNNs) for small-scale scenarios which have hardly been investigated in the literature. We show Pareto optimal models with respect to model size, number of operations, and test error and find that both model classes are viable options.
Differentiable TAN Structure Learning for Bayesian Network Classifiers
Aug 21, 2020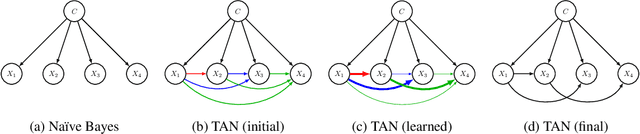
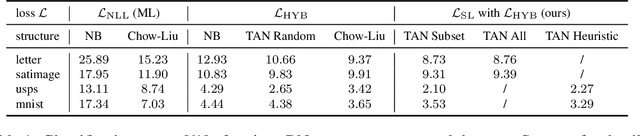
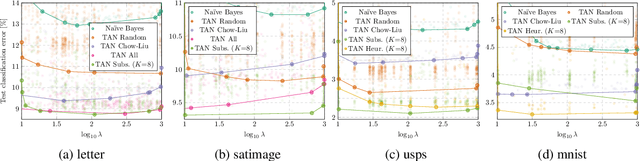
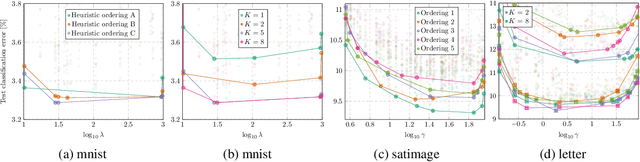
Learning the structure of Bayesian networks is a difficult combinatorial optimization problem. In this paper, we consider learning of tree-augmented naive Bayes (TAN) structures for Bayesian network classifiers with discrete input features. Instead of performing a combinatorial optimization over the space of possible graph structures, the proposed method learns a distribution over graph structures. After training, we select the most probable structure of this distribution. This allows for a joint training of the Bayesian network parameters along with its TAN structure using gradient-based optimization. The proposed method is agnostic to the specific loss and only requires that it is differentiable. We perform extensive experiments using a hybrid generative-discriminative loss based on the discriminative probabilistic margin. Our method consistently outperforms random TAN structures and Chow-Liu TAN structures.
Resource-Efficient Speech Mask Estimation for Multi-Channel Speech Enhancement
