 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Shielding under Delayed Observation
Jul 05, 2023Agents operating in physical environments need to be able to handle delays in the input and output signals since neither data transmission nor sensing or actuating the environment are instantaneous. Shields are correct-by-construction runtime enforcers that guarantee safe execution by correcting any action that may cause a violation of a formal safety specification. Besides providing safety guarantees, shields should interfere minimally with the agent. Therefore, shields should pick the safe corrective actions in such a way that future interferences are most likely minimized. Current shielding approaches do not consider possible delays in the input signals in their safety analyses. In this paper, we address this issue. We propose synthesis algorithms to compute \emph{delay-resilient shields} that guarantee safety under worst-case assumptions on the delays of the input signals. We also introduce novel heuristics for deciding between multiple corrective actions, designed to minimize future shield interferences caused by delays. As a further contribution, we present the first integration of shields in a realistic driving simulator. We implemented our delayed shields in the driving simulator \textsc{Carla}. We shield potentially unsafe autonomous driving agents in different safety-critical scenarios and show the effect of delays on the safety analysis.
Online Shielding for Reinforcement Learning
Dec 04, 2022Besides the recent impressive results on reinforcement learning (RL), safety is still one of the major research challenges in RL. RL is a machine-learning approach to determine near-optimal policies in Markov decision processes (MDPs). In this paper, we consider the setting where the safety-relevant fragment of the MDP together with a temporal logic safety specification is given and many safety violations can be avoided by planning ahead a short time into the future. We propose an approach for online safety shielding of RL agents. During runtime, the shield analyses the safety of each available action. For any action, the shield computes the maximal probability to not violate the safety specification within the next $k$ steps when executing this action. Based on this probability and a given threshold, the shield decides whether to block an action from the agent. Existing offline shielding approaches compute exhaustively the safety of all state-action combinations ahead of time, resulting in huge computation times and large memory consumption. The intuition behind online shielding is to compute at runtime the set of all states that could be reached in the near future. For each of these states, the safety of all available actions is analysed and used for shielding as soon as one of the considered states is reached. Our approach is well suited for high-level planning problems where the time between decisions can be used for safety computations and it is sustainable for the agent to wait until these computations are finished. For our evaluation, we selected a 2-player version of the classical computer game SNAKE. The game represents a high-level planning problem that requires fast decisions and the multiplayer setting induces a large state space, which is computationally expensive to analyse exhaustively.
It's Time to Play Safe: Shield Synthesis for Timed Systems
Jun 30, 2020
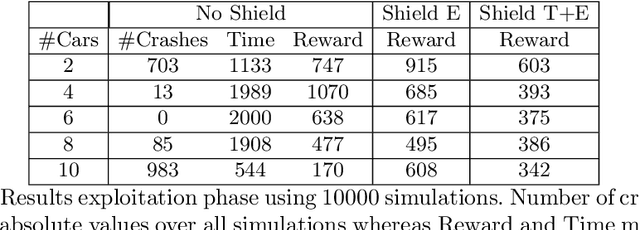
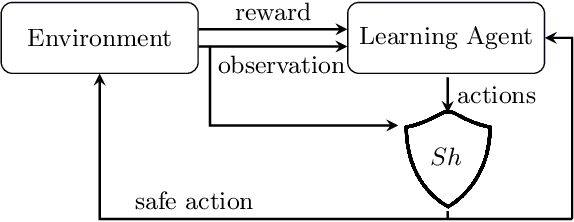
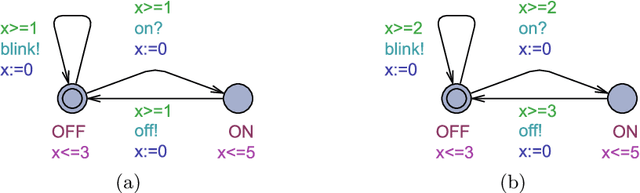
Erroneous behaviour in safety critical real-time systems may inflict serious consequences. In this paper, we show how to synthesize timed shields from timed safety properties given as timed automata. A timed shield enforces the safety of a running system while interfering with the system as little as possible. We present timed post-shields and timed pre-shields. A timed pre-shield is placed before the system and provides a set of safe outputs. This set restricts the choices of the system. A timed post-shield is implemented after the system. It monitors the system and corrects the system's output only if necessary. We further extend the timed post-shield construction to provide a guarantee on the recovery phase, i.e., the time between a specification violation and the point at which full control can be handed back to the system. In our experimental results, we use timed post-shields to ensure the safety in a reinforcement learning setting for controlling a platoon of cars, during the learning and execution phase, and study the effect.