 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Speech Separation and Dereverberation using Neural Beamforming
Mar 24, 2021
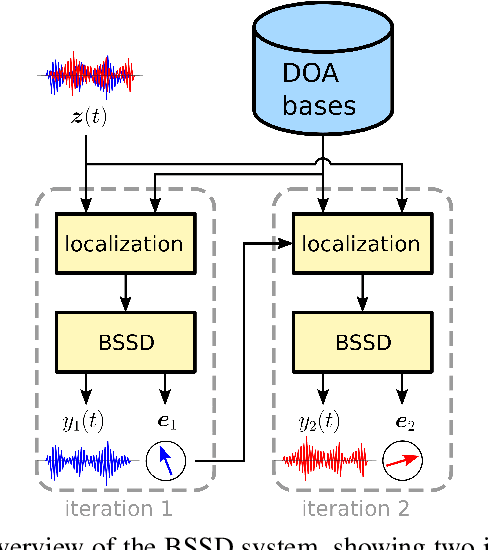
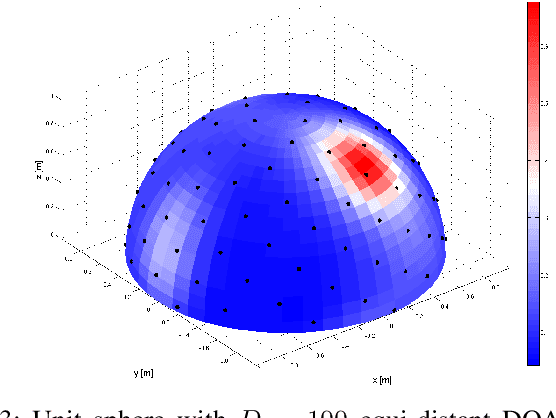
In this paper, we present the Blind Speech Separation and Dereverberation (BSSD) network, which performs simultaneous speaker separation, dereverberation and speaker identification in a single neural network. Speaker separation is guided by a set of predefined spatial cues. Dereverberation is performed by using neural beamforming, and speaker identification is aided by embedding vectors and triplet mining. We introduce a frequency-domain model which uses complex-valued neural networks, and a time-domain variant which performs beamforming in latent space. Further, we propose a block-online mode to process longer audio recordings, as they occur in meeting scenarios. We evaluate our system in terms of Scale Independent Signal to Distortion Ratio (SI-SDR), Word Error Rate (WER) and Equal Error Rate (EER).
Resource-Efficient Speech Mask Estimation for Multi-Channel Speech Enhancement
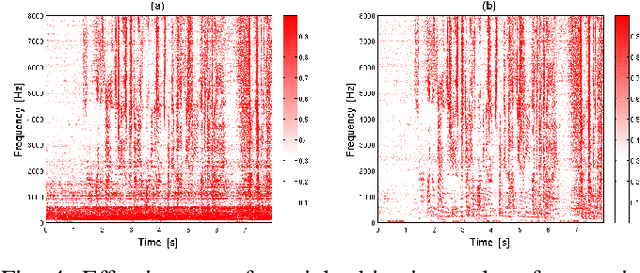
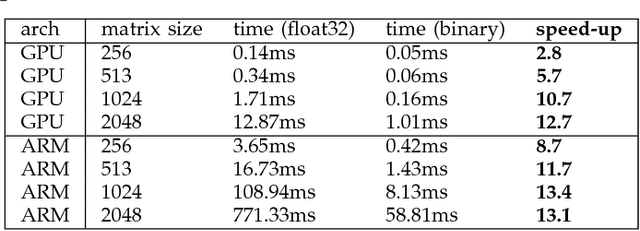
Jul 22, 2020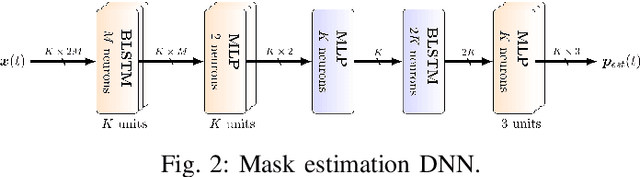
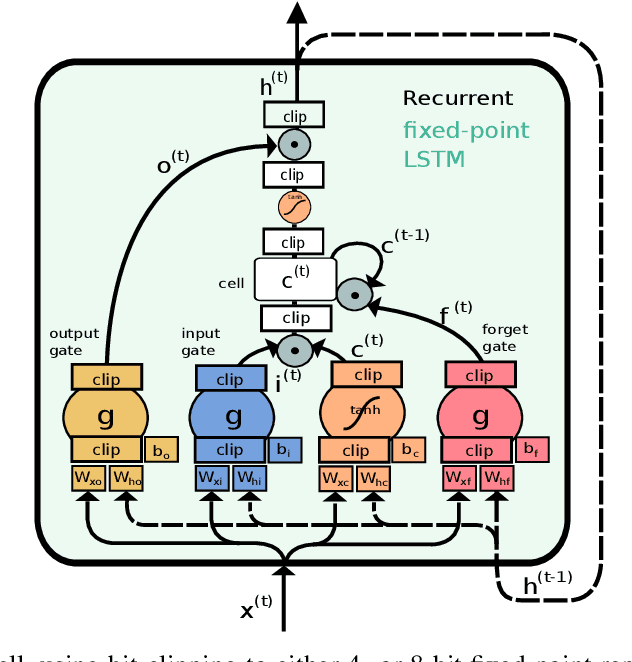
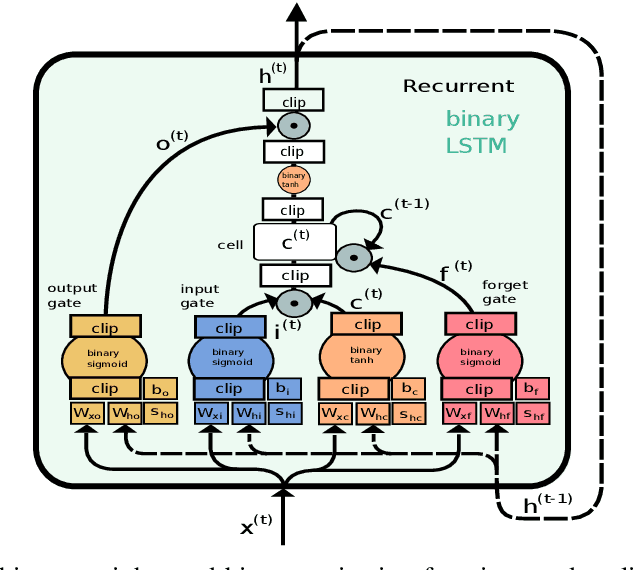
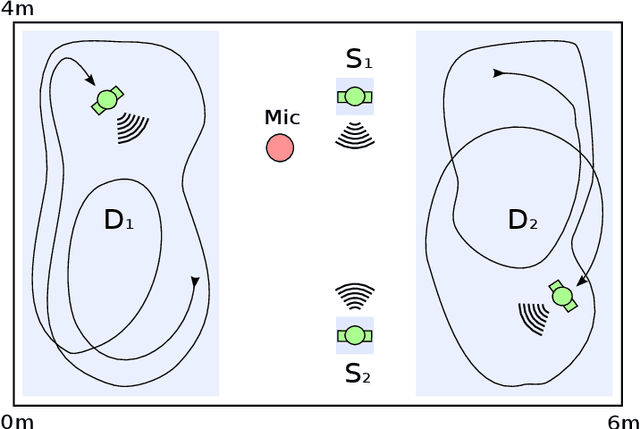
