 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Structured Pruning for Deep Neural Networks
Jun 12, 2019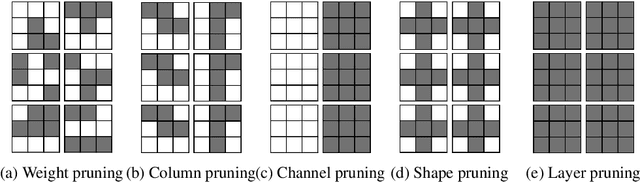

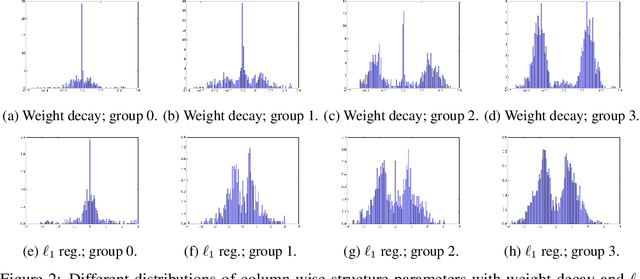
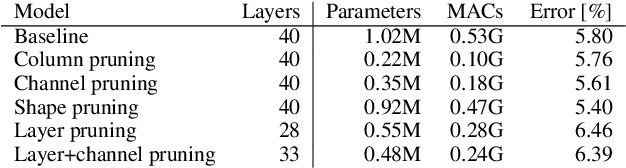
As a result of the growing size of Deep Neural Networks (DNNs), the gap to hardware capabilities in terms of memory and compute increases. To effectively compress DNNs, quantization and connection pruning are usually considered. However, unconstrained pruning usually leads to unstructured parallelism, which maps poorly to massively parallel processors, and substantially reduces the efficiency of general-purpose processors. Similar applies to quantization, which often requires dedicated hardware. We propose Parameterized Structured Pruning (PSP), a novel method to dynamically learn the shape of DNNs through structured sparsity. PSP parameterizes structures (e.g. channel- or layer-wise) in a weight tensor and leverages weight decay to learn a clear distinction between important and unimportant structures. As a result, PSP maintains prediction performance, creates a substantial amount of sparsity that is structured and, thus, easy and efficient to map to a variety of massively parallel processors, which are mandatory for utmost compute power and energy efficiency. PSP is experimentally validated on the popular CIFAR10/100 and ILSVRC2012 datasets using ResNet and DenseNet architectures, respectively.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018
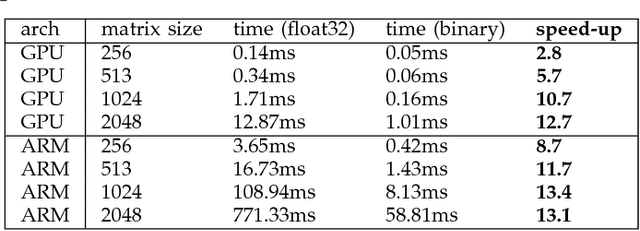


While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.