 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Speech Separation and Dereverberation using Neural Beamforming
Paper and Code

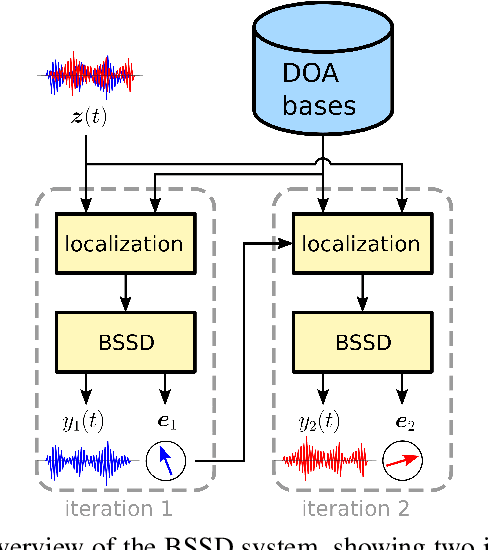
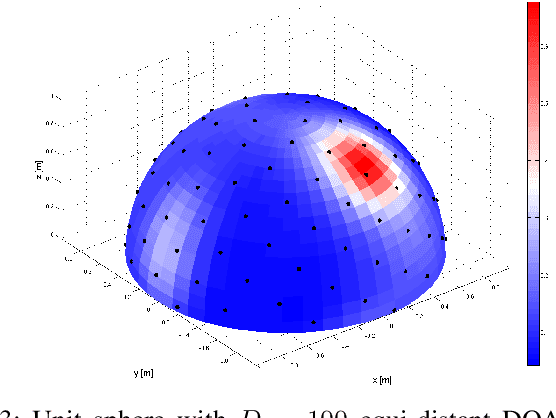
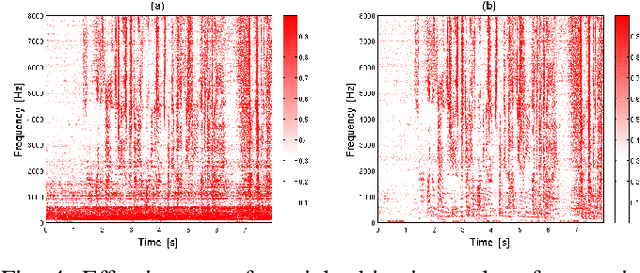
In this paper, we present the Blind Speech Separation and Dereverberation (BSSD) network, which performs simultaneous speaker separation, dereverberation and speaker identification in a single neural network. Speaker separation is guided by a set of predefined spatial cues. Dereverberation is performed by using neural beamforming, and speaker identification is aided by embedding vectors and triplet mining. We introduce a frequency-domain model which uses complex-valued neural networks, and a time-domain variant which performs beamforming in latent space. Further, we propose a block-online mode to process longer audio recordings, as they occur in meeting scenarios. We evaluate our system in terms of Scale Independent Signal to Distortion Ratio (SI-SDR), Word Error Rate (WER) and Equal Error Rate (EER).