 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabGemma: Text-Based Tabular ICL via LLM using Continued Pretraining and Retrieval
Nov 05, 2025We study LLMs for tabular prediction with mixed text, numeric, and categorical fields. We introduce TabGemma, a schema-agnostic in-context learner that treats rows as sequences and tackles two practical hurdles when adapting pretrained LLMs for tabular predictions: unstable numeric tokenization and limited context size. We propose to canonicalize numbers via signed scientific notation and continue pretraining of a 12B Gemma 3 model with a target imputation objective using a large-scale real world dataset. For inference, we use a compact n-gram-based retrieval to select informative exemplars that fit within a 128k-token window. On semantically rich benchmarks, TabGemma establishes a new state of the art on classification across low- and high-data regimes and improves monotonically with more context rows. For regression, it is competitive at small sample sizes but trails conventional approaches as data grows. Our results show that LLMs can be effective tabular in-context learners on highly semantic tasks when paired with dedicated numeric handling and context retrieval, while motivating further advances in numeric modeling and long-context scaling.
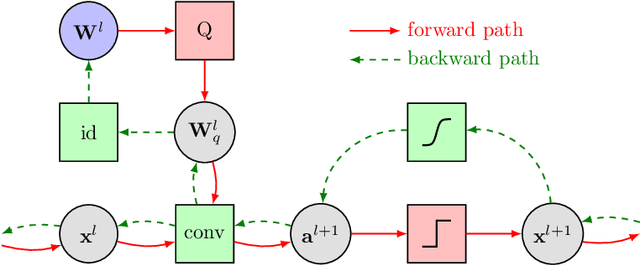
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Oct 22, 2020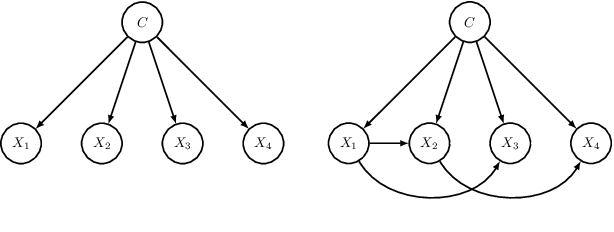
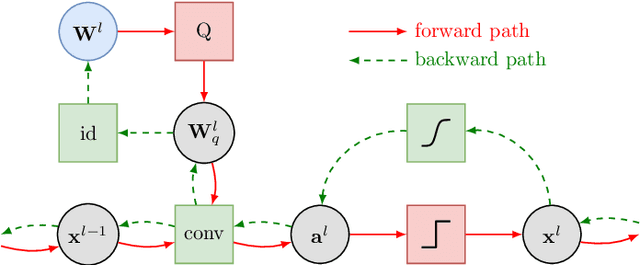
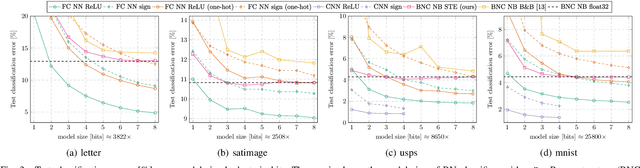
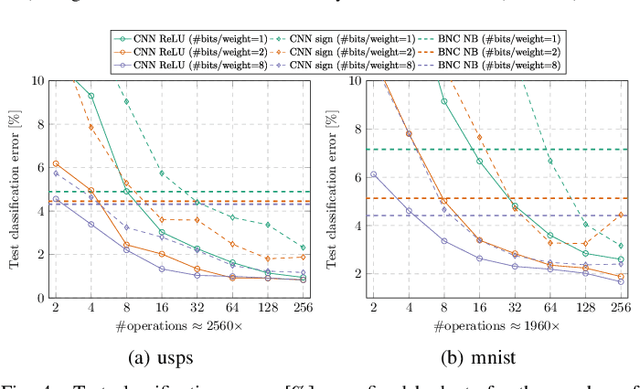
We present two methods to reduce the complexity of Bayesian network (BN) classifiers. First, we introduce quantization-aware training using the straight-through gradient estimator to quantize the parameters of BNs to few bits. Second, we extend a recently proposed differentiable tree-augmented naive Bayes (TAN) structure learning approach by also considering the model size. Both methods are motivated by recent developments in the deep learning community, and they provide effective means to trade off between model size and prediction accuracy, which is demonstrated in extensive experiments. Furthermore, we contrast quantized BN classifiers with quantized deep neural networks (DNNs) for small-scale scenarios which have hardly been investigated in the literature. We show Pareto optimal models with respect to model size, number of operations, and test error and find that both model classes are viable options.
