 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning under Partial Observability Guided by Learned Environment Models
Jun 23, 2022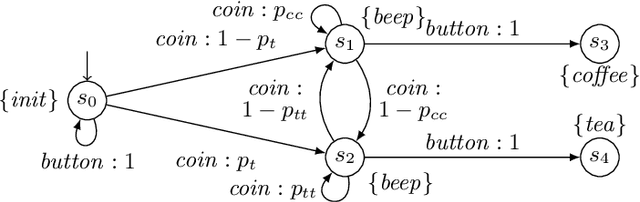
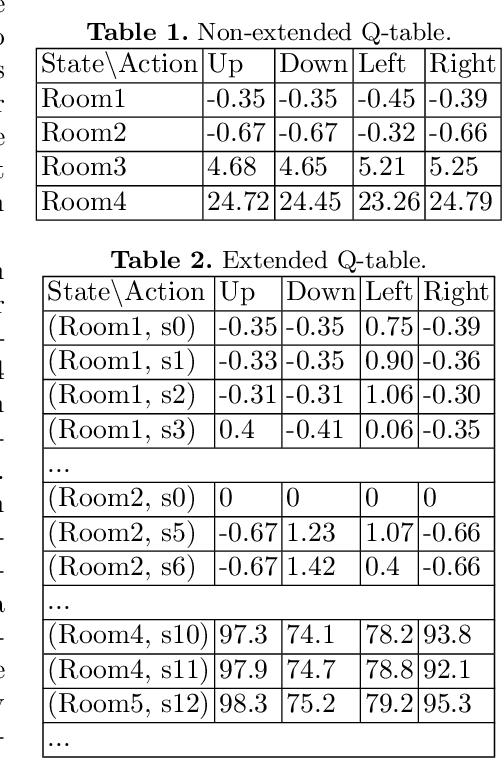
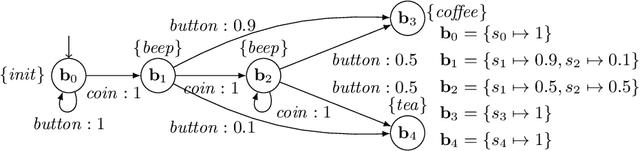
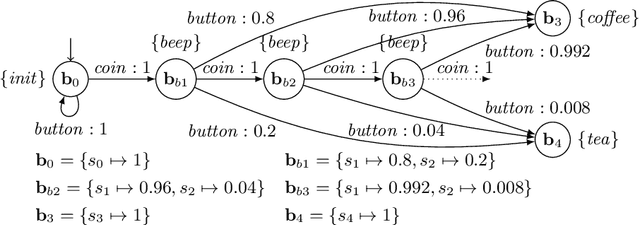
In practical applications, we can rarely assume full observability of a system's environment, despite such knowledge being important for determining a reactive control system's precise interaction with its environment. Therefore, we propose an approach for reinforcement learning (RL) in partially observable environments. While assuming that the environment behaves like a partially observable Markov decision process with known discrete actions, we assume no knowledge about its structure or transition probabilities. Our approach combines Q-learning with IoAlergia, a method for learning Markov decision processes (MDP). By learning MDP models of the environment from episodes of the RL agent, we enable RL in partially observable domains without explicit, additional memory to track previous interactions for dealing with ambiguities stemming from partial observability. We instead provide RL with additional observations in the form of abstract environment states by simulating new experiences on learned environment models to track the explored states. In our evaluation, we report on the validity of our approach and its promising performance in comparison to six state-of-the-art deep RL techniques with recurrent neural networks and fixed memory.