 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
Paper and Code
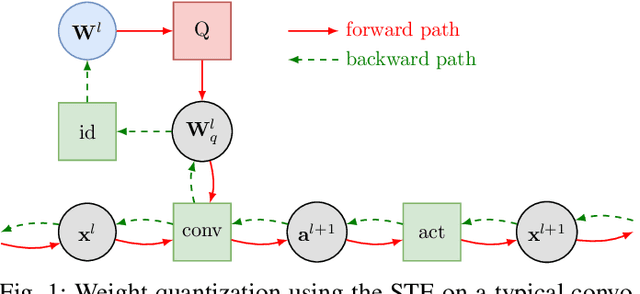
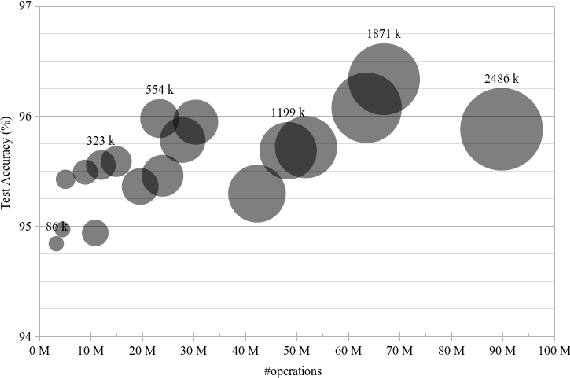
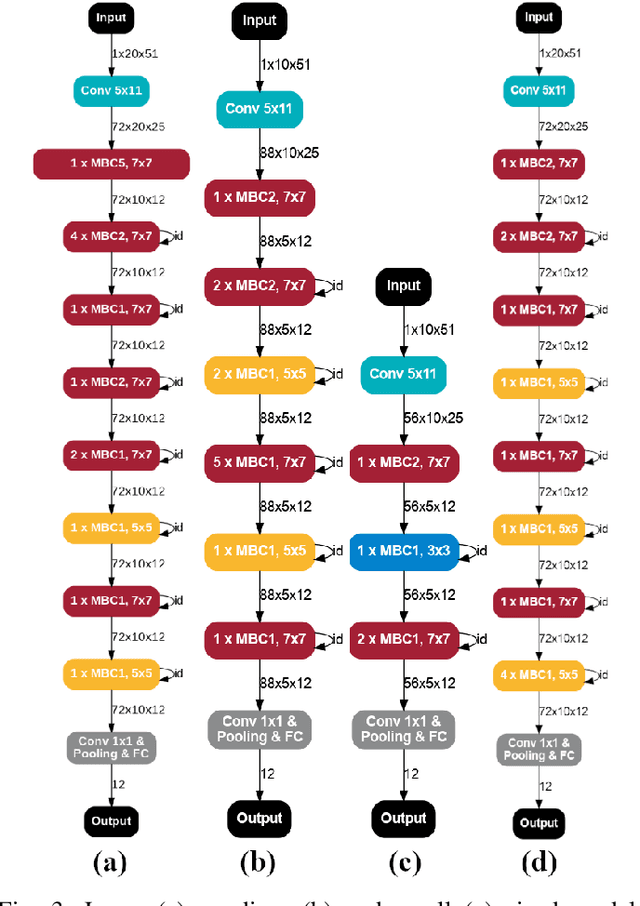
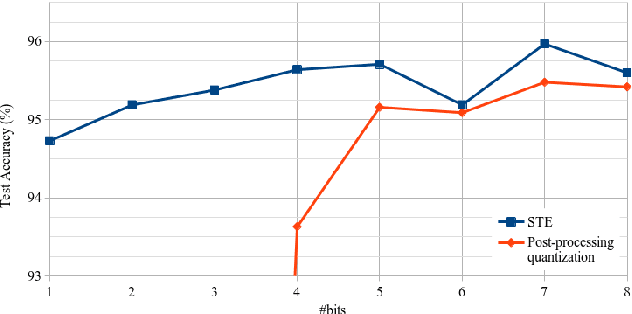
This paper introduces neural architecture search (NAS) for the automatic discovery of small models for keyword spotting (KWS) in limited resource environments. We employ a differentiable NAS approach to optimize the structure of convolutional neural networks (CNNs) to maximize the classification accuracy while minimizing the number of operations per inference. Using NAS only, we were able to obtain a highly efficient model with 95.4% accuracy on the Google speech commands dataset with 494.8 kB of memory usage and 19.6 million operations. Additionally, weight quantization is used to reduce the memory consumption even further. We show that weight quantization to low bit-widths (e.g. 1 bit) can be used without substantial loss in accuracy. By increasing the number of input features from 10 MFCC to 20 MFCC we were able to increase the accuracy to 96.3% at 340.1 kB of memory usage and 27.1 million operations.