Jul 22, 2020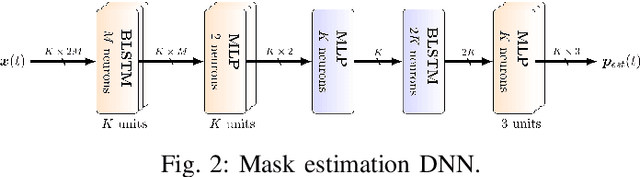
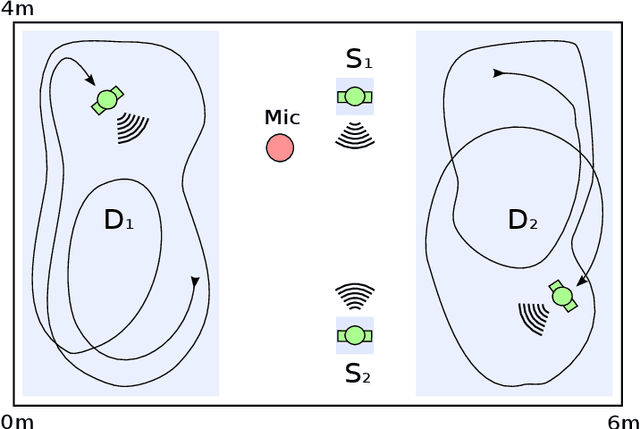
While machine learning techniques are traditionally resource intensive, we are currently witnessing an increased interest in hardware and energy efficient approaches. This need for resource-efficient machine learning is primarily driven by the demand for embedded systems and their usage in ubiquitous computing and IoT applications. In this article, we provide a resource-efficient approach for multi-channel speech enhancement based on Deep Neural Networks (DNNs). In particular, we use reduced-precision DNNs for estimating a speech mask from noisy, multi-channel microphone observations. This speech mask is used to obtain either the Minimum Variance Distortionless Response (MVDR) or Generalized Eigenvalue (GEV) beamformer. In the extreme case of binary weights and reduced precision activations, a significant reduction of execution time and memory footprint is possible while still obtaining an audio quality almost on par to single-precision DNNs and a slightly larger Word Error Rate (WER) for single speaker scenarios using the WSJ0 speech corpus.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020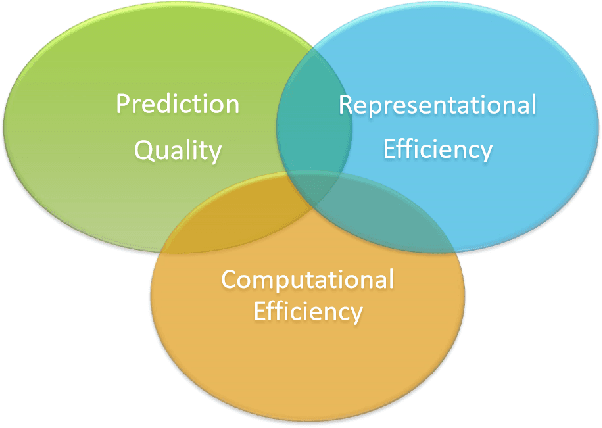
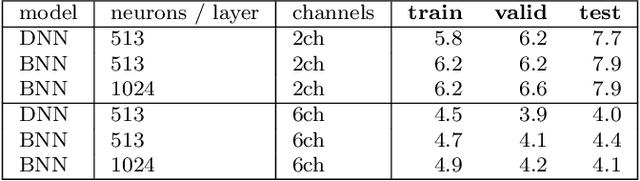
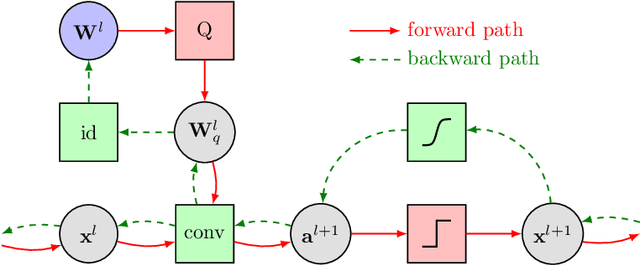
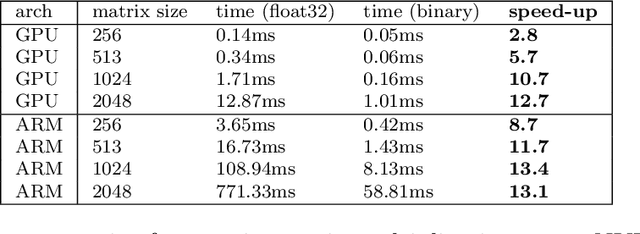
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.