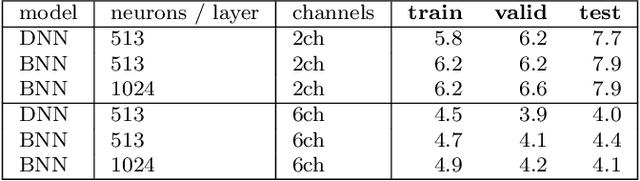
Resource-Efficient Speech Mask Estimation for Multi-Channel Speech Enhancement
Jul 22, 2020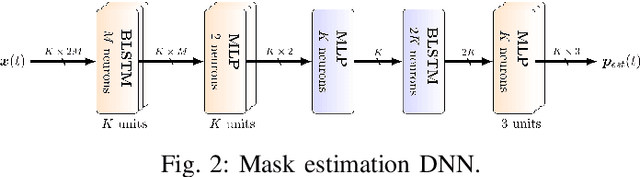
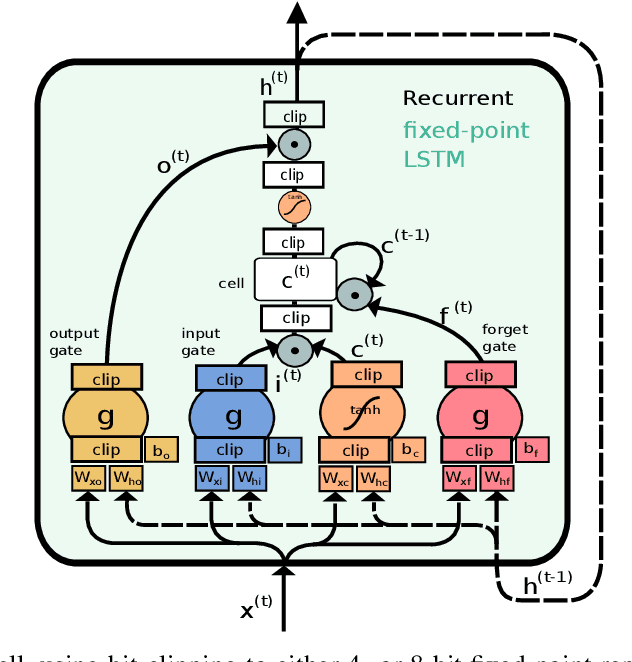
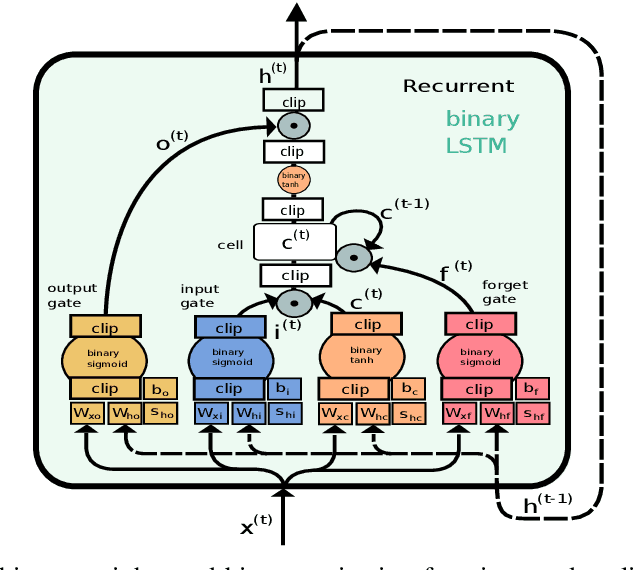
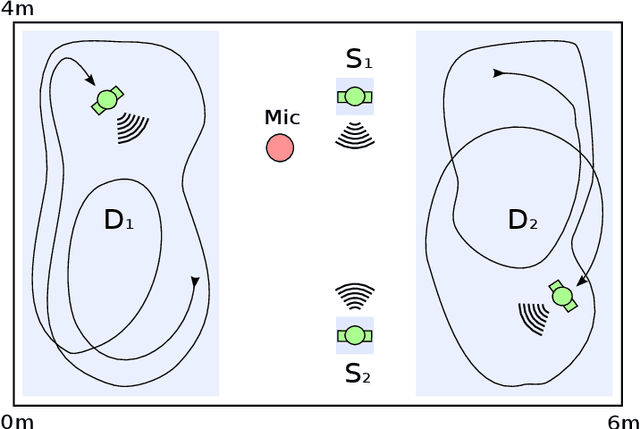
While machine learning techniques are traditionally resource intensive, we are currently witnessing an increased interest in hardware and energy efficient approaches. This need for resource-efficient machine learning is primarily driven by the demand for embedded systems and their usage in ubiquitous computing and IoT applications. In this article, we provide a resource-efficient approach for multi-channel speech enhancement based on Deep Neural Networks (DNNs). In particular, we use reduced-precision DNNs for estimating a speech mask from noisy, multi-channel microphone observations. This speech mask is used to obtain either the Minimum Variance Distortionless Response (MVDR) or Generalized Eigenvalue (GEV) beamformer. In the extreme case of binary weights and reduced precision activations, a significant reduction of execution time and memory footprint is possible while still obtaining an audio quality almost on par to single-precision DNNs and a slightly larger Word Error Rate (WER) for single speaker scenarios using the WSJ0 speech corpus.