While machine learning techniques are traditionally resource intensive, we are currently witnessing an increased interest in hardware and energy efficient approaches. This need for resource-efficient machine learning is primarily driven by the demand for embedded systems and their usage in ubiquitous computing and IoT applications. In this article, we provide a resource-efficient approach for multi-channel speech enhancement based on Deep Neural Networks (DNNs). In particular, we use reduced-precision DNNs for estimating a speech mask from noisy, multi-channel microphone observations. This speech mask is used to obtain either the Minimum Variance Distortionless Response (MVDR) or Generalized Eigenvalue (GEV) beamformer. In the extreme case of binary weights and reduced precision activations, a significant reduction of execution time and memory footprint is possible while still obtaining an audio quality almost on par to single-precision DNNs and a slightly larger Word Error Rate (WER) for single speaker scenarios using the WSJ0 speech corpus.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020
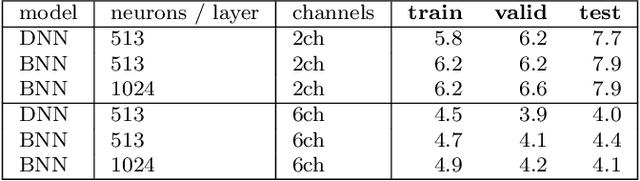
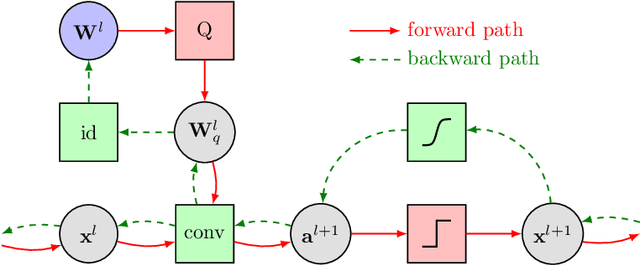
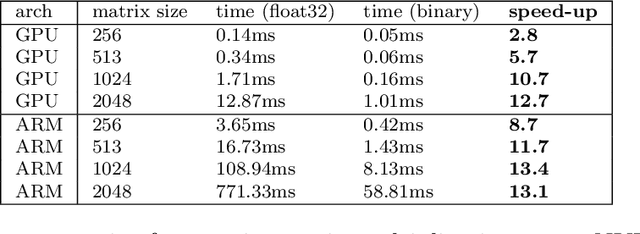
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018


While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.