Learning a Behavior Model of Hybrid Systems Through Combining Model-Based Testing and Machine Learning
Jul 10, 2019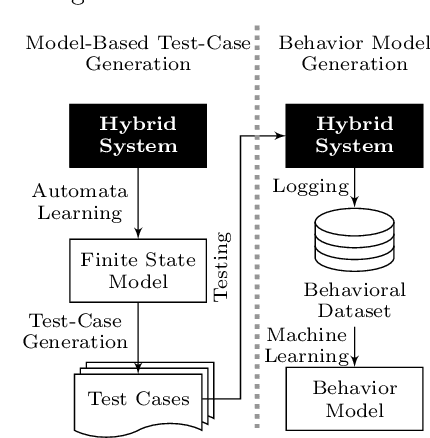
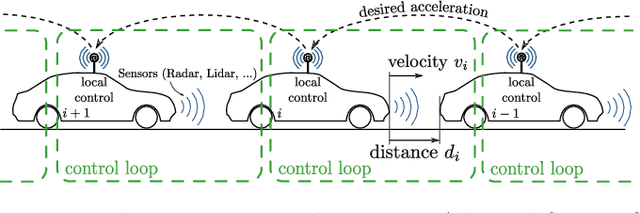
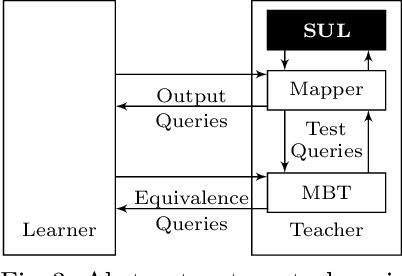
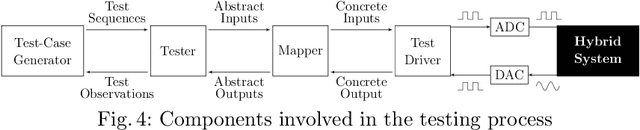
Models play an essential role in the design process of cyber-physical systems. They form the basis for simulation and analysis and help in identifying design problems as early as possible. However, the construction of models that comprise physical and digital behavior is challenging. Therefore, there is considerable interest in learning such hybrid behavior by means of machine learning which requires sufficient and representative training data covering the behavior of the physical system adequately. In this work, we exploit a combination of automata learning and model-based testing to generate sufficient training data fully automatically. Experimental results on a platooning scenario show that recurrent neural networks learned with this data achieved significantly better results compared to models learned from randomly generated data. In particular, the classification error for crash detection is reduced by a factor of five and a similar F1-score is obtained with up to three orders of magnitude fewer training samples.
Parameterized Structured Pruning for Deep Neural Networks
Jun 12, 2019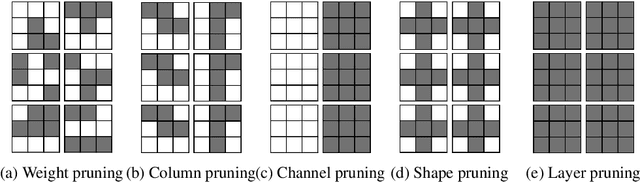

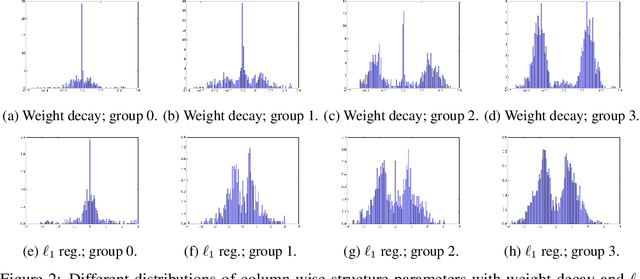
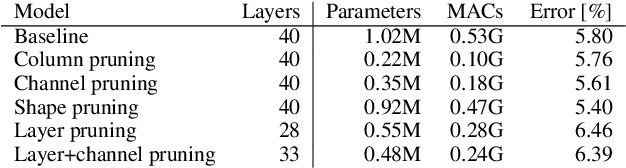
As a result of the growing size of Deep Neural Networks (DNNs), the gap to hardware capabilities in terms of memory and compute increases. To effectively compress DNNs, quantization and connection pruning are usually considered. However, unconstrained pruning usually leads to unstructured parallelism, which maps poorly to massively parallel processors, and substantially reduces the efficiency of general-purpose processors. Similar applies to quantization, which often requires dedicated hardware. We propose Parameterized Structured Pruning (PSP), a novel method to dynamically learn the shape of DNNs through structured sparsity. PSP parameterizes structures (e.g. channel- or layer-wise) in a weight tensor and leverages weight decay to learn a clear distinction between important and unimportant structures. As a result, PSP maintains prediction performance, creates a substantial amount of sparsity that is structured and, thus, easy and efficient to map to a variety of massively parallel processors, which are mandatory for utmost compute power and energy efficiency. PSP is experimentally validated on the popular CIFAR10/100 and ILSVRC2012 datasets using ResNet and DenseNet architectures, respectively.