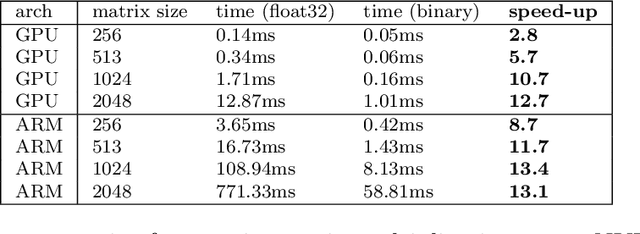
On the Difficulty of Designing Processor Arrays for Deep Neural Networks
Jun 24, 2020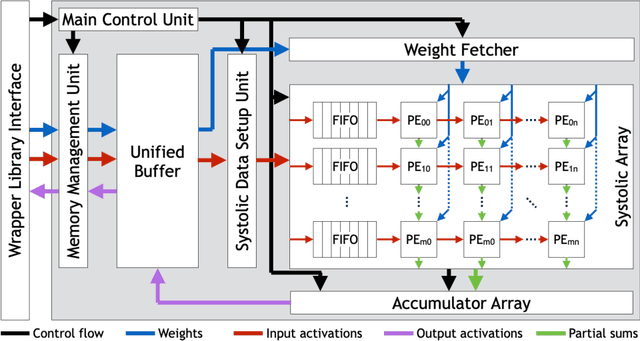
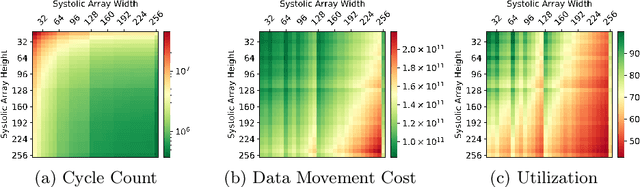
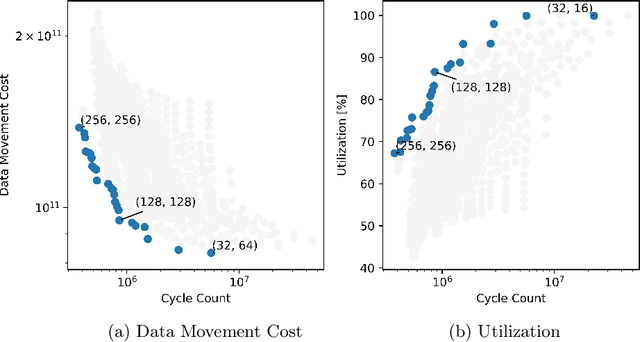
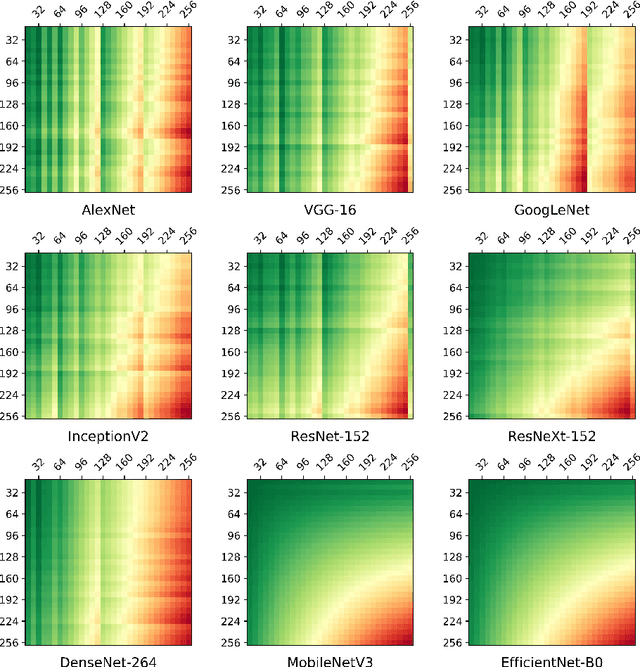
Systolic arrays are a promising computing concept which is in particular inline with CMOS technology trends and linear algebra operations found in the processing of artificial neural networks. The recent success of such deep learning methods in a wide set of applications has led to a variety of models, which albeit conceptual similar as based on convolutions and fully-connected layers, in detail show a huge diversity in operations due to a large design space: An operand's dimension varies substantially since it depends on design principles such as receptive field size, number of features, striding, dilating and grouping of features. Last, recent networks extent previously plain feedforward models by various connectivity, such as in ResNet or DenseNet. The problem of choosing an optimal systolic array configuration cannot be solved analytically, thus instead methods and tools are required that facilitate a fast and accurate reasoning about optimality in terms of total cycles, utilization, and amount of data movements. In this work we introduce Camuy, a lightweight model of a weight-stationary systolic array for linear algebra operations that allows quick explorations of different configurations, such as systolic array dimensions and input/output bitwidths. Camuy aids accelerator designers in either finding optimal configurations for a particular network architecture or for robust performance across a variety of network architectures. It offers simple integration into existing machine learning tool stacks (e.g TensorFlow) through custom operators. We present an analysis of popular DNN models to illustrate how it can estimate required cycles, data movement costs, as well as systolic array utilization, and show how the progress in network architecture design impacts the efficiency of inference on accelerators based on systolic arrays.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.